Bulanık sayıların sıralanması
Tam metin
Şekil

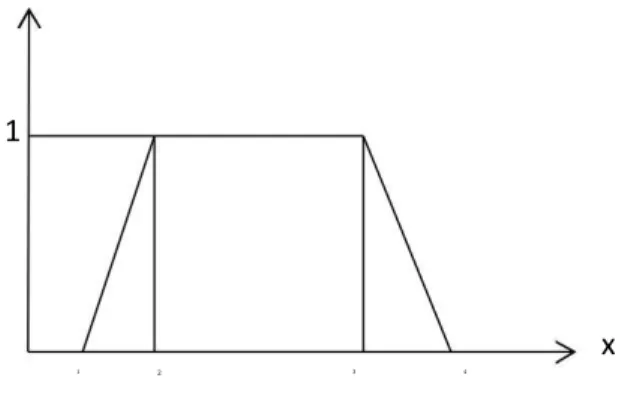


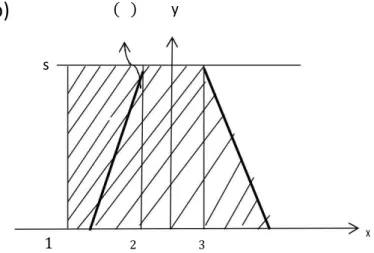
Benzer Belgeler
Sonuç olarak unutulmamasý gereken nokta; ilk atak manide veya sadece tekrarlayan manik ataklarla baþvuran hastalarda tanýnýn bipolar bozukluk deðil unipolar mani de olabileceði
Özbekistan’da ise önceleri hakim bir devlet partisi olarak öne çıkan Ulusal Demokratik Parti (UDP), daha sonra Cumhurbaşkanı İslam Kerimov’un istekleri doğrultusunda
[r]
A concise synthesis of denbinobin is described via an intramolecular free radical. cyclization and Fremy s salt mediated oxidation as a
Mustafa Kemal Paşa’yla Claude Farrere öğle ye meğini birlikte yediler.. Musta fa Kemal Paşa, toplanan üç bin kişi önünde hak sızlığa uğrayan Türklerin
rakan İstanbul Devlet Opera ve Balesi, sezon boyunca 42 bale 88 opera temsili olmak üze re, 22 değişik eseri 130 gösteri şeklinde sun du.. 1986-1987 repertuarında
Türkiye ekonomisi de dış kaynak kullanımlı bir ekonomidir (Kazgan, 1999). Dolayısıyla, Türkiye ekonomisinin bu yapısını dikkate almadan faizi bir politik araç
Hatta bütün bu zihinsel işlemler yapılırken bunlarla birlikte aynı zamanda tümevarım (induction) işlemi de kullanılır. Zaten tümevarımın anlamı tekil durumlardan
