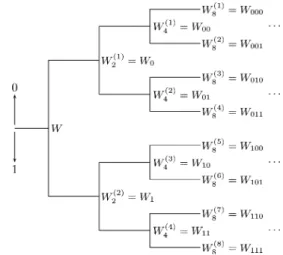
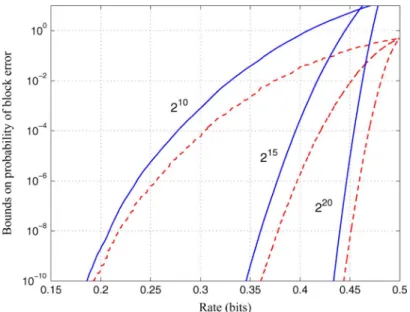
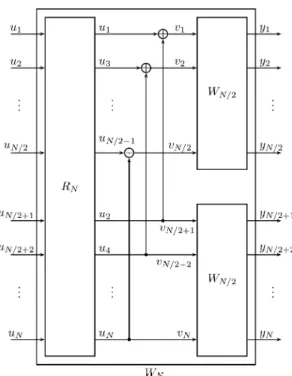
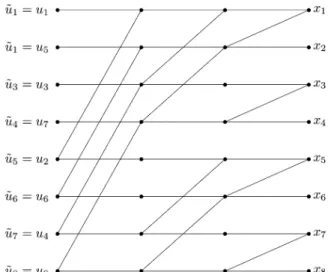
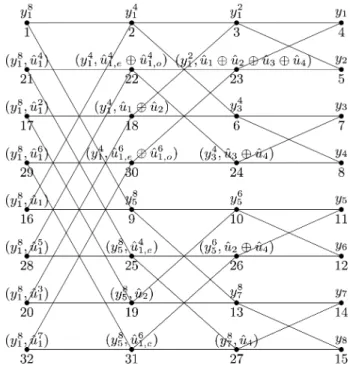
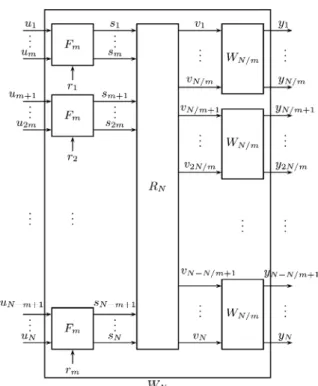
Channel polarization: A method for constructing capacity-achieving codes
Tam metin
Şekil
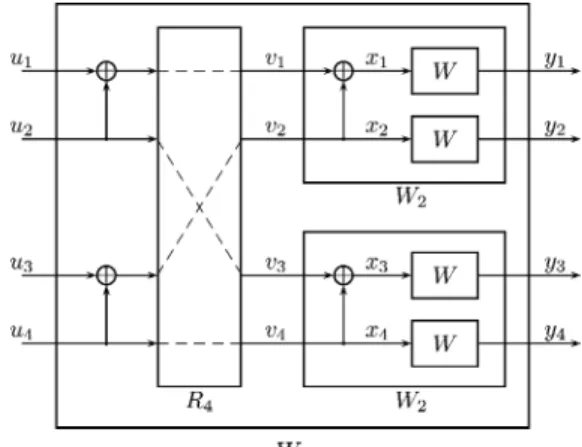
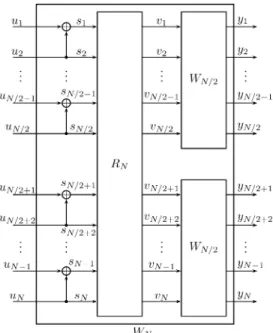
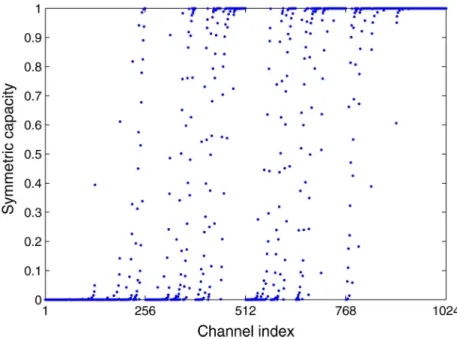
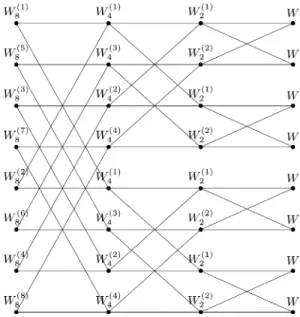
Benzer Belgeler
The autonomy of the female self in late 19 th century and freedom from marriage are some of the themes that will be discussed in class in relation to the story.. Students will
It can be read for many themes including racism, love, deviation, Southern Traditionalism and time.. It should also be read as a prime example of Souther Gothic fiction and as study
Mr Irfan Gündüz started his speech by stating that the Istanbul Grand Airport (IGA) is aimed to be opened in the beginning of 2018.. He further stated the new airport project
The turning range of the indicator to be selected must include the vertical region of the titration curve, not the horizontal region.. Thus, the color change
The other tourism villages and tourism destinations in Northern Cyprus might resist to development plans for a new tourist destination due to possible competition,. Market
The reason behind the SST analysis at different time interval is based on the concept that it should not be assumed that the system will behave properly
Overall, the results on political factors support the hypothesis that political constraints (parliamentary democracies and systems with a large number of veto players) in
We preferred intravenous levetiracetam (LEV) for quickly managing the symptoms because intravenous diazepam and phenytoin administrations failed to control the focal motor status
