Gibbs model based 3D motion and structure estimation for object-based video coding applications
Tam metin
Şekil
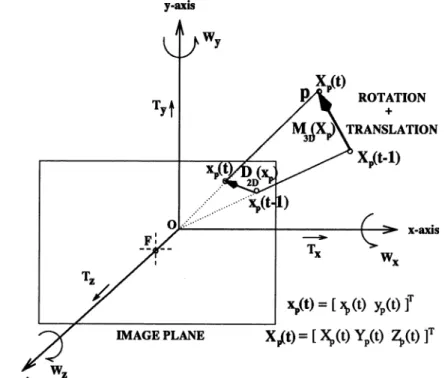
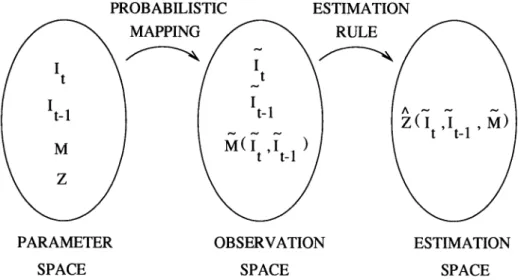




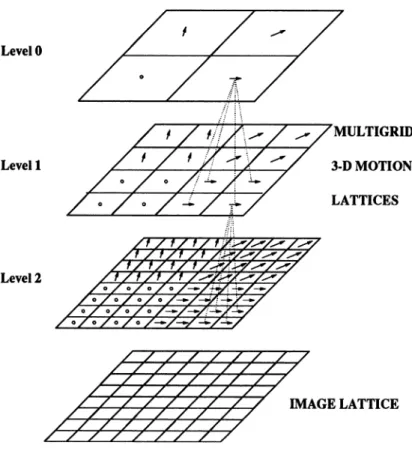

Benzer Belgeler
We also proposed a vector prediction based fast motion estimation algorithm for reducing the energy consumption of H.264 MVC motion estimation hardware by utilizing the
While we find no obvious candidates in human low and mid-level visual cortex for an explicit representation of specular reflectance from motion, we do find several areas with
We studied human-in-the-loop physical systems with uncertainties due to failures and/or modeling inac- curacies, a set-theoretic model reference adaptive control law at the inner
To select the required machine precision for any MP-MLFMA tree structure, as well as to control the translation errors due to the truncation of the diagonal form of the
Figure 5.10: Original average target ERP signal a, composite time–frequency representation obtained by TFCA b and estimated individual time–domain components c and d for the
AMD, cis its name implies, is an algorithm which finds the average motion between two video frames and thus finds the amount of change within two frames. In
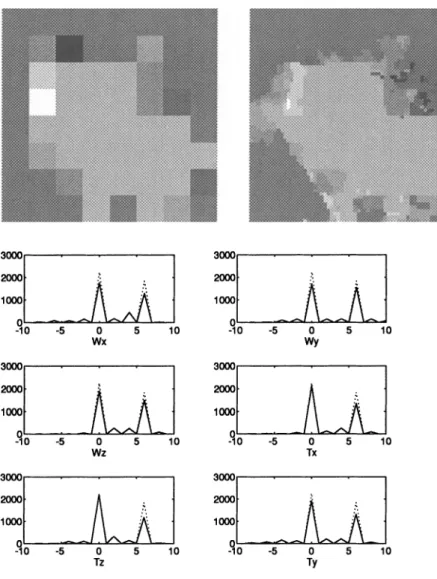
To see how the algorithm behaves in case of large motion, we increase u>x and plot the percentage estimation error in versus ujx with considering the
Patients (Expanded Disability Status Scale [EDSS] score ≤4.0; disease duration ≤10 years; discontinued prior DMT of ≥6 months’ duration due to suboptimal disease control)
