Journal of Computational and Applied Mathematics
Tam metin
Şekil
Benzer Belgeler
A next step is the construction of the distribution of the concomitants of order statistics for the presented Pseudo–Gompertz distribution and the derivation of the survival and
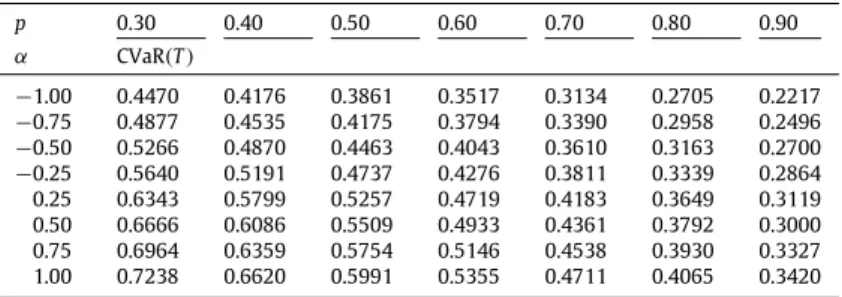
Joint probability function for the variables of surplus immediate before ruin, deficit at ruin and time to ruin is obtained and potential applications of it are discussed. It
The results are applied to reliability analysis of coherent systems consisting of components each having two dependent subcomponents and to insurance models where the losses
The proposed bivariate pseudo-Gompertz distribution has the complacency for the survival and hazard modeling and their extensions to the applications besides reliability analysis
Aşağıda yer verilen Tablo 7’de üçüncü sınıf düzeyinde iki farklı yayın evine ait matematik ders kitabında yer alan sosyal değerlere ait bulgulara yer veril-
Elde edilen bulgulara göre İLİTAM programında öğrenim gören öğrencilerin bu programı tercih nedenlerinin sırasıyla din ile ilgili konularda bilgi sahibi
Но в этот плохо организованный поход османские армии потерпели c поражение, и, хотя спасение Астраханской крепости и казанских ханов не
In a mixed method study, in which social network analysis and discourse analysis were used, the research revealed that different layers of the community demonstrated a
