Sleep scheduling for energy conservation in wireless sensor networks with partial coverage
Tam metin
Şekil

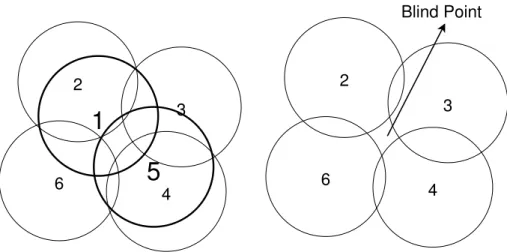
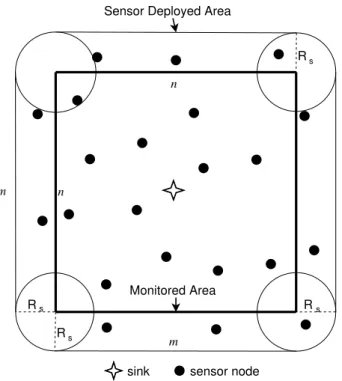
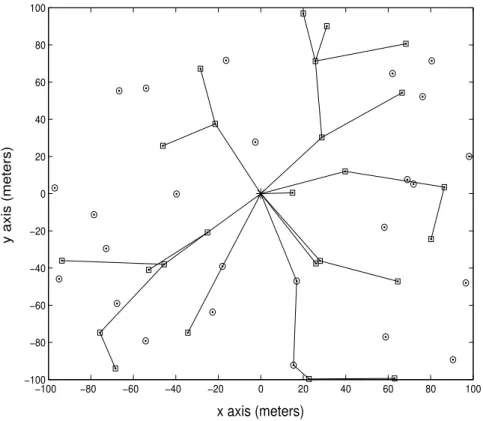


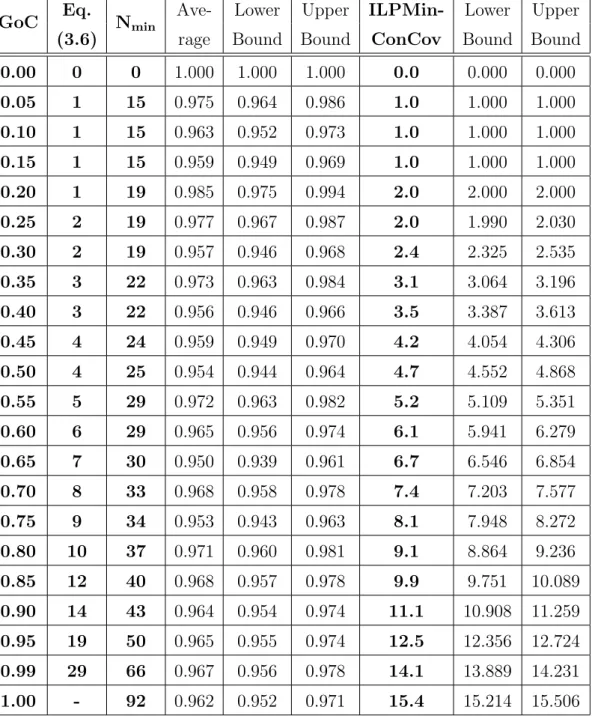
Benzer Belgeler
Bunu da zaten, ye teri kadar açık bir şekilde söyledi: ‘ ‘En başta annemin, üzerinde çok emeği olan Doğan 'in tahsilinde de benim ve eşimin önemli yardımları
By controlling the sleep and active time based on remaining energy of sensor nodes we can save more power for sensor nodes so the life time of the entire wireless
An increase in the temperature from 325 to 350 ⬚C is critical for the product distribution from hydrocracking of MeDec over Pd/REX.. Spectroscopic analyses of gaseous and
Consequently, it is of interest to extend M AC OO design problems in hydrody- namic lubrication to a setting where homogenization theory is used to reflect the influence of
For the first time, in this work we present the design, growth, fabrication, integration and characterization of hybrid CdSe/ZnS core-shell nanocrystals based white light
We shall first present the continuous form of the metric for a spherical shock wave that is obtained from the above process of identification with warp and then comment on
Açlık kan şekeri, bazal insülin, trigliserid ve HOMA değerleri metabolik sendromlu hastalarda kontrol grubuna göre yüksek bulundu.. An- cak HDL kolesterol değeri kontrol
