Kısmi En Küçük Kareler Regresyon Yöntemi Algoritmalarından Nipals ve PLS - Kernel Algoritmalarının Karşılaştırılması ve Bir Uygulama
Tam metin
Şekil
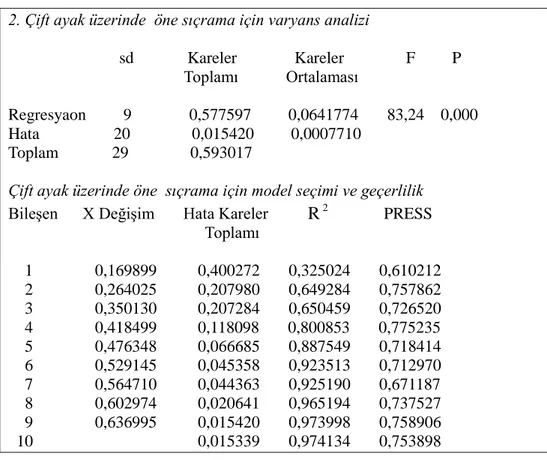
Benzer Belgeler
Ma tematik öğretmenliği programı iki kısımdan oluşturulmalı, birinci kısımda be lirlenen matematik (alan bilgisi) derslerini öğretmen adayı, eğitim
Deniz Türkali'nin kızı Zeynep Casalini, Sezen Aksu konserinde bir gecede şöhret oldu?. “Annem çok az
parçalanması Bir arazi kullanım türünde km²’deki bölücü unsurun uzunluğu (km) Ulaşım ve diğer teknik altyapı unsurları Tür populasyonunda azalma
Frog α M appeared to represent this critical divergent stage, and will provide us with further evolutionary informations.To analysis of the subunit structure of α2M from
Ahmed Anzavur'un altm~~~ kadar `avenesiyle Gönen'in S~z~~ karyesi ci- vânnda oldu~u istihbar edilmesi üzerine mümâileyhe kar~~~ Gönen'deki ni- zamiye kuvvetiyle Kuvay-~~ Milliye
İnsülin pompasış eker hastaları için ne anlama geliyorsa, bedene bağlı, giyilebilen otomatik, yapay böbrek de bir gün diyaliz hastaları için aynı anlama gelecek.. Clinical
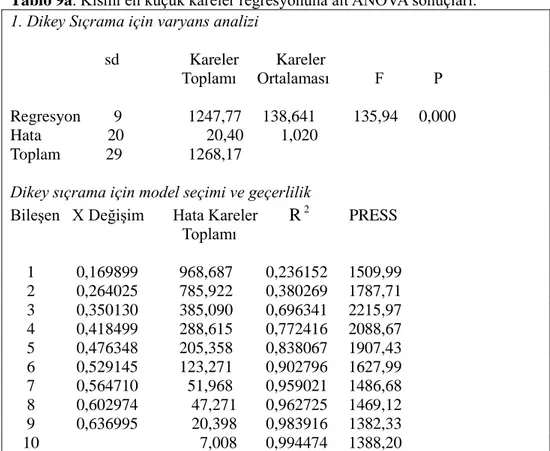
• Tahmin sonrası açıklanmaya çalışılan değerler ile bunu açıklayan değerler şapka (^) ile yazılırsa regresyon tahmin modeli elde edilmiş olur.. • Tahmin
The customer service quality in regards to reliability also does not meet customer’s expectations from hypermarkets in Oman because the reliability dimension has
