Heterojen Veritabanı Yönetim Sistemleri için Bir Tekil
Veri Erişim Çerçevesi
Nail Diker1, Görkem Giray2[0000-0002-7023-9469], Murat Osman Ünalır3[0000-0003-4531-0566]
1 Logo Yazılım San. ve Tic. A.Ş., İzmir
2 Bağımsız Araştırmacı, İzmir
3 Ege Üniversitesi, Bilgisayar Mühendisliği Bölümü, İzmir
[email protected], [email protected], [email protected]
Özet. Farklı veri saklama ve sorgulama gereksinimleri için farklı saklama modelleri ve bu modelleri gerçekleyen çok sayıda araç bulunmaktadır. Bu araçlar veri saklama ve sorgulama konusundaki problemler için çözümler sunsa da diğer taraftan farklı araçlarda saklanan verilerin bütünleştirme problemi karşımıza çıkmaktadır. Bu problem için de çeşitli çözümler önerilmiştir. Bu çalışmada literatürde bulunan veri çeşitliliği ve bu veri çeşitliliği ile başa çıkmak için önerilen çözümler sınıflandırılarak incelenmiştir. Bu inceleme sonucunda yapılan çözümlemeler doğrultusunda veri çeşitliliği problemini çözmek için bir tekil veri erişim çerçevesi sunulmuştur. Bu tekil veri çerçevesinin faydası örnek bir durum senaryosunda gösterilmiştir.
Anahtar Kelimeler: Veri Yönetim Üst Modeli, Melez Veri, Melez Veri Erişim Mimarisi, Veri Çeşitliliği.
A Single Data Access Framework for Heterogeneous
Database Management Systems
Nail Diker1, Görkem Giray2[0000-0002-7023-9469], Murat Osman Ünalır3[0000-0003-4531-0566]
1 Logo Software, Izmir
2 Independent Researcher, Izmir
3 Ege University, Department of Computer Engineering, Izmir
[email protected], [email protected], [email protected]
Abstract. There are different data persistency models for different data storage and query requirements, and there are many tools that implement these models. Although these tools provide solutions for problems in data storage and query-ing, on the other hand, the problem of integration of data stored in different
tools is encountered. Various solutions have been proposed for this problem. In this study, data variety problem and the solutions proposed to deal with this problem are classified and examined. As a result of this analysis, a single data access framework is presented to solve the problem of data variety. The benefit of this single data access framework is illustrated in an exemplary case scenar-io.
Keywords: Data Management Metamodel, Hybrid Data, Hybrid Data Access Architecture, Data Variety.
1
Giriş
Veri hacminin, çeşitliliğinin, oluşma hızının artmasına paralel olarak verinin saklanması ve sorgulanması için farklı gereksinimler ortaya çıkmıştır. Bu gereksinimlerden bazılarını ilişkisel veritabanı yönetim sistemleri (VTYS) karşılayamamıştır. Bunun üzerine farklı gereksinimler için farklı veri saklama modelleri ve bu modelleri gerçekleştiren farklı araçlar ortaya çıkmıştır. Farklı gereksinimler için farklı VTYS’ler kullanılsa da bu veri depoları arasında çeşitli ilişkiler kurulması, farklı veri depolarında saklanan verilerin bütünleştirilmesi gereksinimi birçok durumda karşımıza çıkmaktadır. Bu problem için çeşitli çözümler önerilmiştir. Bu çalışmada literatürde bulunan veri çeşitliliği ve bu veri çeşitliliği ile başa çıkmak için önerilen çözümler sınıflandırılarak incelenmiştir. Bu inceleme sonucunda yapılan çözümlemeler doğrultusunda veri çeşitliliği problemini çözmek için bir tekil veri erişim çerçevesi sunulmuştur. Bu tekil veri çerçevesinin faydası örnek bir durum senaryosunda gösterilmiştir.
2
Problem Tanımı: Veri Kaynağı ve Veri Şeması Çeşitliliği
Son yıllarda elektronik ortamda saklanan verinin öneminin ve hacminin artmasıyla birlikte veri saklama yöntemlerinin ve araçlarının çeşitliliği de bununla paralel olarak artmıştır. Veri saklama için sunulan yöntemlerdeki ve araçlardaki çeşitliliği iki ana başlık altında sınıflandırmak mümkündür: (1) Veri kaynağı çeşitliliği ve (2) Veri şeması çeşitliliği. Şekil 1 veri kaynağı ve veri şeması çeşitliliği altındaki yaklaşımları ve bu yaklaşımları benimseyen araçları göstermektedir.
Veri kaynağı çeşitliliği, uygulamaların oluşturduğu verilerin saklanması konusunda farklı yaklaşımlar ve bu yaklaşımları takip eden farklı araçlar olması nedeni ile artmaktadır. Genel olarak baktığımızda çoğu uygulama veri saklamak için VTYS’leri kullanmaktadır. Veri saklama yaklaşımlarına göre VTYS’ler iki ana grup altında toplanabilir: (1) İlişkisel VTYS ve (2) İlişkisel olmayan (NoSQL) VTYS.
İlişkisel modeli temel alan çok fazla sayıda araç vardır. Bunlar arasında en yaygın kullanılanları Microsoft SQL Server, Oracle, MySQL ve PostgreSQL olarak sayılabilir. Bu VTYS’lerin ilişkisel modelin tablo, sütun, anahtar tanımları gibi temel kavramlarına yaklaşımları benzer olsa bile sorgulama dili özellikleri ve programlama yetenekleri farklılıklar göstermektedir. Microsoft SQL Server, T-SQL sorgulama dilini kullanırken, Oracle PL/SQL dilini kullanmaktadır.
İlişkisel VTYS’lerin ölçeklenebilirliği sınırlı olduğu ve yüksek hacimli verinin olduğu durumlarda bazı gereksinimleri karşılayamadığı için daha ölçeklenebilir olan ilişkisel VTYS’ler ortaya çıkmıştır [1]. İlişkisel olmayan VTYS’leri dört ana başlık altında incelemek mümkündür: (1) Anahtar/değer; (2) Doküman; (3) Sütun tabanlı; (4) Çizge.
Farklı modelleri benimseyen ilişkisel olmayan VTYS’ler de farklı problemleri çözmek için tasarlanmıştır [2]. Örneğin, bir anahtar ve buna karşılık gelen bir başka değerden oluşan çiftler diğer çiftlerden bağımsız olarak saklanacaksa bu durumda anahtar/değer VTYS’leri tercih edilebilir. Bu çiftlerin başka çiftlerle bağlantılı olarak saklanması gerekiyorsa bu durumda çizge VTYS’lerin tercih edilmesi daha uygun olacaktır [3].
Dört modelden birini benimseyen ve kendi içinde de farklılaşan çok sayıda VTYS bulunmaktadır. Örneğin MongoDB ve CouchDB en çok kullanılan doküman tabanlı VTYS’ler arasında yer almaktadır. [4]’e göre ilişkisel olmayan modelleri gerçekleyen araç sayısı 225’in üzerine çıkmıştır. Her 1,5 yılda bir araç sayısı iki katına çıkmaktadır [2].
Veri kaynağı ve veri şeması çeşitliliğini yönetmek için çeşitli çözümler önerilmiştir. Şekil 2’de gösterildiği gibi bu çözümleri VTYS ve uygulama düzeyinde olmak üzere iki sınıf altında incelemek mümkündür.
Şekil 2. Veri kaynağı ve veri şeması çeşitliliği için önerilen çözümlerin sınıflandırılması. Çoklu model (multi-model) VTYS’ler tek ve bütünleşik bir arka uç üzerinden birden fazla veri modelini desteklemektedir. İlişkisel ve ilişkisel olmayan modellere göre saklanan verinin tek bir platformda yönetilmesi geliştirme, bütünleştirme, bakım ve operasyon maliyetlerini azaltmaktadır. FoundationDB, OrientDB ve ArangoDB çoklu model VTYS’ler için örnek olarak verilebilir. Çoklu model VTYS’lerin yanısıra
HRDBMS çalışması gibi melez çözümler de üretilmektedir. HRDBMS, ilişkisel VTYS’ler ile büyük veri analiz platformlarının iyi yönlerini birleştirerek kullanıma sunan yeni nesil dağıtık bir ilişkisel VTYS’dir [5].
Uygulama düzeyinde çeşitliliğe sunulan API çözümleri için ODBAPI [6] ve ORESTES [7] verilebilir. ODBAPI, bulut uygulamalarında birden fazla ilişkisel veya ilişkisel olmayan VTYS’nin kullanıldığı senaryolarda ortaya çıkan sorunları çözmek amacıyla mimari önermektedir. Mimari de RESTful servisler üzerinden standart bir uygulama geliştirme arayüzü sağlanması ve servise ulaşan isteklerin uygulama kapsamında kullanılan ilgili veritabanı yönetim sistemine ulaştırılması tasarlanmıştır [6]. ODBAPI çalışması, çoklu dilli (polyglot) yapıdaki sistemler için bir geliştirme barındırmamaktadır. Bulut tabanlı olarak bir erişim arayüzü de sunmamaktadır. ORESTES, ODBAPI’den farklı olarak Service Level Agreement (SLA) yönetimi de yapılabilmektedir [7]. Bu çalışmada, uygulama geliştirme için yaygın olarak kullanılan ORM (Object Relation Mapping) kütüphanelerinin birer servis olarak sunulması hedeflenmiştir. DynamoDB, Azure Tables gibi yeni nesil bulut tabanlı VTYS’leri kapsamaktadır.
Geliştirme çözümleri başlığı altında bulunan çoklu dilli kalıcılık (polyglot persistence) kavramı, uygulama düzeyinde farklı VTYS’lerin farklı yeteneklerini bir arada kullanmayı hedeflemektedir [8]. Yaklaşım olarak çoklu dilli kalıcılık benimsendiğinde veri tutarlılığı ve bütünlüğü hususlarına dikkat edilmelidir. İlişkisel VTYS’lerde bulunan ACID (Atomicity, Consistency, Isolation, Durability) prensibine uygun “transaction” yönetimi yerine BASE (Basic Availability, Soft-State, Eventual Consistent) prensibi çoklu dilli kalıcılık yaklaşımında benimsenmektedir. CQRS (Command Query Responsibility Segregation) tasarım deseni veri ekleme, güncelleme ve silme işlemlerini bir veri deposunda veri okuma işlemlerini de bir başka veri deposunda yapmayı önermektedir. Bu iki veri deposu arasındaki bağlantıdan sorumlu bir senkronizasyon bileşeni bulunmaktadır ve veri tutarlığını bu bileşen sağlamaktadır.
3
Çözüm Önerisi: Melez Veri Erişim Mimarisi
3.1 Melez Veri Yönetimi Üst Modeli
Tüm VTYS’lerde veri saklama yaklaşımları farklılık gösterse de soyut ve genel bir bakış açısıyla bakıldığında bazı ortak noktalar bulunmaktadır. Bu çalışma kapsamında tasarlanan melez veri yönetimi üst modelinin, modelleme hiyerarşisindeki yeri Şekil 3’te gösterilmektedir. M0 seviyesinde saklanan veri, M1 seviyesinde ise bu verinin saklandığı modele (ilişkisel, ilişkisel olmayan gibi) göre değişen üst verisi bulunmaktadır. M2 seviyesinde ise model farklılığından bağımsız olarak tasarlanmış olan melez veri yönetimi üst modeli bulunmaktadır.
Melez veri yönetimi üst modelinde ilişkisel ve ilişkisel olmayan modeller tek bir üst model altında toplanmıştır. Doküman, sütun ve anahtar/değer tabanlı veritabanları ilişkisel olmayan modeller kapsamında yer almaktadır. Çizge tabanlı veritabanları ise ayrı ele alınmıştır. Bunun nedeni çizge tabanlı dışındaki ilişkisel olmayan modellerin
aslında anahtar/değer sistemlerinin temellerini takip ederek geliştirilmiş olmasıdır. Melez veri yönetimi üst modeli kullanılarak farklı modelleri kullanan VTYS’lerin bir üst seviyede yönetilmesi hedeflenmiştir. Böylece M2 seviyesinde tüm veri saklama araçları için birleştirilmiş bir arayüz sunulması hedeflenmiştir.
İlişkisel Model İlişkisel Olmayan
Modeller Ontoloji Modeli
Çizge Modeli kullanır Melez Veri Yönetimi Üst Modeli
V E R İ
M0 M1 M2
Şekil 3. Melez veri yönetimi üst modelinin modelleme hiyerarşisindeki yeri [9]. 3.2 Melez Veri Yönetimi Üst Modelinin Tasarımı
Melez veri yönetimi üst modelinin esnek ve genişleyebilir bir yapıda olması gerekmektedir. Değişen gereksinimler doğrultusunda, bundan önce de olduğu gibi, gelecekte farklı veri saklama yaklaşımları geliştirilecek ve bu yaklaşımların yaygınlaşmasına paralel olarak melez veri yönetimi üst modelinin bu yaklaşımları da kapsayacak şekilde genişletilmesi söz konusu olacaktır.
Melez veri yönetim üst modeli için Tozer’in geliştirdiği veri yönetimi üst modeli [10] temel alınmıştır. Tozer’in üst modeli sadece ilişkisel ve nesne tabanlı modelleri kapsamaktadır. Bu çalışma kapsamında bu üst model ilişkisel olmayan modelleri de destekleyecek şekilde genişletilmiştir.
Melez veri yönetim üst modelinin tasarım sürecinde öncelikle farklı veri saklama yaklaşımları temel alınarak tasarlanmış VTYS’lerin üst veri yapıları oluşturulmuştur. Bu kapsamda ilişkisel, anahtar/değer, doküman, sütun ve çizge tabanlı VTYS’lerinin ortak özelliklerini temsil edecek Datastore kavramı tanımlanmıştır.
Datastore temel kavramının her bir VTYS için özelleşmiş hallerini temsil edecek kavramların oluşturulmasıyla tasarıma devam edilmiştir. Örneğin, en yaygın olarak kullanılan ilişkisel VTYS’lerinde ortak olarak kullanılan kavramlar belirlenip melez veri yönetim üst modeli zenginleştirilmiştir: Veritabanı, Tablo, Satır, Sütun, Birincil Anahtar, Yabancı Anahtar.
Kullanımı giderek yaygınlaşan doküman tabanlı VTYS’leri için de aynı şekilde ortak kavramlar belirlenmiştir: Veritabanı, Koleksiyon, Doküman, Alan, Değer.
Her bir VYTS’yi temel alarak tasarlanmış kavramlar belirli bir özellik kümesine kadar ortaklaşmayı sağlamaktadır. Fakat bu yaklaşımlar kullanılarak geliştirilmiş araçlar temelinde değişen özelliklerin de melez veri yönetim üst modelinde kapsanması gerekmektedir. Örneğin, ilişkisel model kullanılarak geliştirilmiş olan Microsoft SQL Server, veritabanı işlemlerini yönetmek için “Transact SQL” (T-SQL) sorgu dilini kullanmaktadır. T-SQL, SQL standardının üzerine birtakım gelişmiş
özelliklere sahiptir. Oracle ise “Procedural Language/SQL” (PL/SQL) kullanarak ilişkisel modelin özelliklerini desteklemeyi tercih etmiştir.
Doküman tabanlı VTYS’ler için ise MongoDB ve CouchDB incelendiğinde her ikisinde de dokümanlar alanlardan oluşmakta ve her bir alanın kendine özgü değerleri bulunmaktadır. MongoDB’de dokümanlar, koleksiyonlar içerisinde saklanmaktadır. Koleksiyonlar ise veritabanları kapsamında yer almaktadır. Oysaki CouchDB’de bu tarz bir yapı bulunmamaktadır ve dokümanlar doğrudan veritabanı seviyesinde saklanmaktadır (Bkz. Tablo 1).
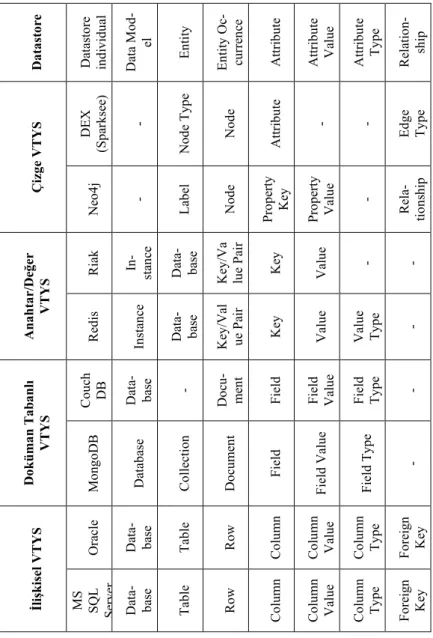
Tablo 1. Melez veri yönetim üst modelindeki kavramlar
Da ta sto re Da tas to re in di vid ua l Da ta M od -el En ti ty En ti ty O c-cu rre nc e A tt rib ute Attri bu te Va lu e Attri bu te Ty pe Re latio n-sh ip Çiz ge VTY S DEX (S pa rk se e) - No de Ty pe No de Attri bu te - - Ed ge Ty pe Ne o4 j - Lab el No de P ro pe rt y Ke y P ro pe rt y Va lu e - Re la-ti on sh ip Ana h ta r/De ğe r VTY S Riak In -sta nc e Da ta-ba se Ke y/Va lu e P air Ke y Va lu e - - Re dis In sta nc e Da ta-ba se Ke y/Va l ue P air Ke y Va lu e Va lu e Ty pe - Do k ü m an T ab an lı VTY S Co uc h DB Data- base - Docu -m en t F ield Field Va lu e F ield Type - M on go DB Da tab ase Co ll ec ti on Do cu m en t F ield F ield Va lu e F ield T yp e - İlişk ise l VTY S Ora cle Da ta-ba se Tab le Ro w Co lu m n Co lu m n Va lu e Co lu m n Ty pe F ore ig n Ke y MS SQL Serv er Da ta-ba se Tab le Ro w Co lu m n Co lu m n Va lu e Co lu m n Ty pe F ore ig n Ke y
Anahtar değer ikililerini barındıran ve ilişkisel olmayan VTYS’nin en temel halini temsil eden sistemlerde de ilişkisel ve doküman tabanlı VTYS’lere benzer ürünlere özelleşmiş davranışlar ve yetenekler mevcuttur. Örneğin Riak değer olarak ne türde bir veri saklandığı ile ilgili hiçbir bilgi barındırmazken Redis daha yapısal bir yaklaşım benimseyerek değer türü olarak belirli tiplere izin vermektedir.
Ürünler arasında veri yönetimi açısından işlevsel olmayan farklılıklar da mevcuttur. Riak ve Redis ürünleri bu anlamda incelendiğinde Riak’ın Microsoft Windows işletim sistemleri üzerinde çalışamadığı, Redis’in ise bu işletim sistemini de desteklediği görülmektedir. Bu anlamda doküman VTYS’leri için ise CouchDB’nin CRUD işlemleri için REST (“REpresentational State Transfer”) uyumlu olarak hazır bir hizmet sunarken, MongoDB’nin böyle bir hazır hizmeti bulunmamaktadır.
Tasarım sürecinin sonucunda, Tozer’in veri yönetim üst modeli, tüm bu örneklerden hareketle ürünlere özgü bu farklılıkları kapsayacak şekilde genişletilmiştir. Elde edilen melez veri yönetim üst modeli Tablo 1’de gösterilmektedir.
Tablo 1’de “Datastore” başlıklı kolonda yer alan kavramlar Tozer’in üst modelinde bulunan kavramlardır. Bunların ilişkisel ve ilişkisel olmayan VTYS’de araç düzeyindeki kavramsal karşılıkları tabloda belirtilmiştir. Tabloda yer alan kavramlar dışında üst model Datastore kavramı ile zenginleştirilmiştir. Datastore kavramını özelleştiren kavramlar ise veri saklama yaklaşımlarına göre tasarlanmıştır.
3.3 Bir Melez Veri Erişim Mimarisi Önerisi
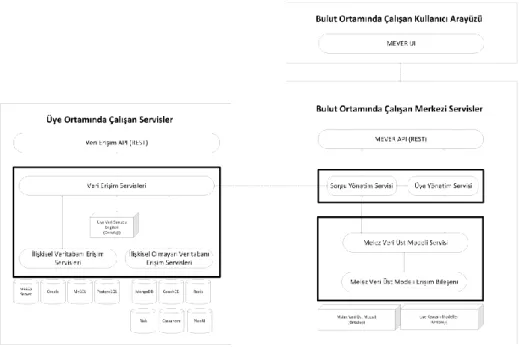
Bir önceki bölümde açıklanan melez veri yönetim üst modelini gerçekleyen bir mimari Şekil 4’te gösterilmektedir.
Mimaride önerilen bileşenler aşağıda kısaca açıklanmıştır:
MEVER (Melez Veri Erişim Çerçevesi) API: Sistemin dışa açılan yüzünü temsil etmektedir. Sistem işlevlerinin tümü bu API üzerinden sunulmaktadır. Bu işlevler, (1) Yeni üyelik işlemi; (2) Üye VTYS’lerinin tanımlanması; (3) Üye kavramlarının tanımlanması; (4) Kavram sorgulama; (5) Önerilerin alınması olarak sıralanabilir. MEVER (Melez Veri Erişim Çerçevesi) UI: MEVER API kapsamında yer alan
işlevlerin kullanıcılar tarafından rahat şekilde kullanılmasını sağlayan arayüzleri barındırmaktadır.
Sorgu Yönetim Servisi: Gelen sorguların iletildiği servistir. Melez veri modeli servisi ile haberleşerek üyeye özel kavram tanımı, özellikleri ve özelliklere karşılık gelen veri modeli düzeyindeki bilgileri alır. Sorguyu kavramsal düzeyden veri erişim servislerinde çalışacak VTYS sorgularına dönüştürmekle görevlidir. Bu görevinin yanı sıra veri erişim servislerinden dönen sonuç kümelerine göre sorgu cevabını oluşturacak kavram ya da kavramları oluşturur. Oluşturduğu kavram ya da kavramları MEVER API’ye iletir.
Üye Yönetim Servisi: Yeni üye kayıt işlemleri, üyeye ait VTYS ve kavram tanımlarının alınması ve bu bilgilere erişilmesinden sorumludur. Bir kavram sorgusu yapıldığında üyenin bilgilerini kontrol eder.
Veri Erişim Servisleri: Üyeye ait VTYS’ler ile doğrudan veya VTYS servisleri üzerinden kendisine iletilen sorguları çalıştırır ve sonuç kümelerini geri döndürür. Üyelerin kendi ortamlarında çalışacaktır. İlişkisel ve ilişkisel olmayan VTYS’lerine özelleşmiş servisler ile haberleşmektedir.
Melez Veri Üst Modeli Servisi: Melez veri modeline, üye kavram ve veri sunucusu bilgilerine erişimi yöneten servistir.
Üye Kavram Modelleri: Üyelere ait kavramları Melez Veri Modeline uygun şekilde saklayan ontolojilerdir.
Üye Veri Sunucu Bilgileri: Üyelere ait VTYS sunucuların erişim yöntemlerini Melez Veri Modeline uygun şekilde saklayan ontolojilerdir.
Şekil 4. Melez veri erişim mimarisi.
4
Durum Çalışması
4.1 Problem
Birçok alanda çok çeşitli verinin farklı gereksinimleri yerine getirecek şekilde saklanması ve bu verinin gerektiğinde bütünleştirilerek istemcilere sunulması gerekmektedir. Böyle bir duruma örnek olarak insan kaynakları alanından bir problem seçilmiştir.
Çoğu firma, faaliyetini sürdürebilmek için çalışanlar istihdam etmektedir. Firmanın, çalışanlarıyla ilgili sakladığı verinin kapsamı firmaların faaliyet gösterdiği sektörlere ve işleyişlerine göre değişiklik göstermektedir. Genel olarak değişiklik göstermeyen veri olarak çalışanın adı, soyadı, doğum tarihi, kan grubu, vatandaşlık
numarası, fotoğrafı gibi kişiye özgü bilgiler; firmayla olan çalışma ilişkisini temsil eden veri için de sicil numarası, firmadaki pozisyonu, işe giriş tarihi, sözleşmesi ele alınabilir.
Bordrolama süreçleri için “Logo BordroPlus” ve “Netsis 3 Bordro” uygulamalarını farklı kurumlarında aynı anda kullanan holding veya şirketler grubu örnekleri ile karşılaşılmaktadır. Her iki uygulama benzer iş adımlarını gerçekleştirmek üzere kurgulandıkları için aynı kavramları farklı veritabanı desenlerinde saklamaktadır. Örneğin çalışan kavramı ile ilgili verileri, “Logo Bordro Plus” uygulaması Tablo 2’de gösterildiği gibi bir tabloda saklamaktadır. “Netsis 3 Bordro” uygulaması ise çalışan kavramıyla ilgili verileri iki ayrı tabloda saklamaktadır. “Logo Bordro Plus” uygulamasının çalışan ile ilgili Tablo 2’de gösterilen dört alandaki veriye “Netsis 3 Bordro” uygulamasında erişmek için bir görünüm (view) oluşturulmuştur.
Tablo 2. İki farklı uygulamada “çalışan” kavramıyla ilgili aynı verileri temsil eden iki farklı veritabanı nesnesi.
Logo Bordro Plus Netsis 3 Bordro
Tablo adı: LH_{KurumNo}_PERSON Görünüm adı: SICIL Ko lo nlar LREF CODE NAME SURNAME Ko lo nlar OZLUKID SICILNO ADI SOYADI
Örnekte bahsedilen her iki uygulama da birden fazla ilişkisel VTYS’yi desteklemektedir. Örneğin bir kurum Oracle kullanırken diğer kurum MS SQL Server’ı tercih edebilir. Dolayısıyla yukarıda anlatılan veri şemasındaki çeşitliliğin yanında veri kaynağı çeşitliliği de örnek durum çalışması için söz konusudur.
4.2 MEVER Kullanılarak Oluşturulan Çözüm Önerisi
Şirketler grubu veya holding açısından bakıldığında çalışanların tekil bir arayüz üzerinden sorgulanabilmesi gerekmektedir. Bu sorunun çözümü için melez veri yönetim üst modeli kullanılarak şirketler grubuna özel bir çalışan kavramının tanımlaması Tablo 3’te gösterildiği gibi yapılabilir.
Tablo 3. Çalışan kavramına ait özellikler. EMPLOYEE
EMPLOYEE_SYSTEM_ID EMPLOYEE_CODE EMPLOYEE_NAME EMPLOYEEE_SURNAME
Bu kavramı oluşturan özellikler ile veritabanı deseninde yer alan alanlar eşleştirilerek üst model ile veritabanı yönetim sistemlerinde bulunan tabloların eşleşmesi sağlanmaktadır. Bu noktada tek bir kavramın birden fazla sistemde yer alan veri yapısı ile bütünleşik çalışabilmesi sağlanmış olmaktadır. Bordrolama uygulamalarını kullanan şirketlerin bu uygulamaları kullanım biçimlerinde herhangi bir değişiklik yapmasına gerek yoktur. Aynı zamanda teknik düzeyde bir dönüşüm, yenileme ve/veya uygulamaların yeniden geliştirilmesi ihtiyacı bulunmamaktadır.
Tekil bir arayüz üzerinden sorgulama/raporlama yapabilmek için veri senkronizasyonu veya transferi gerekmemektedir. Bununla birlikte “on-premise” olarak kendi sistemleri içinde yer alan verilere bulut ortamından, dolayısıyla İnternet erişiminin olduğu herhangi bir yerden erişim olanağı da yaratılmaktadır. Bir önceki bölümde bahsedilen veri erişim servislerinin, üyelerin kendi ortamlarında çalışacağı tasarlandığı için veritabanı sorguları yerel ağlar üzerinde çalıştırılacak ve üyelerin sadece görüntülemek istediği verilerin İnternet üzerinden transferi gerçekleştirilecektir. Veritabanı yönetim sistemlerinin dış ağlara açılma ihtiyacı bulunmadığı için güvenlik anlamında da bir dezavantaj oluşması engellenmektedir.
Eğer mevcut yaklaşım ve yöntemlerle üzerinde durulan örnek durum çalışması gerçekleştirilmek istenseydi, bir raporlama veya iş analitiği uygulaması üzerinden veritabanı yönetim sistemlerinden verilerin bu uygulamaya belirli aralıklarla aktarılması ve iş analitiği uygulaması üzerinden kavramsal olarak değil sadece bu rapora özel veri yapısının tasarlanması söz konusu olacaktır.
MEVER kullanılarak anahtar kelime tabanlı olarak kavram ve/veya bulunmak istenen anahtar kelime girilerek sorgu yapılabilir. Bu sorgu sonucunda kavramın her bir veritabanı sisteminde eşlenmiş olan veritabanı yapılarına (ilişkisel model ise tablo veya görünüm) karşılık geldiği ontoloji üzerinden tespit edilir. Bu veritabanı yapılarının içerik yapılarına uygun sorgulama cümleleri MEVER tarafından oluşturulur. Örneğin, MEVER’deki “çalışan” kavramı kullanılarak ve “Ufuk” anahtar kelimesini “sicil kodu”, “adı” ve “soyadı” alanlarında arayan bir sorgu MEVER tarafından iki uygulama için aşağıdaki gibi iki sorguya otomatik olarak dönüştürülmektedir.
“Logo Bordro Plus” veritabanı için: SELECT * FROM LH_001_PERSON WHERE CODE LIKE ‘%UFUK%’ OR NAME LIKE ‘%UFUK%’ OR SURNAME LIKE ‘%UFUK%’
“Netsis 3 Bordro” veritabanı için: SELECT * FROM SICIL WITH(NOLOCK) WHERE SICILNO LIKE ‘%UFUK%’ OR ADI LIKE ‘%UFUK%’ OR SOYADI LIKE ‘%UFUK%’
Bu sorgular ontoloji tarafından hangi ilişkisel veritabanı yönetim sistemi kullanılmış ise onun desteklediği SQL kurallarına uygun olarak oluşturulur. Örneğin Oracle ise PL/SQL, MSSQL Server ise T-SQL kurallarına uygun oluşturulur. Böylelikle veri kaynağı çeşitliliği MEVER seviyesinde ortadan kaldırılmış ve sorgu detaylarının sorumluluğu MEVER’e teslim edilmiştir. Veri şeması çeşitliliği anlamında da farklı uygulamaların farklı veritabanı desenlerine uygun olarak tanımlamalar ontoloji seviyesinde bir kez yapıldığı ve oluşturulan sorgular MEVER’in dışa açılan kullanıcı arayüzü ve servis seviyelerinde bu uygulamalardan bağımsız olduğu için tekil bir görünüme ulaşılmaktadır. Yukarıda oluşturulan sorgular
ayrı ayrı uygulama veritabanlarında eş zamanlı olarak çalıştırılıp sonuçlar MEVER’in üst veri yönetim modeline uygun formata dönüştürülüp kullanıcıya tekilleştirilmiş bir şekilde sunulmaktadır.
5
Sonuçlar
Bu çalışmada veri çeşitliliği problemine çözüm olarak bir melez veri erişim mimarisi önerilmiştir. Günümüzde verinin dağıtık doğası düşünüldüğünde bu mimari servis tabanlı olarak tasarlanmıştır. Veri yönetim üst modeli farklı veri saklama yöntemlerini birleştiren soyut ve genel model olarak M2 seviyesinde konumlandırılmıştır. Mimaride bu üst model ontolojilerle gerçeklenmiştir. Melez veri erişim mimarisi geliştirilerek bu çalışmada kısaca anlatılan bir örnek durum senaryosuyla faydası gösterilmiştir.
Kaynakça
1. Martin Fowler, The Future is : Polyglot Persistence,
https://martinfowler.com/articles/nosql-intro-original.pdf, 2012
2. Marcus, A. (2011). The nosql ecosystem. The Architecture of Open Source Applications, 185-205.
3. Developer Guides,
https://neo4j.com/developer/graph-db-vs-nosql/#_relate_key_value_stores_with_graph_databases 4. List of NoSQL Databases, http://nosql-database.org/
5. Arnold, J., Glavic, B., & Raicu, I. (2019). HRDBMS: Combining the best of modern and traditional relational databases. arXiv preprint arXiv:1901.08666.
6. Sellami, R., Bhiri, S., & Defude, B. (2014, June). ODBAPI: a unified REST API for relational and NoSQL data stores. In 2014 IEEE International Congress on Big Data (pp. 653-660). IEEE.
7. Gessert, F., Friedrich, S., Wingerath, W., Schaarschmidt, M., & Ritter, N. (2014). Towards a Scalable and Unified REST API for Cloud Data Stores. In GI-Jahrestagung (pp. 723-734).
8. Schaarschmidt, M., Gessert, F., & Ritter, N. (2015). Towards automated polyglot persistence. Datenbanksysteme für Business, Technologie und Web (BTW 2015).
9. Diker, N., Giray, G., & Ünalır, M. O. (2016). Servis Tabanlı Bir Melez Veri Erişim Mimarisi Önerisi. UYMS.
10. Tozer, G. (1999). Metadata management for information control and business success. Artech House, Inc.


![Şekil 3. Melez veri yönetimi üst modelinin modelleme hiyerarşisindeki yeri [9]. 3.2 Melez Veri Yönetimi Üst Modelinin Tasarımı](https://thumb-eu.123doks.com/thumbv2/9libnet/3811581.32941/6.892.223.677.299.484/şekil-yönetimi-modelinin-modelleme-hiyerarşisindeki-yönetimi-modelinin-tasarımı.webp)