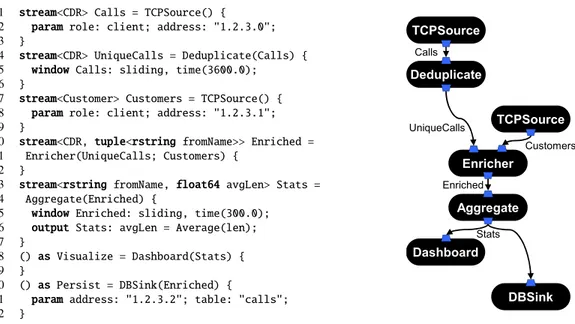
Language runtime and optimizations in IBM streams
Tam metin
Şekil
Benzer Belgeler
We first examined 7,804 small deletions for breakpoint complexity using split-read analysis 23 (Fig. 3c) and identified 664 (median size 67 bp) exhibiting complexity, 64 of
Experimental photovoltage buildup results of photosensitive NC skins at different excitation wavelengths and intensity levels based on (a) a single layer of NCs, (b) fi ve layers
The arguments in the book are based on the public surveys and data that Taylor received from Pew Research Center, an indepen- dent think that provides knowledge and data in
The implemented forces, which have an impact on the motion of the hair strands, are spring forces, grav- ity, repulsions from collisions (head and ground), ab- sorption (ground
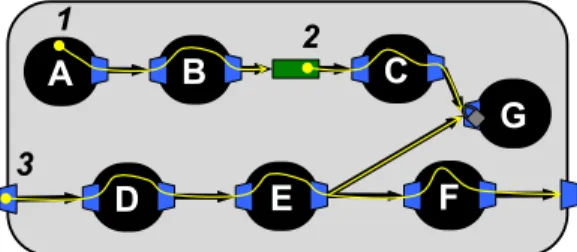
Each translation exposes implicit state and communication as explicit variables and queues, respectively; exposes a mecha- nism for implementing global determinism on top of
Ideally, a warm-start strategy should use a relatively advanced iterate of the un- perturbed problem to compute a successful warm-start especially for smaller pertur- bations and
Millî Mücadelede giydiği res mî elbise, kalpağı, çizmesi, foti ni, Sivas Kongresinde üzerinde bulunan caket, Büyük Nutkunu okuduğu zaman giydiği Redin
The increasing urban growth in the city has led to an unsustainable urban expansion, and therefore this paper aims at the possibility of adapting city centers to the conditions
