Analysis of "SIR" ("Signal"-to-"Interference"-Ratio) in discrete-time autonomous linear networks with symmetric weight matrices
Tam metin
Şekil
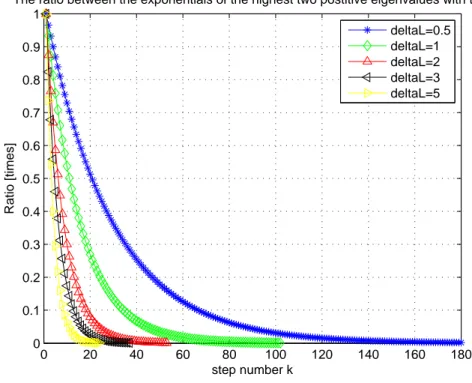
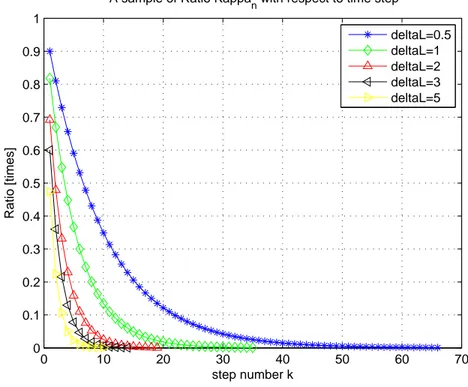
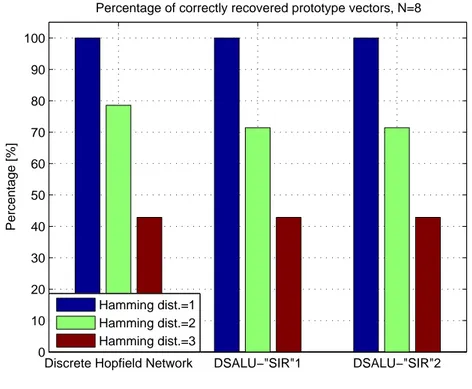
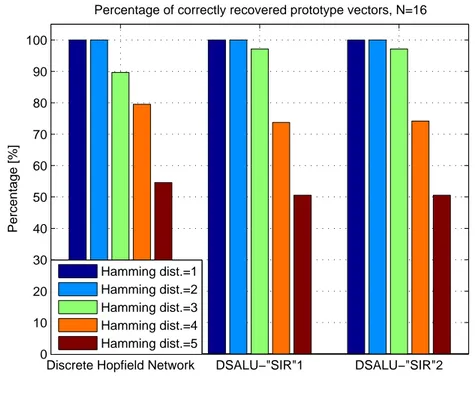
Benzer Belgeler
Günümüzde genel olarak Avesta’nın en eski metinlerinin Yasna bölümünde yer alan Gāthālar olduğu, Yaştlar, Visperad ve Vendidad gibi bölümlerin daha sonraki
‹ngiliz-Alman- Frans›z f›kra kal›b›n›, etnik sald›rganl›k veya etnik stereotipler içeren bir kal›p- tan çok, çeflitli f›kralar üretilebilmesine imkan veren
obtained using late fusion methods are shown in Figure 5.7 (b) and (c) have better result lists than single query image shown in (a) in terms of, ranking and the number of
fermAnım olmuşdur huyurum ki hükm-ü şerifimle vardıkda bu b~bda sAdır olan emrin üzere 'Amel idüb daht sene-i merkOma mahsOb olmak üzere livA-i mezbO.rda
Elevated C-re- active protein levels and increased cardiovascular risk in patients with obstructive sleep apnea syndrome. Szkandera J, Pichler M, Gerger A, et al (2013b)
Accordingly, when patients with cellulitis were divided into two groups as ≥65 years and <65 years, a statistically sig- nificant difference was noted among the WBC, NLR, and
Now depending on the object ( HAND/FINGER ) detected on each sensor the single-channel motor driver associated with one of the motors of the wheel decides the direction
Öyle ki bu bölümde en çok yer kaplayan edebi metin olan “Tramvayda Gelirken” tam da bu kurgusu dolayısıyla Nazım Hikmet’in (ö. 1963)Memleketimden İnsan Manzaraları ile
