Metadata-based and personalized web querying
Tam metin
Şekil
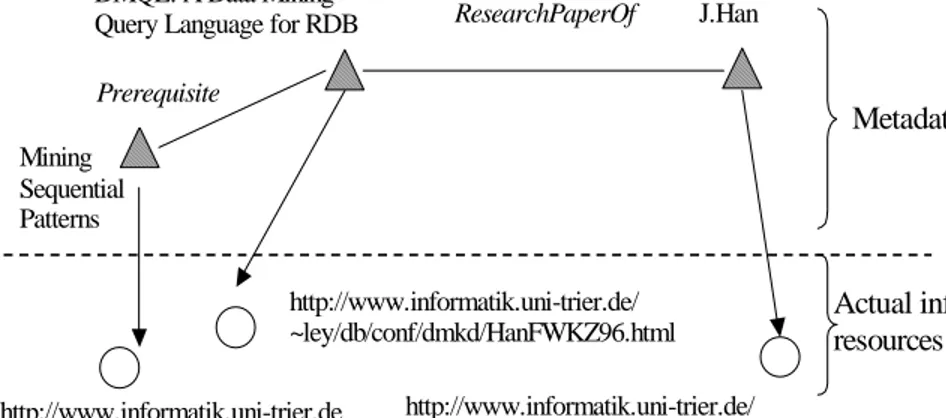
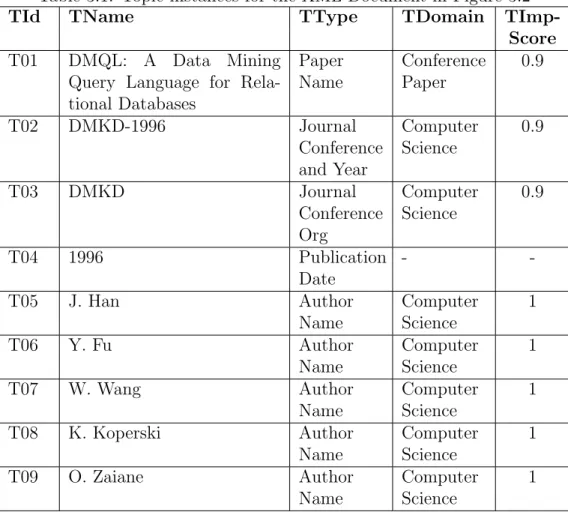
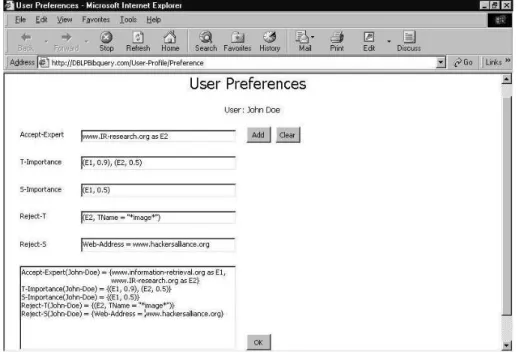
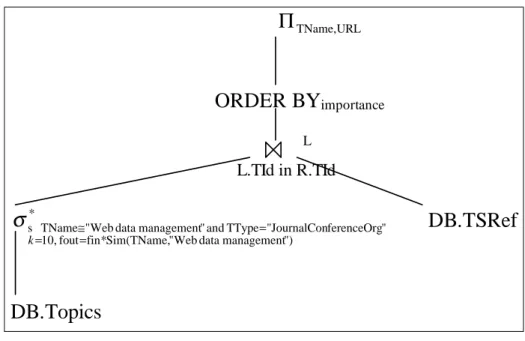
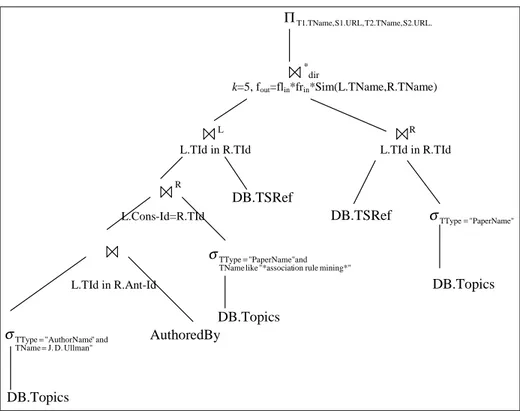
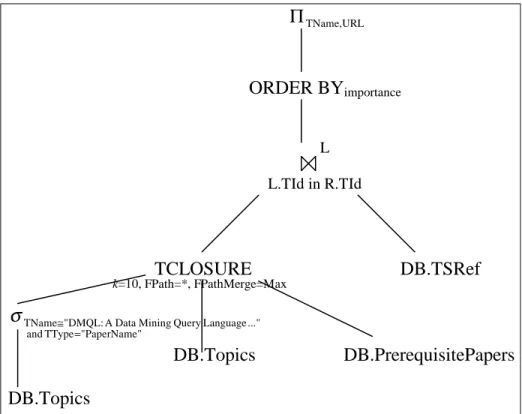
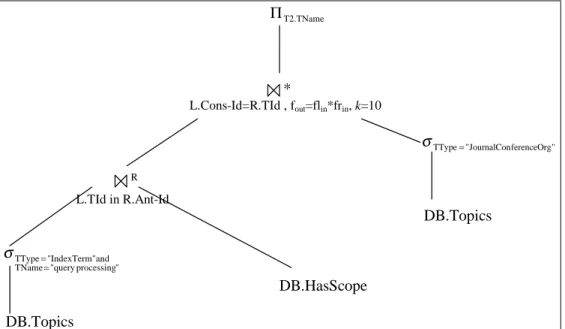
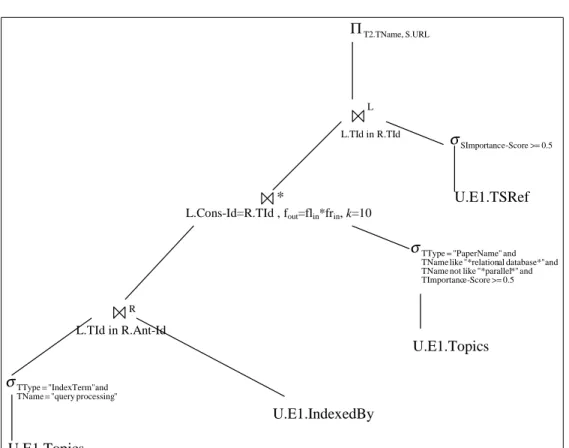
Benzer Belgeler
Finally, we developed four software systems as a practical outcome: the Skynet parallel text retrieval system, the SE4SEE search engine, the Harbinger text classification system, and
MFA algorithm is formulated for solving CPP using two alternative models in Chapter 3. It is shown that network model is a better scheme for mapping MFA to the
Hence, in order to avoid interprocessor communica tion during the sweeping phase and the extra communication during the front wave expansion phase, local boundary cells
In the third part, we £ analyze four patterns of interaction between sovereignty-bound actors * (SBAs) and SFAs in the implementation of Turkish foreign policy to- » ward
It is observed that the basic reproduction number and the mean duration of the infectious period can be estimated only in cases where the spread of the epidemic is over (for China
Bu yazıda tekrarlayan geçici iskemik atak nedeni ile araştırılan ve atipik yerleşimli ve morfolojik olarak daha nadir izlenen miksoma sap- tanan olgu sunuldu..
Kişisel Arşivlerde Istanbul Belleği Taha
The power capacity of the hybrid diesel-solar PV microgrid will suffice the power demand of Tablas Island until 2021only based on forecast data considering the
