128
TECHNICAL ARTICLE
Input
Data
Analysis
Using
Neural Networks
Anil Yilmaz
Turkish Prime
Ministry
State
Planning Organisation
Yucetepe,
Ankara06100,
Turkey
E-mail:
[email protected]
Ihsan
Sabuncuoglu
Department
of IndustrialEngineering
BilkentUniversity
Bilkent,
Ankara06533,
Turkey
E-mail: [email protected]
Simulation deals with
real-life phenomena by
constructing representative
modelsof a
system
being questioned. Input
dataprovide
adriving
force for
such models. Therequirement for
iden-tifying
theunderlying
distributionsof data
setsis encountered in
many fields
and simulationapplications
(e.g., manufacturing
economics,
etc.). Most
of
the time,after
the collectionof
theraw
data,
the true statistical distribution issought by
the aidof
nonparametric
statistical methods. In this paper, weinvestigate
the
feasi-1. Introduction
z
Simulation models have a very wide range of
applica-tion areas from
manufacturing
todefense,
economic and financialsystems,
and theinput
data used in these models areusually represented by probability
distri-bution functions. Sinceinput
dataprovides
adriving
force for simulation
models,
thistopic
isextensively
studied in the simulation literature
[1].
As also indi-catedby
Law and Kelton[2],
failure to choose thecor-rect distribution can affect
credibility
of simulationmodels.
However,
identification of the truedif-distribution
by
the aid ofnonparametric
statistical methods(heuristics
and othergraphical
methods).
Summary
statistics such as minimum, maximum,mean,
median,
variance, coefficient of variation, lexisratio, skewness, kurtosis,
etc., areused,
as well asother statistical
tools,
some of which arehistograms,
line
graphs, quantile
summaries, boxplots,
Q-Q
and P-Pplots.
Inpractice,
this task is sometimescumber-some and time
consuming.
The aim of this
study
is toinvestigate
thefeasibility
ofusing
neural networks for theinput
dataanalysis
(identification
ofprobability
distributions)
and discuss the difficulties inusing
neuralnetworks,
as well as theirstrength
and weaknesses over the traditional methods(i.e.,
Chi-square goodness-of-fit
test,etc.).
The rest of the paper is
organized
as follows. InSec-tion 2, we
present
a brief review of the relevant litera-ture on theapplication
of neural networks to thein-put
dataanalysis.
In Section 3, weexplain
themethod-ology
used in ourstudy.
Wegive
theexperimental
settings
in Section 4. Thecomputational
results arediscussed in Section 5.
Finally,
we makeconcluding
remarks and
suggest
further research directions.2. Literature
Survey
The
input
dataanalysis,
which is also referred to asinput
datamodelling
ormodelling
input
processes, isnot
extensively
studied in the simulation literature. Thetopic
is discussed in detail in[1], [2]
and[3].
Gen-eral
procedures
toidentify
the correct distribution functions are also outlined in these references. In theinput
dataanalysis
literature,
Shanker and Kelton[5]
investigated
the effect of distribution selection on thevalidity
ofoutput
fromsingle
queuing
models. The. authors also
compared
theempirical
distribution functions(i.e.,
distribution of thesample
data)
with standardparametric
distribution functions(e.g.,
Uni-form,
Exponential,
Weibull).
Their results indicated that on the basis of variance and bias in theirestima-tions, the
performance
of theempirical
distributions iscomparable
with,
even sometimes betterthan,
standard distribution functions. Vincent and Law[6]
proposed
a software
package
called UNIFIT II forinput
dataanalysis.
The authors discuss the role of simulationinput
modeling
in a successful simulationstudy.
In arelated
work,
Vincent and Kelton[7]
investigated
theimportance
ofinput
data selection onvalidity
ofsimu-lation models and discuss the
philosophical
aspects
ofthe current
thinking.
Johnson
andMollaghasemi
[8]
explored
thetopic
from a statisticalpoint
of view. The authorsprovided
acomprehensive bibliography
anda list of
specific
researchproblems
in theinput
dataanalysis. Finally,
Banks, Gibson,
Mauer and Keller[9]
discussedempirical
versus thoretical distributions andexpressed
theiropposite
views(points
andcoun-terpoints)
oninput
dataanalysis.
In the neural network
literature,
neural networkscan be used in
place
of statisticalapproaches
applied
to classification and
prediction
problems
[10].
Ingen-eral,
advantages
of neural networks in statisticalap-plications
are theirability
toclassify
robustness toprobability
distributionassumptions,
and theability
to
give
reliable results even withincomplete
data. Inthis context, neural networks are
employed
wherere-gression,
discriminantanalysis, logistic
regression
orforecasting approaches
are used.Marquez
[11]
hasprovided
acomplete
comparison
of neural networks and
regression analysis.
The results of hisstudy
suggest
that the neural networks can dofairly
well incomparison
toregression
analysis.
Theprediction
capability
of neural networks has been stud-iedby
alarge
number of researchers. Inearly
papers,Lapeds
and Farber[12]
and Sutton[13]
offered evi-dence that the neural models are able topredict
time series datafairly
well.Many comparisons
of neuralnetworks and time series
forecasting techniques,
suchas the
Box-Jenkins
approach,
arereported
[10].
Thereader can refer to
[14], [15]
and[16]
for furtherread-ing
onapplication
of neural networks to dataanalysis.
In the
literature,
there areonly
a few studies on theapplication
of neural networks to theinput
dataanal-ysis
problem
(Table 1).
The firststudy
in this area isby
Sabuncuoglu,
Yilmaz andOskaylar
[17],
whoinvesti-gated
thepotential applications
of neural networks Table 1. A list ofprevious
studies and their characteristicsduring
theinput
dataanalysis
stage
of simulation studies.Specifically,
counter-propagation
andback-propagation
networks were used as thepattern
classi-fier todistinguish
data sets among three basic distri-bution functions:exponential,
uniform and normal.Histograms
consisting
of tenequal-width
intervalswere used as
input
vectors in thetraining
set. Theper-formance of the networks was
compared
to thestan-dard
goodness-of-fit
tests for differentsample
sizes andparameters.
The results indicated that neural net-works arequite
successful for identification of these three distribution functions.Akbay,
Ruchti and Carlson[18]
proposed
a neuralnetwork
model,
which is based on thequantile
infor-mation to
recognize
certainpatterns
in raw data sets. The authors measured theprediction capability
of aprobabilistic
and aback-propagation
neural networkand
compared
the results with traditional statisticalmethods. Nine
equal
interval normalizedquantile
values were used as theinput,
and 25 differentcat-egories
of distributions were identified. The resultsindicated that the
probabilistic
neural network(PNN)
learned(i.e.,
was able tocorrectly identify)
all the 25categories
in thetraining
set, whereas theback-propa-gation
network was able to learn 24categories.
In anotherstudy, Aydin
andOzkan
[19],
using
amulti-layer
perceptron
network,
investigated
the per-formance of the neural network fordistinguishing
amongnormal,
gamma,exponential
and beta distri-butions.They compared
the results with those of thechi-square
test. Theinput
used fortraining
the net-works was selected as the minimum and maximumvalues for the
distributions,
as well as normalizedfre-quencies.
The number offrequency
intervals to be usedwas determined
by
constructing
various networkswith different numbers of
frequency
intervals.In a recent
study,
Yilmaz andSabuncuoglu
[20]
de-veloped
a PNN todistinguish
23 differenttypes
ofseven
probability
distributions. The authors usedskewness,
eight quantile
and twelve cumulativeprob-ability
values to train the neural network. Their results showed that PNN isgood
athypothesizing
the distri-bution of raw data sets. The authors alsosuggested
that there should be a
grouping
of distributions withsimilar
shapes
and aspecialized
neural network shouldimplement
the selection process within each group.30% reduction in the error
compared
to the best indi-vidual classifier. In anotherstudy,
Jordan
andJacobs
[23]
proposed
anarchitecture,
which is a hierarchicalmixture model of
experts
andexpectation
maximiza-tionalgorithms.
By
thisapproach,
the authors divideda
complex problem
intosimpler problems
that can besolved
by
separate
expert
networks. Boers andKuiper
[24]
developed
acomputer
program to find a modularartificial neural network for a number of
application
areas(handwritten
digit
recognition, mapping
prob-lem,
etc.).
In a laterwork,
Hashem[25]
extended theidea of
optimal
linear combinations of neural networks and derive closed formexpressions.
The resultsdem-onstrated considerable
improvements
in modelaccu-racy,
leading
to a 81 % to 94% reduction in true MSEcompared
to theapparent
best neural network. The author alsoprovided
acomprehensive
bibliography
onmultiple
neural networks.Yang
andChang
[26]
proposed
atwo-phase
learn-ing
modular neural network architecture to transforma multimodal distribution into known and more
learn-able distributions.
They decomposed
theinput
spaceinto several
subspaces
and trained aseparate
multi-layer
perceptron
for each group. Aglobal
classifier network is trained for the secondphase
oflearning.
This network uses the
inputs
from various localnet-works and maps this new data set to a final
classifica-tion space. The authors concluded that the
two-phase
learning
modular network architecture reduces to agreat
extent the chance ofsticking
to a local minimum.They
also argue that thetwo-phase
method is betterin
performance
and morerobust,
and lessdependent
on architectureparameters
as well as selection oftraining
samples.
’
Chen et al.
[27]
presented
aself-generating
modu-lar neural network architecture to
implement
thedi-vide-and-conquer
principle.
A tree-structured modular neural network isautomatically generated by
recur-sively
partitioning
theinput
space. The results onsev-eral
problems, compared
to asingle multi-layer
percep-tron, indicated that the
proposed
methodperforms
well both in terms ofhigh
success rate and short CPU time.3. Research
Methodology
We aim at
differentiating
among 23 differentspecial
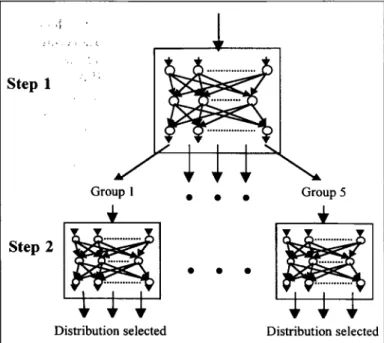
of distinct distributions based differentFigure
1.Two-step
multiple
neural networkapproach
formultiple
neural networks.According
to thisapproach,
in the firststep
asingle
network is used to
classify
distributions with similarshapes.
In the secondstep,
specialized
networks areused to detect different
types
from each group of dis-tribution functions. In this paper weimplement
thistwo-step
multiple
neural networkapproach (Figure
1).
Step
1 consists ofgrouping
distributions that have simi-larshapes
andtraining
a neural network thatperforms
the classification task based on this
grouping.
Here, thetrained neural network is
expected
tocorrectly
cat-egorize
among the different groups of distributions.In the second
step,
for each group of distributions identified in theprevious
step,
a different network istrained and tested. These
specialized
networks are usedto further
classify
theinput
data intospecific
distribu-tion functions. At thisstage,
thetraining
sets and net-work structures for each group are formedby
trial and error. Theinputs
that would be mostappropriate
foreach group are selected among all
possible
summarystatistics such as range, mean, variance, coefficient of
variation,
skewness, kurtosis,
quantile
and cumulativeprobability
information. Inaddition,
composite
mea-sures such as kurtosis divided
by
the coefficient ofvariation or
(skewness
+kurtosis) /
(coefficient
ofvariation)
are used in theexperiments.
This selectionprocess is
explained
in detail in thefollowing
section. Aftertraining
the neuralnetworks,
theirperfor-mances are measured
by
randomly
generated
data ofknown distributions. 4.
Experimental
Setting
4.1 Distributions Considered
There are seven distinct distributions used in this
study:
Uniform,
Exponential,
Weibull, Gamma,
Log-normal,
Normal and Beta. These distributions arese-lected because
they
arefrequently
encountered insci-entific literature and real-life
applications.
Based onthe different
shape
parameters,
we use threetypes
ofWeibull,
Gamma andLognormal
distributions.Simi-larly,
eleven differenttypes
of Beta distribution areconsidered
corresponding
to differentshape
param-eters.
Totally,
23 distributions are used in theexperi-ments
(Table 2).
4.2. Neural Network
Types
and StructuresWe
initially
consider three neural networktypes:
back-propagation, counter-propagation
andprobabilistic
neural networks[28].
Based on extensivecomputa-tional
experiments,
however,
we eliminated theback-propagation
andprobabilistic
neural networks due totheir inferior
performance.
Hence,
wemainly
focus onthe
counter-propagation
network.A
counter-propagation
network constructs amap-ping
from a set ofinput
vectors to a set ofoutput
vec-tors
acting
as a hetero-associativenearest-neighbour
classifier
[29].
Itsapplications
includepattern
classifi-cation, functionapproximation,
statisticalanalysis
and datacompression.
When
presented
with apattern,
the trainedcounter-propagation
network classifies thatpattern
into aparticular
groupby
using
a stored reference vector;the
target pattern
associated with the reference vectoris then
output.
Theinput
layer
acts as a buffer. Thenetwork
operation
requires
that all theinput
vectorshave the same
length,
and henceinput
vectors arenormalized to one. As discussed in
[30],
counter-propagation
combines twolayers
from differentpara-digms.
The hiddenlayer
is a Kohonenlayer,
withcompetitive
units thatperform unsupervised
learn-ing.
Theprocessing
elements in thislayer
compete
such that the one with thehighest
output
is activated. Thetop
layer
is theGrossberg layer,
which isfully
interconnected to the hidden
layer.
Since the Kohonenlayer produces only
asingle
output,
thislayer
pro-vides a way of
decoding
thatoutput
into ameaningful
output
class. TheGrossberg layer
is trainedby
the Widrow-Hofflearning
rule.4.3 Network Construction,
Training
andTesting
As discussed in theprevious
section,
the work iscar-ried out in two consecutive
steps.
Step
1(Grouping
the Distributions):The distribution functions
(given
in Table2)
aregrouped
into sixcategories
based on theirshapes.
Theclustering techniques
orunsupervised
neural networkscould have been used for
grouping,
weperformed
thisstep
manually.
First,
we formedpreliminary
groupsvisually by
considering
theirgeneral shapes (e.g.,
Group
1represents
bell-shaped
distributions,
Group
2 consists ofright-skewed
distributions,
etc.).
Then welooked at
skewness, kurtosis,
quantiles
and cumula-tiveprobabilities
of these distributions and finalized thegrouping.
As can be seen inAppendix
1, skewnessand
quantiles
of the different groups differ from eachother,
whereas the distributions in each group havevery close
parameters
values.After
forming
the above groups, thetraining
set isprepared.
For this purpose, we use the UNIFIT-2Sta-tistics
Package
[31].
All thepossible
theoreticalsum-mary statistics for each of the 23 distributions are
in-vestigated
on theexperimental
basis in order to find theinputs
that are useful for the network todistinguish
among groups. After numerous
experiments,
skew-ness andquantile
information(measured
at sevendif-ferent
points)
are found to be the bestcharacterizing
statistics. Thetraining
set isgiven
inAppendix
1. Notethat some distributions in these groups are
duplicated
to form
equal-size
groups.Hence,
equal
numbers ofexamples
arepresented
to the network to achieve abalanced
training.
The
proposed counter-propagation
network haseight
neuronscorresponding
toeight
inputs
in thein-put
layer.
To determine the number of neurons in thehidden
(or Kohonen)
layer
is a difficult task and isusually
doneby
experimentation.
When there are toomany neurons, the network
memorizes,
and itsability
to
generalize
gets
weaker. On the otherhand,
using
too few neurons causes the network not to learn. Af-ter
carrying
out someexperiments
andconsidering
the above concerns, the number of
processing
units inthe Kohonen
layer
is determined to be fifteen. Thereare six neurons in the
output (or
Grossberg) layer
cor-responding
to six groups of distributions.The
counter-propagation
network issuccessfully
trained
(i.e.,
the root mean square(RMS)
errorcon-verged
tozero)
by
using
thetraining
setgiven
inAp-pendix
1.Specifically,
it learned all theexamples
inthe
training
set after5,000
iterations. In order to test the networkperformance,
a test set isprepared.
Foreach of the 23
distributions,
five raw data sets ofsample
size 100 arerandomly generated.
Theresult-ing
115 data sets areprocessed by
a Pascal programand are transformed into test
examples,
eachrepre-sented
by
one skewness and sevenquantile
values.When the test set is
presented
to the trained neuralnetwork,
it is observed that almost all testexamples
are
correctly
identified. The network fails foronly
three out of 115
examples.
Hence, at thisstage,
weconcluded that
Step
1 of theproposed procedure
issuccessfully
implemented.
Step
2 (Identification of Distributions):In the second
step,
we train a different neural net-work for five groups.(Since
the sixth group is uniformitself,
there is no need to train anetwork)
Each group has its own attributes
(characteristics).
Therefore,
identifying
different distributions within each group necessitates the use of differentinput
rep-resentation for each network. The
inputs
that are mostsuitable for each of the five groups are identified
ex-perimentally
in the same way as discussed inStep
1.The
training
set for each of the five groups isgiven
inAppendix
2.The
topology
of thecounter-propagation
networkvaries among groups. The number of
input
layer
neu-rons is determinedby
the number ofinputs
in thetraining
examples.
Also,
the number of neurons in the hiddenlayer
for each group is found on theexperi-mental basis.
Here,
we observed that it would besuit-able to use twice as many neurons as the number of
distributions to be identified in each group. The
num-ber of
output
neurons is determinedby
the number ofdistributions that form the groups.
All the five neural networks are
successfully
trained as the RMS errors converge to zero after 5,000 itera-tions. The trained networks are testedby
the samedata sets
generated
inStep
1.Again,
the raw data setsare transformed into
appropriate
testexamples by
the Pascalcomputer
program. The results of the tests arediscussed in detail in the next section.
5. Results
Having
trained the neural networkssuccessfully,
we measure theirperformances by
the test data sets ofsample
size 50, 100 and 500(a
total of 345 testexam-ples).
In
Step
1, when the test data sets arepresented
tothe trained
counter-propagation
network,
it identified the correctgrouping
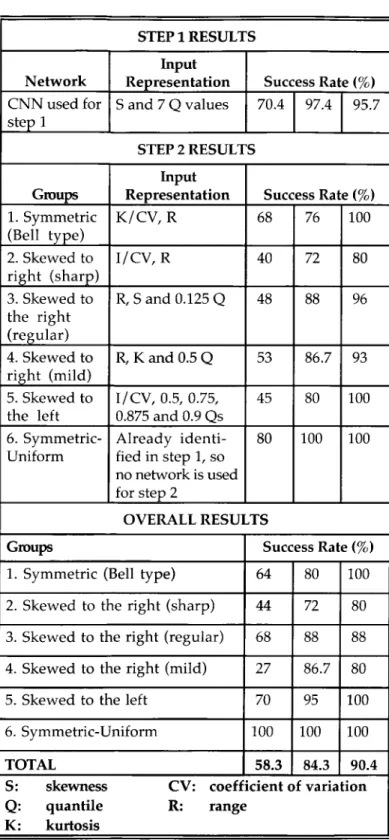
with 97.4% success(Table 3).
Allthe
examples,
whichbelong
toGroups
1, 3, 5 and theuniformly
distributed set(Group
6),
wereperfectly
categorized.
ForGroup
2, 24 out of 25 sets weresuc-cessfully
classified,
whereas the success rate was 13out of 15 for
Group
4.In
general,
we observed that the neural networkperformance
improves
assample
size increases(see
Table
3).
It can also be noted that the success rate inStep
1 ishigher
than inStep
2. This isexpected
because neural networks used inStep
2 have todistinguish
specific
distributions among similardistributions,
.whereas the neural network used in
Step
1just
classi-fies the distributions among more distinct groups.By examining
the results in Table3,
we cancon-clude that neural networks should not be
recom-mended for small
sample
sizes; the success rate of thetwo-step
neural networkapproach
is around 58% forTable 3. Test results for the neural networks
I I
successful,
consist ofmostly
beta distributions with differentshape
parameters.
Group
6(uniform)
is alsoa
special
type
of beta distribution. This means thatneural networks are
quite
successful indistinguishing
beta distributions. To some extent, the
ability
of theneural networks to
distinguish
the beta distribution from the others also continues forGroup
1(symmet-ric-bell
type).
It seems that the second group which includes
ex-ponential,
Weibull,
Lognormal
and Gammadistribu-tions, is the most difficult group for our neural
net-work
approach.
Note that this group consists of veryskewed distributions
(skewed
to theright)
whichap-parently
created agreat
deal ofdifficulty
for theneu-ral model.
Results also indicated that the
two-step
multiple
neural networkapproach proposed
in this paper ismore successful than the
one-step
single
neural net-workapproach
discussed in[20].
As seen in Table
4,
thepercentage
ofimprovement
by
thetwo-step
approach
is lowest for smallsample
sizes, moderate for
large sample
sizes andhighest
formedium
sample
size(n = 100).
The
multiple
neural networkapproach proposed
inthis paper and traditional
goodness-of-fit
tests(GFT)
are not
directly comparable,
because theproposed
ap-proach
is a meta model which selects a distribution forthe
given
data set(i.e.,
rejects
all the other candidate distributionfunctions),
whereas GFT is more ananaly-sis tool which tests if a candidate distribution is a
good
fit for the data set.
(This concept
is illustrated inFig-ure 3 where Di
represents
the i-th distribution functionand
Si
corresponds
to the i-thstep
of themultiple
neu-ral network
approach).
Whiledoing
that,
GFTmight
require
more than one iteration fortesting
candidatedistributions. It is also
quite
possible
that GFTmight
reject
the trueunderlying
distributions. In our case, forexample,
achi-square goodness-of-fit
testapplied
to data setsrejected
eleven and six distributions forsample
sizes 50 and100,
respectively.
This means thatthis
technique
is less reliable when thesample
size issmall.
Another
distinguishing
characteristic of the neural networkapproach
from GFT is that once a distributionis
selected,
other alternative distributions arerejected.
Figure
3. ANN versusgoodness-of-fit
testseasily
pass the test in the classical GFTapproach.
Hence,
the results of the GFT test may notalways
beconclu-sive. In that
respect,
GFT and neural networks shouldbe considered as
complementary techniques.
Specifi-cally,
the results of the neural network(i.e.,
distribu-tion recommendedby
the neuralnetwork)
can be usedby
the GFT to make more reliable andquicker
decisions.6.
Concluding
RemarksIn this paper, we
developed
amultiple
neural networkarchitecture to select
probability
distribution functions. The results indicated that themultiple
neural networkapproach
is more successful than theone-step
single
neural network
approach
inidentifying
distributions.In this
study,
we alsoanalysed
thestrengths
andweaknesses of neural networks relative to the tradi-tional GFT
approach.
Our conclusion is that theneu-ral networks can be
successfully
used in simulationinput
dataanalysis
as aquick
reference model. In thiscontext, neural networks can
complement
the functionof the traditional GFT
approach
(i.e.,
thesuggested
reference models can be furtheranalysed
by
thetradi-tional
methods).
Even
though
somegroundwork
has been estab-lished in this paper, there are several research issues that need to be addressed in future studies. First,neu-ral networks can be trained to act as a traditional GFT
(Figure
3(b)).
In this case, onespecial
neural networkis trained for each distribution function and is used to
accept
orreject
thehypothesis.
Second,
theperfor-mance of the neural network
approach
in thisprob-lem domain can be
improved by
using
different NNarchitectures.
Third,
unsupervised
neural networkscan be used to form the groups.
Finally,
neural net-works can be used inestimating
theparameters
of thedistributions. This may be a fruitful future research area for neural networks in the field of
probability
distribution selection.
7. References
[1] Vincent, S.G. "Input Data Analysis." In Handbook of
Simula-tion, J. Banks (ed.), pp 55-91, 1998.
[2] Law, A. and Kelton, W.D. Simulation Modeling and Analysis,
Second Edition, McGraw-Hill, 1991.
[3] Banks, J., Carson, J.S. and Nelson, B.L. Discrete Event System
Simulation, Second Edition, Prentice- Hall, 1996.
[4] Bratley P., Fox, B.L. and Schrage, L.E. A Guide to Simulation,
Second Edition, Springer-Verlag, New York, 1987.
[5] Shanker A., and Kelton, W.D. "Empirical Input Distributions:
An Alternative to Standard Input Distributions in Simulation
Modeling." Proceedings of the 1991 Winter Simulation
Confer-ence, B.L. Nelson, W.D. Kelton and G.M. Clark (eds.), pp
978-985, 1991.
[6] Vincent, S.G. and Law, A.M. "Unifit II: Total Support for Simulation Input Modelling." Proceedings of the 1992 Winter Simulation Conference, J.J. Swain, D. Goldsman, R.C. Crain and J.R. Wilson (eds.), pp 136-142, 1991.
[7] Vincent, S.G. and Kelton, W.D. "Distribution Selection and
Validation." Proceedings of the 1992 Winter Simulation
Confer-ence, J.J. Swain, D. Goldsman, R.C. Crain and J.R. Wilson
(eds.), pp 300-304, 1992.
[8] Johnson, M.E. and Mollaghasemi, M. "Simulation Input Data Modelling." Annals of Operations Research, Vol. 53, pp 47-75,
1994.
[9] Banks, J., Gibson, R.R., Mauer, J. and Keller, L. "Simulation
Input Data: Point-Counterpoint." IIE Solutions, January 1998,
pp 28-36, 1998.
[10] Sharda, R. "Neural Networks for the MS/OR Analyst: An Ap-plication Bibliography." Interfaces, Vol. 24, pp 116-30, 1994.
[11] Marquez, L.O. "Function Approximation Using Neural
Net-works : A Simulation Study." PhD Dissertation, University of
Hawaii, Honolulu, HI, 1992.
[12] Lapeds, A. and Farber, R. "Nonlinear Signal Prediction Using
Neural Networks: Prediction and System Modeling."
LA-UR-87-2662, Los Alamos National Laboratory, Los Alamos,
NM, 1987.
[13] Sutton, R.S. "Learning to Predict the Method of Temporal
Differences." Machine Learning, Vol. 3, No. 1, pp 9-44, 1988.
[14] Ali, D.L., Ali, S. and Ali, A.L. "Neural Nets for Geometric
Data Base Classifications." Proceedings of the SCS Summer
Simulation Conference, pp 886-890, 1988.
[15] Pham, D.T. and Oztemel, E. "Control Chart Pattern Recogni-tion Using Neural Networks." Journal of Systems Engineering, Vol. 2, pp 256-262, 1992.
[16] Udo, G.J. and Gupta, Y.P. "Applications of Neural Networks
in Manufacturing Management Systems." Production Planning and Control, Vol. 5, No. 3, pp 258-270, 1994.
[17] Sabuncuoglu, I., Yilmaz, A. and Oskaylar, E. "Input Data
Analysis for Simulation Using Neural Networks." In
Proceed-ings of the Advances in Simulation ’92 Symposium, A.R. Kaylan and T.I. Ören (eds.), pp 137-150, 1992.
[18] Akbay, K.S., Ruchti, T.L. and Carlson, L.A. "Using Neural Net-works for Selecting Input Probability Distributions."
Proceed-ings of ANNIE’92, 1992.
[19] Aydin, M.E. and Özkan, Y. "Da∂ylym Türünün Belirlenmes-inde Yapay Sinir A∂larynyn Kullanylmasy." Proceedings of the
First Turkish Symposium on Intelligent Manufacturing Systems,
pp 176-184, 1996.
[20] Yilmaz, A. and Sabuncuoglu, I. "Probability Distribution Se-lection Using Neural Networks." Proceedings of the European Simulation Multiconference ’97, 1997.
[21] Hashem, S. and Schmeiser, B. "Improving Model Accuracy
Using Optimal Linear Combinations of Trained Neural
Net-works." IEEE Transactions on Neural Networks, Vol. 6, No. 3,
pp 792-794, 1995.
[22] Rogova G. "Combining the Results of Several Neural Network Classifiers." Neural Networks, Vol. 7, No. 5, pp 777-781, 1994.
[23] Jordan, M.I. and Jacobs, R.A. "Hierarchical Mixtures of
Ex-perts and the EM Algorithm." Neural Computation, Vol. 6,
pp 181-214, 1994.
[24] Boers, E.J.W. and Kuiper, H. "Biological Metaphors and the
Design of Modular Artificial Neural Networks." Masters
Thesis, Departments of Computer Science and Experimental
and Theoretical Psychology at Leiden University, The
Neth-erlands, 1992.
[25] Hashem, S. "Optimal Linear Combinations of Neural
Net-works." Neural Networks, Vol. 10, No. 4, pp 599-614, 1997.
[26] Yang, S. and Chang, K. "Multimodal Pattern Recognition by Modular Neural Network." Optical Engineering, Vol. 37,
No. 2, pp 650-659, 1998.
[27] Chen, K., Yang, L., Yu, X. and Chi, H. "A Self-Generating
Modular Neural Network Architecture for Supervised
Learning." Neurocomputing, Vol.16, pp 33-48, 1997.
[28] Bose, N.K. and Liang, P. Neural Network Fundamentals with
Graphs, Algorithms, and Applications, McGraw-Hill, 1996.
[29] NeuralWare, Inc. Neural Computing, Pittsburgh, 1991.
[30] Hecht-Nielsen, R. Neurocomputing, Addison-Wesley, 1990.
[31] Law, A. and Vincent, S.G. Unifit II User’s Guide. Averill M. Law & Associates, Tucson, AZ, 1994.
Appendix
2:Training
Sets forStep
2 Anil Yilmaz is an expert at the Turkish PrimeMinistry-Undersecretariat of the State
Plan-ning
Organization.
He received aBSc
degree
in IndustrialEngineer-ing
and an MAdegree
inEconom-ics from Bilkent
University
inTur-key.
He has been associated with theplanning
ofpublic
investments,project appraisal,
and investmentanalysis
andmonitoring.
Yilmaz iscurrently
working
as theCounsel-lor to the
Undersecretary.
Ihsan
Sabuncuoglu
is an AssociateProfessor of Industrial
Engineering
at Bilkent
University.
He receivedBS and MS
degrees
in IndustrialEn-gineering
from Middle East Techni-calUniversity
and a PhD inIndus-trial
Engineering
from Wichita StateUniversity.
Dr.Sabuncuoglu
teaches and conducts research in the areas of neural networks,
simu-lation,
scheduling,
andmanufactur-ing
systems. He haspublished
pa-pers in l1E 1’ransactions, International
Journal
of
Production Research, Journalof
Manufacturing
Sys-tems, International Journalof
FlexibleManufacturing Systems,
InternationalJournal
of
Computer Integrated
Manufacturing,
Computers
andOperations
Research,European
Journalof
Opera-tional Research, Production
Planning
and Control, Journalof
Operational
ResearchSociety,
Computers
and IndustrialEngi-neering,
International Journalof
Production Economics,journal
of Intelligent Manufacturing
and OMEGA-InternationalJour-nal
of Management
Sciences. He is on the Editorial Board ofJournal
of Operations Management
and International Journalof
Operations
and QuantitativeManagement.
He is an associatemember of Institute of Industrial