Cost-aware strategies for query result caching in Web search engines
Tam metin
Şekil


Benzer Belgeler
Ong’un “birincil sözlü kültür” konusundaki saptamaları ve Lord Raglan’ın “gele- neksel kahraman” ve mitik düzlem bağıntısına ilişkin görüşlerine dayanan
(c) Variation of Fermi energy level of graphene as a function of applied bias voltages for varying Ltf/C 18 E 10 mole ratio in LLC gel electrolytes and typical ionic liquid used
(a) Cross-section of an isosceles triangular cylinder (prism) of the rela- tive dielectric permittivity ε, the base a, and the height b, with rounded edges (see text for
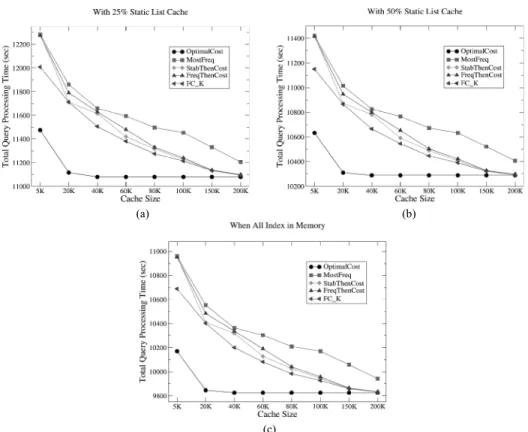
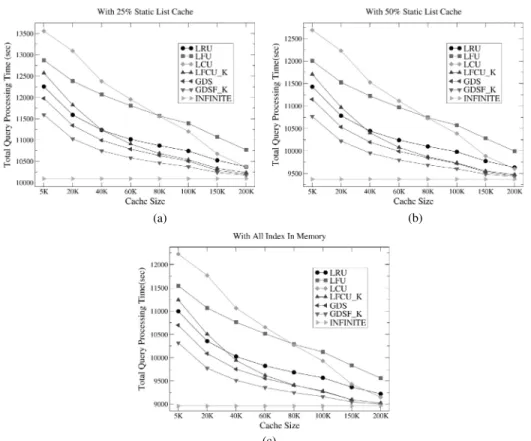
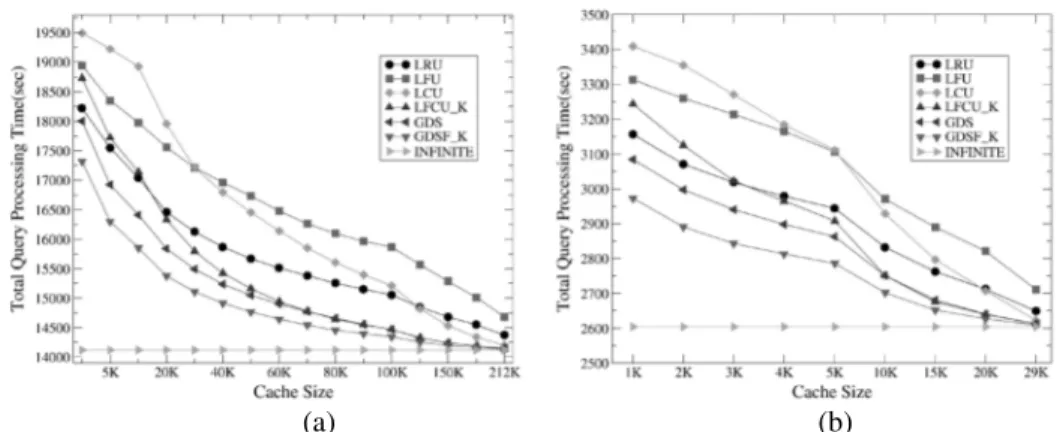
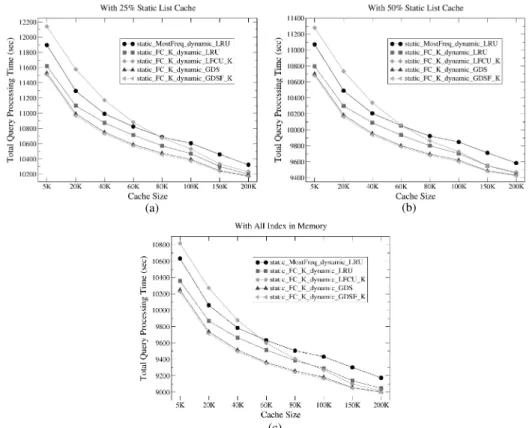
Bu nedenle k açısından bu çalışmada her iki Deney boyunca sistemin b (average precision) değerine grafiklerde x ekseni arama gösterilen resim sayısını, y ek
EU-Turkey relations improved in the early 2000s, a new thread of Turkish nationalism emerged, a paradoxical mix of Kemalism and anti-Westernism that found support in military
Similarly, to solve the design problems with required ring structure in the backbone network (i.e., ring/ 2EC and ring/ring) we add constraints (13).. Cutting
Bilkent University, Faculty of Art, Design & Architecture, 06800 Bilkent, Ankara, Turkey This study investigates the interaction of women’s gendered identities and performances
This protocol provides information about preparation and characterization of self-assembled peptide nanofiber scaffolds, culturing of neural stem cells (NSCs) on these scaffolds,
