Incorporating the surfing behavior of web users into PageRank
Tam metin
Şekil
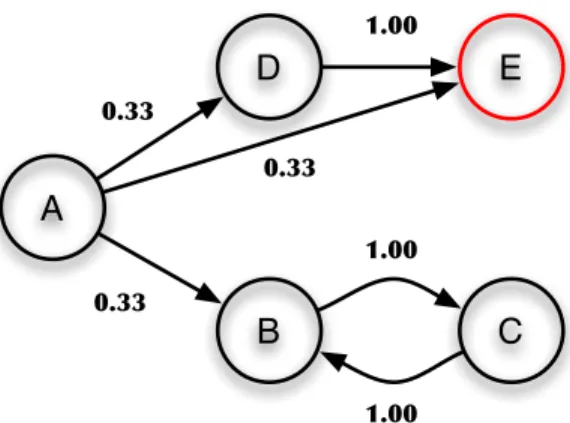
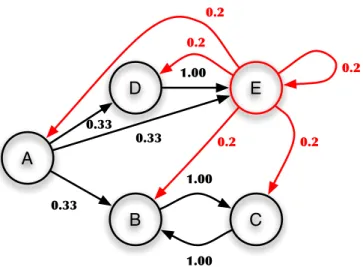
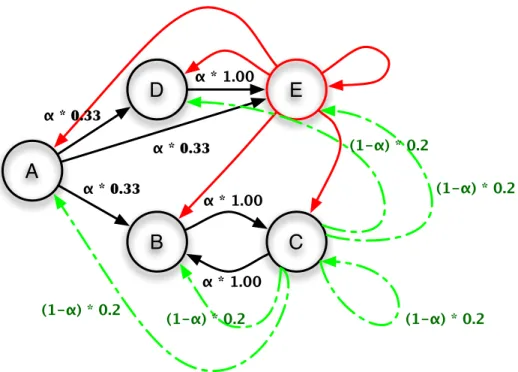

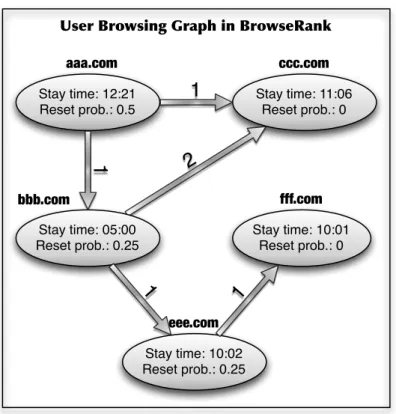



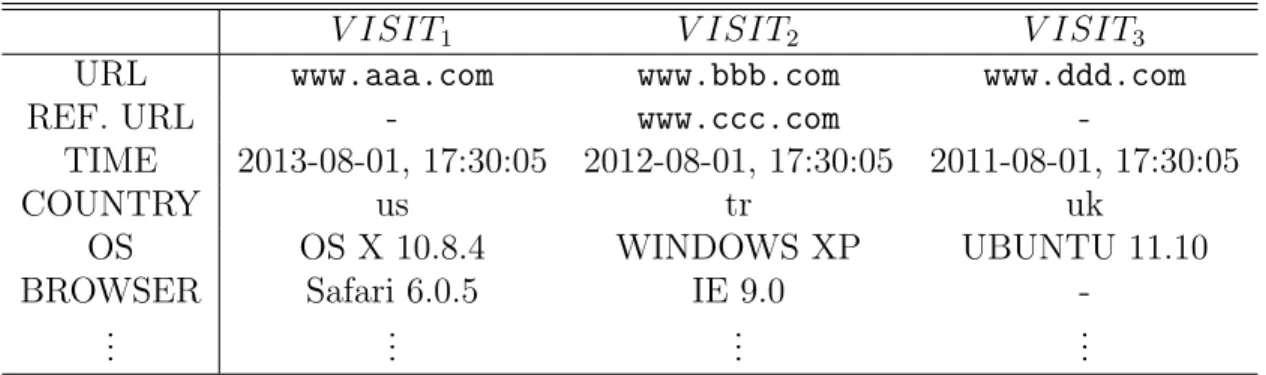
Benzer Belgeler
In the methods we have applied so far in order to determine the relation between the atmospheric temperature and the pressure by using the annual average and amplitude
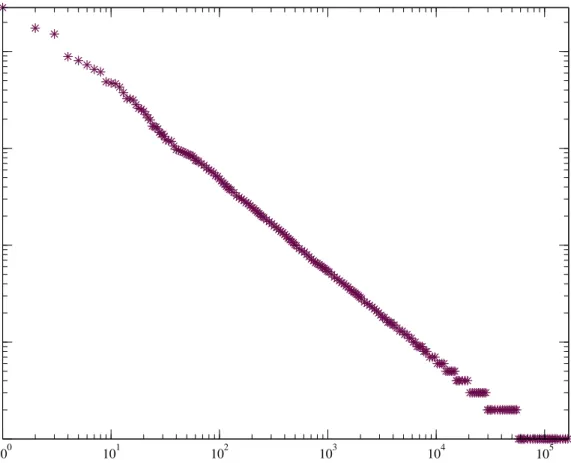
We proposed a novel model for computing web page im- portance scores by using a mixture of the feedback extracted from the hyperlink structure of the Web and the feedback obtained
CBT’s Interest Rate Announcements – Original EDDS Access Counts Upper: Difference between Pre-event – Post-event Levels.. Lower: Difference between Pre-event –
As far as the method and procedure of the present study is concerned, the present investigator conducted a critical, interpretative and evaluative scanning of the select original
To create the graphs of the existing variables, go to the graph drop-down menu and choose bar option and click simple option in the bar chart box (See Figure 6) and then
This paper presents a data-centric analysis of commercial on-shore wind turbines and provides actionable insights through analytical benchmarking through Data
yaşgünü mutluluğunu Başbakan Ozal, ken disini salon girişinde karşılayan gazetemiz sahibi Erol Si- mavi’yi öpüp, ‘Kutlarım.... Buruk gece,
Beyaza boyanan Karadeniz yolcu gemisi İstanbul’dan ayrıldık tan sonra önemli limanlara uğraya rak Akdeniz’i aşacak, sonra da Ce belitarık’tan Atlantik’e
