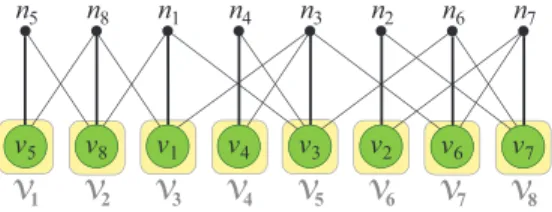
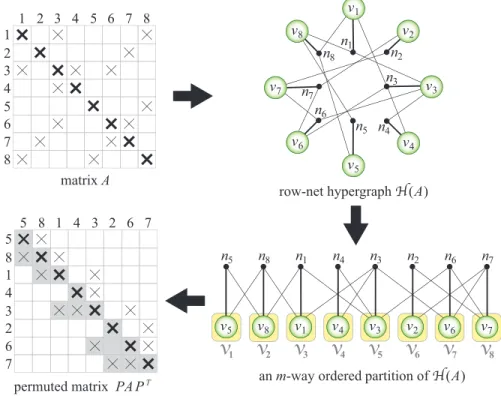
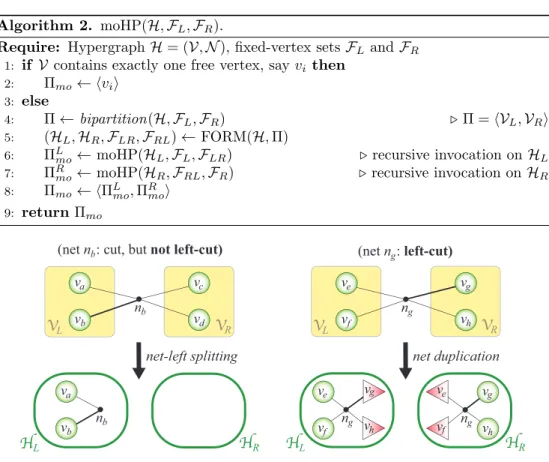
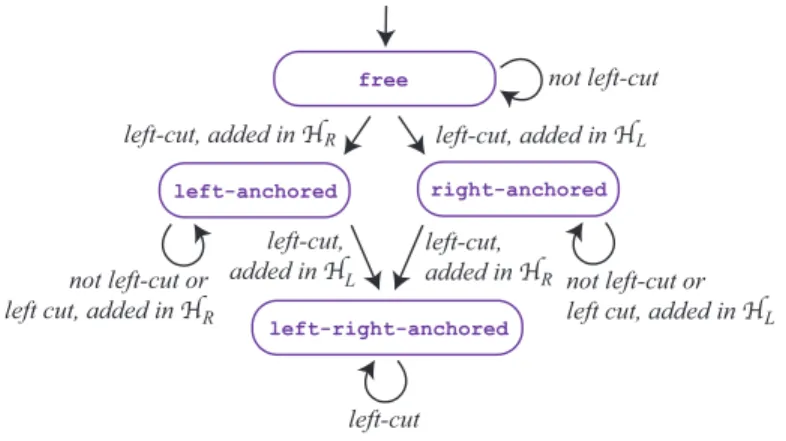
A hypergraph partitioning model for profile minimization
Tam metin
Şekil


Benzer Belgeler
Ve Türkiye'de týp bilimine yön verenin bilimsel baþarýlardan daha çok belirsizlik- ler, dünyanýn egemen bölgelerindeki araþtýrma trendleri ve bireysel çýkýþlar
Thus, integrating a course in the curriculum of design education that aims to explore futuristic and visionary oriented environments like Mars Colonies, Orbital Space Colonies
The positive and statistically significant coefficient of growth of total government expenditures shows that military spending is dependent on the limitations of government
Soz konusu düzeltmeler haricinde, Makedonya'nın AB üyeliği yolunda kaydettiği ilerlemenin ölçüleceği noktalardan birinin başında ‘’Yasalarının AB
Pompaj depolamalı hidroelektrik santrallerin kullanılması, puant yük elektrik fiyatının ve güvenilir olmayan enerji ar- zından dolayı oluşan kayıpların azalması
Moreover, the study investigated whether some differences among sexual awareness, sexual courage, and sexual self- disclosure and sexual embarrassment in terms of gender and
The aim of the present study was to compare the outcomes using cannulated screws and bioabsorbable pins for fixation after chevron osteotomy in the surgical treatment of hallux
number of coefficients by two at each level, so we are left with less number o f coefficients to manipulate. This leads to a coinputationally eficient object
