Classification of Text Documents based on Naive
Bayes using N-Gram Features
Mehmet BAYGIN Computer Engineering Department
Ardahan University 75000, Ardahan, Turkey [email protected] Abstract— Document classification is basically the process of
categorizing documents in certain categories correctly. This process, which is usually used in the field of text mining, automatically classifies documents with large dimensions. In this paper, Turkish document classification was performed by using Naïve Bayes approach which is one of the machine learning methods. With this approach, which basically uses 5 different categories, Turkish documents are classified quickly and automatically. In addition, the performance of the proposed approach was measured according to the basic evaluation criteria of precision, recall, accuracy and f-measure, and achieved a success rate of 92%. Also, the source codes of the application developed in this paper are presented as open source at https://drive.google.com/open?id=1Idp5VK1Q91vyqb940WjeoM pB9dVQuVC9.
Index Terms—Naïve Bayes, machine learning, document classification.
I. INTRODUCTION
Today, with the widespread use of the internet, data sharing has also increased in a right proportion. In addition, parallel to this increase in usage, the move of many documents to the internet enables the documents to be analyzed and information can be extracted from these documents [1]. In order to be able to analyze on documents and to be able to extract information as a result of these analyzes, it is necessary to classify documents first [2]. In addition, it is very important that these operations are carried out very quickly, automatically and correctly.
Text and document classification processes are often used in areas such as sentiment analysis, text summarization [3]. Documents need to be clustered and categorized in quite successfully so that the work done in these areas can be successfully completed [4, 5]. There are many studies related to text and document classification in the literature [6, 7]. In one of these studies, sentiment analysis was performed on data received via Twitter, one of the social media platforms. For this purpose, comments made by customers on a product group are classified by using Naïve Bayes, maximum entropy and support vector machines. The proposed approach has achieved 87% performance and the user comments are classified in three categories as positive, negative and moderate. A flowchart diagram of this approach proposed in the literature is presented in Fig. 1 [8]. Dataset Preprocessing to Dataset Training Dataset Feature Extraction Classify with Machine Learning Show Sentiment Analysis Results Semantic Analysis Input Sentences 1 2 3
Fig. 1. An example study from literature [8]
In another study on the subject, the extraction of semantic meanings of texts was performed. For this purpose, two different datasets were used in the study and weighted word vectors were obtained according to the TF-IDF algorithm of the words. The vectors obtained at the last part of the study were given as input to the Convolutional Neural Network and the features of the texts were automatically extracted. The datasets have been classified with a success rate of 96% with the proposed approach in this paper [9]. In another study, classification of texts written in handwriting was performed. For this purpose, optical character recognition is used primarily and the process of transferring the scanned texts to the computer environment is provided. At the next step of the study, classification of texts was performed by using support vector machines [10]. In a study on Twitter, an analysis of the comments made by the customers for an important food brand was performed. In this approach using the K-means method, tweets are divided into two groups as positive and negative [11]. In another study on the subject, performance and success rate of Naïve Bayes classification algorithm were investigated. In this study, predefined categories such as economy, health and life were subjected to automatic classification process and Apache Large Data Technologies
were used in application. [12]. The preprocessing steps in text and document classification have a quite large significance for correct classification. In a study performed for this purpose, the effects of preprocessing steps on text classification were examined. The study used mainly Turkish and English languages and all possible combinations of commonly used pre-processing steps were taken into account comparatively. As a result of the experimental studies performed, possible combinations that could increase the classification accuracy were determined [13]. In this paper, Naïve Bayesian document classification was performed. In the classifications of Turkish documents, news belonging to 5 different categories (economy, politics, sports, magazine, health) are divided into training and test set and classified very effectively. In addition, the precision, recall, accuracy and f-measure values of the proposed approach are calculated and the performance of the method is verified. In the second section of the study, details of the proposed method are presented. In the third part of the study, the experimental results obtained as a result of the proposed approach are shared, while the conclusions are given in the fourth and last section.
II. PROPOSED APPROACH
Machine learning methods are actively used in many different areas. One of these areas is text mining [14]. Especially with these approaches aiming to extract information from specific documents, the documents are automatically divided into categories and then the information is extracted from these documents [15]. With this information, information such as behavior of the users, sentiment analysis and brand sense can be measured rapidly. Particularly nowadays, the spread of social media, the increased sharing of information and the publication of many documents online make these analyzes even easier.
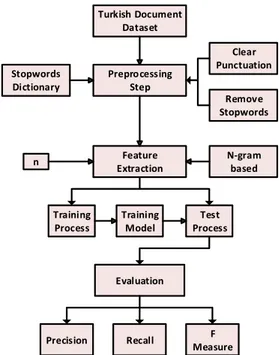
In this study, classification of documents obtained by using Naïve Bayes algorithm which is one of the machine learning methods is provided. These documents, which compiled economic, health, sports, political and magazine news, were primarily subjected to specific pre-processing steps and then trained. The model obtained from the training process was used in the testing process and very successful results were obtained. A block diagram that summarizes this method of classifying and analyzing Turkish documents is as shown in Fig. 2.
A. Preprocessing
The most important step directly affecting the performance of machine learning methods is preprocessing steps. This part, which has an important place in many machine learning methods, is an approach that contributes positively to the performance of the system and increases the efficiency. Pre-processing steps have also been carried out in this paper and certain cleaning operations have been performed on the documents. Firstly, the stop words that are used frequently in texts have been cleared. After this step, the punctuation marks have been cleared. An example of pre-processing steps used in Naive Bayesian approach is given in Table 1.
Turkish Document Dataset Preprocessing Step Stopwords Dictionary Feature Extraction Clear Punctuation Remove Stopwords N-gram based n Training Process Test Process Training Model Evaluation
Precision Recall MeasureF
Fig. 2. A flowchart of the proposed approach
TABLE I. AN EXAMPLE OF PREPROCESSING STEP
Methods Results
An example sentence
“Petrol, kömür ve doğalgaz gibi fosil enerjilerin, sera gazı etkisi yaratması gibi tehlikeleri vurgulanarak, Türkiye'nin yenilenebilir enerji konusunda gerekli kaynakları olduğu söyleniyor.”
1-Punctuation Removing
Petrol kömür ve doğalgaz gibi fosil enerjilerin sera gazı etkisi yaratması gibi tehlikeleri vurgulanarak Türkiyenin yenilenebilir enerji konusunda gerekli kaynakları olduğu söyleniyor 2-Stopwords Removing
Petrol kömür doğalgaz fosil enerjilerin sera gazı etkisi yaratması tehlikeleri vurgulanarak Türkiyenin yenilenebilir enerji konusunda gerekli kaynakları olduğu söyleniyor
3-Case Conversion
petrol kömür doğalgaz fosil enerjilerin sera gazı etkisi yaratması tehlikeleri vurgulanarak türkiyenin yenilenebilir enerji konusunda gerekli kaynakları olduğu söyleniyor
B. Feature Extraction
The next step of the proposed approach within the context of the study is feature extraction. Feature extraction is basically a process of identifying and separating distinctive features from a text. In this paper, the n-gram based feature extraction process is applied to the documents. An example of these operations, in which basically 2, 3 and 4 grams are extracted, is as shown in Table 2.
TABLE II. FEATURE EXTRACTION STEP
Features Results
An example words yenilenebilir enerji
2-gram ye, en (3), ni, il (2), le, ne (2), eb, bi, li, ir, r_, _e, er, rj, ji 3-gram yen, eni, nil, ile, len, ene (2), neb, ebi, bil, ili, lir, ir_, r_e, _en, ner, erj, rji 4-gram yeni, enil, nile, ilen, lene, eneb, nebi, ebil, bili, ilir, lir_ir_e, r_en, _ene, ener, nerj, erji
C. Training and Test Process
The next step in machine learning approaches is to train and test the system. The dataset obtained for this purpose is divided into training and test set. In this study, news collected in 5 different categories (economy, health, politics, sports, magazines) are separated into training and test sets. In the study, 75% of the data set was used for training, 25% was used for testing and a total of 1150 news documents were used. The dataset used in the study is taken from [16]. A table showing the number of training and test sets according to the categories of these documents is presented in Table 3.
TABLE III. DISTRIBUTION OF DOCUMENTS
*Categories Number of Document Number of Training Dataset Number of Test Dataset Economy 230 173 57 Magazines 230 172 58 Health 230 173 57 Politics 230 172 58 Sports 230 172 58 Total 1150 862 288 *http://www.kemik.yildiz.edu.tr/data/File/1150haber.rar D. Evaluation
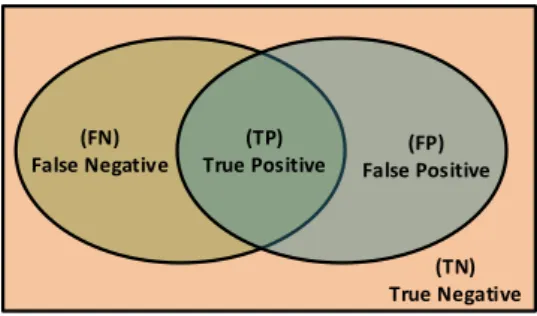
In order to evaluate the Naïve Bayesian based document classification method proposed in the study, precision, recall, accuracy and f-measure values were calculated frequently used in the literature. In particular, the calculation of these measurement parameters used in data extraction is as given in Fig. 3, Table 4, Equations 1, 2, 3 and 4, respectively.
(FN) False Negative
(TP)
True Positive False Positive(FP)
(TN) True Negative Fig. 3. The set of evaluation parameters
TABLE IV. CLASSIFICATION EVALUATION PARAMETERS
System’s Prediction Correct Classification TP FP FN TN No No 0 0 0 1 No Yes 0 0 1 0 Yes No 0 1 0 0 Yes Yes 1 0 0 0 𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 = 𝑇𝑃 𝑇𝑃 + 𝐹𝑃 (1) 𝑅𝑒𝑐𝑎𝑙𝑙 = 𝑇𝑃 𝑇𝑃 + 𝐹𝑁 (2) 𝐴𝑐𝑐𝑢𝑟𝑎𝑐𝑦 = 𝑇𝑃 + 𝑇𝑁 𝑇𝑃 + 𝐹𝑃 + 𝐹𝑁 + 𝑇𝑁 (3) 𝐹 − 𝑀𝑒𝑎𝑠𝑢𝑟𝑒 =2𝑥𝑅𝑒𝑐𝑎𝑙𝑙𝑥𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 𝑅𝑒𝑐𝑎𝑙𝑙 + 𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 (4)
TP, TN, FP and FN values given in the equations are calculated for each document and the value of this field in the table is increased one by one. In other words, for example, if the system predicts the category for a document and the document's known true category is the same, the TP field in the table is increased by one. This process is performed for all the documents in the test set and is obtained a table of certain numeric values. The values of precision, recall, accuracy and f-measure are calculated using these values where necessary in the equation.
III. EXPERIMENTAL RESULTS
In this paper, classification of Turkish documents was performed by using Naïve Bayes approach which is one of the machine learning methods. The performance of the proposed method is tested on a real data set. These tests were performed on a computer with Intel Core i5, 4 gb ram and windows 10 operating system. Also, the proposed algorithm was implemented on the JAVA platform.
A total of 1150 documents were used in the scope of the study. These documents are in 5 different categories. Preprocessing steps were applied to the dataset, the stop words and punctuation marks were cleared from the dataset. At the next stage of the study, user defined n-gram feature extraction for each document was performed. At this stage, the n-gram values obtained from the documents are stored in memory using a hash table. These values have been saved as a text file for later use. The main reason for performing this process is to constantly prevent the repetition of the training process. In the third phase of the study, n-grams were divided into two groups, 75% of which were training and 25% were test groups. The Naïve Bayes method was applied to the training group and a training model was obtained. At the end of the study, the test set is given as an input to training model and the classification results are evaluated according to certain parameters. Within the scope of the study, the 2-gram, 3-gram and 4-gram features of all documents were extracted and the test procedures were performed separately for each feature. A user-defined threshold value is used during the extraction of these features. The reason for this operation is to prevent the processing of the n-grams which are less than the certain threshold value. This user-defined value is set at 50, and the number of keywords used for n-grams is given in Table 5. Also, the set of evaluation parameters obtained as a result of these test procedures is presented in Table 6 according to categories for all n-grams.
TABLE V. THE NUMBER OF KEYWORDS
Features Values
2-gram 689 3-gram 3531 4-gram 7257
TABLE VI. THE SET OF EVALUATION PARAMETERS
Economy Magazine Health Politic Sport
2-gram TP 53 48 29 38 56 FP 30 15 1 0 18 FN 5 9 29 19 2 TN 200 216 229 231 212 3-gram TP 56 54 50 52 50 FP 15 4 2 4 1 FN 2 3 8 5 8 TN 215 227 228 227 229 4-gram TP 56 49 46 34 25 FP 67 3 2 6 0 FN 2 8 12 23 33 TN 163 228 228 225 230
As can be seen from Table 6, the sum of TP, FP, FN and TN for each category and n-gram equals the number of documents divided for the total test. The calculated precision, recall, accuracy and f-measure values as a result of these obtained values are presented in Table 7 for each category.
TABLE VII. EXPERIMENTAL RESULTS
Economy Magazine Health Politic Sport
2-gram Precision 0.64 0.76 0.97 1.0 0.77 Recall 0.91 0.84 0.5 0.67 0.97 Accuracy 0.88 0.92 0.9 0.93 0.93 F-measure 0.75 0.8 0.66 0.8 0.85 3-gram Precision 0.79 0.93 0.96 0.93 0.98 Recall 0.97 0.95 0.86 0.91 0.86 Accuracy 0.94 0.98 0.97 0.97 0.97 F-measure 0.86 0.94 0.91 0.92 0.92 4-gram Precision 0.46 0.94 0.96 0.85 1.0 Recall 0.97 0.86 0.79 0.60 0.43 Accuracy 0.76 0.96 0.95 0.90 0.89 F-measure 0.62 0.90 0.87 0.70 0.60
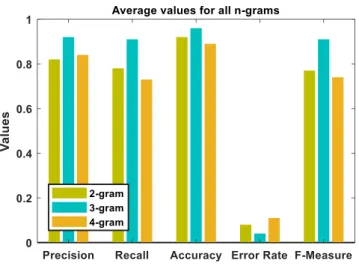
As mentioned at the beginning of the chapter, n-gram technique has been utilized in the feature extraction phase of the classification process. At this stage, the 2-gram, 3-gram and 4-gram features of the documents were obtained and used in both the training and the test phase. Documents are classified in the test process using these features. After the completion of the test, the precision, recall, accuracy and f-measure values, which are important evaluation parameters in the data mining, are calculated. As can be seen from Table 7, the calculated values are determined separately for each document category and n-gram. A table showing the averages of these calculated values is given in Table 8. A graph of the variation of these values is also presented in Fig. 4.
TABLE VIII. AVERAGE RESULTS FOR ALL DOCUMENTS
Average values for all documents 2-gram 3-gram 4-gram Precision 0.82 0.92 0.84
Recall 0.78 0.91 0.73
Accuracy 0.92 0.96 0.89
Error rate 0.08 0.04 0.11
F-measure 0.77 0.91 0.74
Fig. 4. The results of evaluation parameters
A total of 288 documents in 5 different categories were classified by using Naïve Bayes based document classification method. In this study, which is basically evaluated for 3 different n-grams, a total of 92% success has been achieved, which is seen on the axis of accuracy of the graph shown in Fig. 4.
As can be seen from Fig. 4, the best performance is obtained for 3-grams and the performance of the proposed approach drops as n-gram value grows. Furthermore, in the tests performed, it was observed that the calculation time increased as the n-gram value increased. This is mainly due to the increase in the number of keywords used. This situation can be seen from Table 5. In this study, the most optimal value in terms of time and performance was obtained for 3-gram. Also, as can be seen from Fig. 4, the best precision, recall, accuracy and f-measure values are obtained for 3-gram and the lowest error rate is obtained for this n-gram.
IV. CONCLUSIONS
Today, with the increasing use of the Internet, many documents have been moved to the internet and opened to the public. However, the fact that these documents are not usually categorized greatly restricts the ability of users to access and search for information.
In this study, text and document classification was performed using the Naïve Bayesian approach, one of the machine learning methods. A total of 1150 documents were used for the classification process and the n-gram feature extraction method was used. Turkish documents were used during the training and testing phase and the performance of the classification process was evaluated by calculating the values of precision, recall, accuracy and f-measure.
The proposed approach has been tested on a real data set and achieved a performance of about 92%. When the results obtained from the test procedures are examined, it has been observed that the approach proposed within the scope of the study is highly efficient and classifies the documents with great accuracy.
REFERENCES
[1] L. Jiang, C. Li, S. Wang, and L. Zhang, “Deep feature weighting for naive Bayes and its application to text classification,” Engineering Applications of Artificial Intelligence, vol. 52, pp. 26-39, 2016.
[2] G. Feng, J. Guo, B. Y. Jing, and T. Sun, “Feature subset selection using naive Bayes for text classification,” Pattern Recognition Letters, vol. 65, pp. 109-115, 2015.
[3] X. Zhang, J. Zhao, and Y. LeCun, “Character-level convolutional networks for text classification,” In Advances in neural information processing systems, pp. 649-657, 2015.
[4] P. Liu, H. Yu, T. Xu, and C. Lan, “Research on archives text classification based on Naive Bayes,” In Technology, Networking, Electronic and Automation Control Conference (ITNEC), pp. 187-190, Dec. 2017, Chengdu, China.
[5] Z. Wang, and Z. Qu, “Research on Web text classification algorithm based on improved CNN and SVM,” IEEE 17th International Conference on Communication Technology (ICCT), pp. 1958-1961, October, 2017, Chengdu, China. [6] A. Jain, and J. Mandowara, “Text classification by combining text
classifiers to improve the efficiency of classification,” International Journal of Computer Application, vol. 6, no. 2, pp. 126-129, 2016.
[7] K. Sriwanna, “Text classification for subjective scoring using K-nearest neighbors,” International Conference on Digital Arts, Media and Technology (ICDAMT), pp. 139-142, Feb. 2018, Phayao, Thailand.
[8] G. Gautam, and D. Yadav, “Sentiment analysis of twitter data using machine learning approaches and semantic analysis,” Seventh International Conference on Contemporary Computing (IC3), pp. 437-442, August 2014, Noida, India.
[9] L. Li, L. Xiao, N. Wang, G. Yang, and J. Zhang, “Text classification method based on convolution neural network,” 3rd IEEE International Conference on Computer and Communications (ICCC), pp. 1985-1999, Dec. 2017, Chengdu, China.
[10] B. M. Garlapati, and S. R. Chalamala, “A System for Handwritten and Printed Text Classification,” 19th International Conference on Computer Modelling & Simulation (UKSim), pp. 50-54, April 2017, Cambridge, UK.
[11] A. S. Halibas, A. S. Shaffi, and M. A. K. V. Mohamed, “Application of text classification and clustering of Twitter data for business analytics,” Majan International Conference (MIC), pp. 1-7, March 2018, Muscat, Oman.
[12] G. Aydin, and I. R. Hallac, “Document Classification Using Distributed Machine Learning,” arXiv preprint arXiv:1802.03597, 2018.
[13] A. K. Uysal, and S. Gunal, “The impact of preprocessing on text classification,” Information Processing & Management, vol. 50, no. 1, pp. 104-112, 2014.
[14] S. L. Ting, W. H. Ip, and A. H. Tsang, “Is Naive Bayes a good classifier for document classification?”, International Journal of Software Engineering and Its Applications, vol. 5, no. 3, pp. 37-46, 2011.
[15] T. N. Rubin, A. Chambers, P. Smyth, and M. Steyvers, “Statistical topic models for multi-label document classification,” Machine learning, vol. 88, no. 1-2, pp. 157-208, 2012
![Fig. 1. An example study from literature [8]](https://thumb-eu.123doks.com/thumbv2/9libnet/3908731.44867/1.892.468.828.325.669/fig-example-study-literature.webp)