Fatin SEZGiN*
Introduction
Whether for assessment of the present situation or for satisfaction of academic curiosity, whether for understanding problems and proposing solutions, it is necessary to obtain consistent ideas and put forward correct diagnoses on the state of Turkish language. As in all other fields, it is necessary to depend on data and analysis that is the common characteristic of all branches of science in order to reach sound inferences and avoid subjective discussions that lead nowhere. As it is not possible to reach correct results by the use of common sense without applying Statistics and mathematical formulae to the data obtained by suitable methods, it is also impossible to substitute only a skillful manipulation of data relying on statistical methods for common sense. Therefore it is essential to choose suitable data for clarification of the subject and representation of the subject population. One must apply the most appropriate analytical methods on the data and must adhere to common sense and logic in the process of inference.
There are earlier studies carded out by various authors who rely on numerical evaluations. But most of them are oriented to prove the success of efforts to purify the language and generally overlook Western loan-words. Moreover, these studies contend with giving tabular and percentage representations of data and do not attempt hypothesis testing and statistical evaluations in interpretation of results. Due to methodological errors of sampling procedures texts chosen by some researchers belong to different fields and forms, therefore their compadson leads to unreliable results.
This study deals with the density of Western loan-words in Turkish with respect to time based on numerical data. For this aim a long etymological study is carried out, and later on at the end of investigations taking nearly thirty years text samples from 561 novels of 82 of our novelists are studied. The analysis of a data of this volume has been feasible only by the use of computer. At the end of this most comrehensive study in the area, the Western loan-words obtained are coded in the IBM 4381 mainframe computer of Atatürk University Computer Science Research and Application Center with respect to the year, author and novel of the sample texts to which they belong. Words of different kinds are determined and ordered alphabetically by our computer programs wdtten in Fortran-77, furthermore by the use of
statistical analyses the increases and decreases of proportions of foreign words as a whole and different languages are investigated respectively and represented by suitable equations as a function of time.
The study first deals with the historical trend of western loan-words by an overall evaluation of the situation that evoled since our settlement in Anatolia. The period following Tanzimat in which the concentration started to increase significantly is studied in detail and rates foreign words in Turkish novel are described by tables and graphs. In these explanations technical details are reduced to a minimum and contented with presentation of results.
Historical Trend Of Western Loan-Words In Turkish
In exploring the historical course of western loan-words in Turkish, it is necessary to study various periods starting from the first era of settlement of Turks in Anatolia up to the present day. But the number of ancient texts is quite limited in our society where oral communication prevails. Therefore it does not seem possible to go back to early pedods in a study aiming comparative numeric evaluations. This necessitated using only some descriptive expressions about these periods. It may be said that only the arrival of printing eased the analytical work. Hence in recent periods, it is possible to determine which foreign words appeared and which foreign words disappeared in certain years. The alienation process of our language in Western direction may be summarized under three headings: The First Era, Ottoman Time After Stationary Period and the Republican Era.
First Era
The language of every nation has been in a continous interaction with other languages throughout history. After the conversion of Turks to Islam, the impact of Arabic and Persian increased in the language. By the adoption of Anatolia as the homeland, it had not been possible to avoid effects of languages of local nations and people.
As summadzed by Özön (1962) and Korkmaz (1995) with the settlement of Eastern Anatolia in eleventh century, numerous words started to enter to our language from the Greeks and Armenians situated within Byzantine Empire. In this way, names of several objects and concepts which did not exist in nomadic life entered our language. In the following centuries, in addition to words related to architecture and environmet of settled life-style, several names of newly met fruits, vegetables and other foods are adopted. After the emergence of the Ottoman Empire in the fourteenth century, by expansion to Rumeli and lands further to north, Serbs, Slavs, Hungadans, Romen and Germans speaking people were encountered, while expansion to Black Sea and Mediterranian coasts brought contact with Genoese, Venetian, Portugese and Spanish peoples. From the languages of all these people and nations words entered to Turkish. Several words related to sailing and commerce are transferred from Italian through relations with Genoese and Venetians.
Among these words, the operative ones were assimilated and adapted to the sound structure of our language through the centuries to such an extent that they can be identified as foreign words only after etymologic inspection. In this context the following examples may be mentioned related to construction and housing: anahtar, avlu, badana, bodrum, iskemle, kalas, kanepe, kerevet, kiler, kilit, kiremit, kodes, kulube, kümes, manastir, mandira, masa, mazgal, mermer, mertek, mobilya, moloz, salag, temel, tente, tugla. Examples of plant, vegetable,
fruit and food names are: ahlat, ananas, bezelye, bogaça, cacik, çagla, çemen, çerez, defne, fasulye, findik, fidan, francala, havyar, lhlamur, lspanak, lstakoz, karanfil, ka§ar, kenevir, kestane, kiraz, kumanya, lahana, lapa, leylak, limon, lüfer, marul, midye, mu§mula, palamut, pancar, papara, papatya, peksimet, pirasa, pide, pirzola, portakal, reciñe, salça, simit, somun, uskumru. While the following are taken related to dress and finery: çuha, elmas, fanila, kanaviçe, kopça, kundura, patik, pirlanta, §ayak, takunya, tela, uruba; the following names are taken for various tools and objects: bastón, bavul, billur, cendere, cimbiz, civata, capa, çelenk, fener, fiçi, firça, gocuk, haç, halat, harita, huni, ígrip, ísgara, kama, kandil, kasatura, kerata, kinnap, kukla, kulp, kumbara, kutu, lamba, mandai, mancinik, manivela, masura, mengene, miknatis, misket, olta, pulluk, pusula, sabun, sini, soba, susta, sünger, tabaka (for tobacco), tabla, tapa, tasma, tela, teneke, tirpan, tulumba, üsküf, varil, varyos, vida, vinç. Some of these loan-words reached our language from Greek and Latin via Arabic and Persian. For this reason their etymology is disputed such as: Billur, çerez, çuha, elmas, fener, firm, tavla, tavus. Following the Jewish immigration from Spain to the Ottoman Empire after the 16th century several Spanish and Italian words entered related to semantic fields of medicine and commerce. In the same century a serious French influence on Turkish started to appear as a result of friendly relations established with France through capitulations. Even after Tanzimat the general perception of West was consisted of France. Several educated and noble people were closely acquainted with the culture and language of this country. Even today most of the Western loan-words are used according to their pronunciation in French. Only with the emergence of a heavy American influence has this rule begun to be violated.
Because of their subjects. Popular, Divan and Sufistic literatures were not suitable for the usage of Western origin words. For example in Yunus Emre, a few well assimilated and familiar Greek originated words are met, such as kandil, mermer, poyraz. Rum, sinir and badya which closely resembles the Persian word 'bade'. As a poet dealing more with worldly subjects Karacaoglan has more Western words: Agustos, avlu, billur, çerez, efendi, elmas, fener, findik, firtma, furun, fidan, firenk, hoyrat, kandil, karanfil, kiral, kiraz, kutu, mermer, Nemse, patrik, portakal, poyraz, tavla, tavus, tiil. Except the French word tiil all others are of Latin, Italian, Greek and Slavic origin.
Retrogression Era And Aftermath
By the start of the retrogression era, the admiration felt towards Western civilization caused the consideration of the foreign language knowledge and usage of words from these languages as a merit. The Ottoman Empire, which remained formerly indifferent to European countries, later started to send ambassadors. Ambassadorial chronicles narrating France, Germany and Russia contain numerous foreign words. Among these chronicles those of Yirmisekiz Mehmet Çelebi, Resmî Efendi and Nahifî Efendi must be mentioned. §im§ir (1992) gives general information on these relations which started at political field and gradually shifted towards culture: Ottoman Empire, having only flve embassies in foreign countries until Tanzimat, opened nine more in this period and sent ambassadors to almost all European capitals and the United States of America. The number of these embassies expanding rapidly, reached 48 in the Islands of Great Britain and 52 in Italy. Even on a single island, Sicily, 9 Ottoman consulates were open. In the Ottoman Ministry of Foreign Affairs and Ottoman foreign envoys Latin alphabet is used. Our diplomats begin to use French not only in
their correspondence with foreigners but also among themselves. The official language of Foreign Affairs becomes French. As 1856 Pads Treaty declared that Ottoman Empire would benefit from European law. Empire was officially and juddically accepted among European states. From now on Ottoman representatives begin to attend to almost every meeting at Europe. Western languages are being learned, students are sent, technicians are being accepted from there. By these frequent relations French spreads as a second language in Ottoman Empire.
Before the year 1727, foundation date of pdnting houses, word transfers were mainly in spoken language and remained local. By possibilities provided by pdnting houses, the wdtten language started to play a more prominent role in introduction of foreign words to the language and their propagation. The effect of wdtten language started to be felt more strongly by orientation of several state institutions and intellectuals to the West. Shortly before the declaration of Tanzimat a Traduction Office was established in Babiali and western works of thought and literature started to be translated into our language. Through these works words having no corespondent in our language vere introduced. New litterary types such as novel, play and critics were bringing different ideas and thoughts with them. Since 1831 our society became familiar with newspaper. During 187O's these litterary types, in conjunction with the dsing interest in society towards Western culture, caused a new speedy alienation in language as they were published and spread via newspaper sedáis and books
After The Foundation of Republic
Dudng the pedod of the Republic, relations with the West increased in every area such as trade, culture, education and defense. New discoveries arose by the fast advent of science and technology imported with their Western names. Foreign language teaching spread, the number of primary, middle and higher institutions giving education in foreign languages increased. In scientific terminology, relative weight of Western languages increased, even the adoption of Greek and Latin as source languages instead of Arabic and Persian was defended. During the language reform, some words of Western origin replaced several Arabic and Persian words discarded, during the activity of collection from local dialects several foreign (mainly Greek and Armenian) words were introduced into the language involuntarily. Meanwhile the frequency of travels out of country for education and tourism and the ratio of Turkish citizens residing in foreign counties increased also. The number of foreigner coming to our country increased consistently as well as the number of international and multi-national companies. The majority of loanwords in this period are of French origin. However after 1950's the entrance of English words accelerated due to American influence. After 1980's American influence became more apparent, radio and television broadcasts in English increased, foreign names given to trade offices became popular
It is a difficult task to investigate the increase of the relative frequency of western origin words in Turkish within time and present objective data on this subject. Language exhibits variations depending on different classes and environment. The foreign words circulating among lawyers are different than those of doctors or merchants. Therefore changes in social structure, industrialization, urbanization, migrations, differentiations in education system, magnified the differences in the society with respect to language.
Evaluation of Density of Foreign Words
One way to assess the number of words entering our language in different time periods is to scan dictionaries prepared in those periods. By inspecting only the letter "A", Ünver (1991) stated that there were 120 Western origin words in imla Lügati prepared by Dil Encümeni in 1928 whereas Türkce Sözlük some 30 years later had 320 and 515 foreign words in the 1958 and 1988 reprints respectively. But evaluations relying on dictionaries have some drawbacks. First of all etymologies stated by these dictionaries designed for foreign words depend on the knowledge and opinions of authors on the subject. Secondly, since all dictionaries are not equally detailed, while some of them cover rare words others have a very restricted scope. Thirdly, since the usage frequencies of words are not equal, there is a substantial discrepancy between proportions calculated from dictionaries and those calculated from samples representing written or oral language
Western loan-words in Turkish are shown in some dictionaries. As etymologies of several words are not well known there are contradictions in these dictionaries. Lehcet-ül
Lügat of Mehmet Esat Efendi printed in 1811, considers several Greek words as Turkish. The Turkish-English Dictionary by Sir James Redhouse gives more reliable information on this
subject. This is followed by Lehce-i Osmanî of Ahmet Vefik Pa§a and Lugat-i Ecnebiye ilaveli
Lugat-i Osmaniye of Dr. Hüseyin Remzi published in 1880 which contained around 500
foreign words. Çemseddin Sami, the author of Kamus-i Türkí also reported origin of several words. The dictionary of Ahmet Hamdi named Lugat-i Ecnebiye and published in Trabzon in 1907 assembled about 750 foregin words. Kerestedjian (1912) in etymology dictionary published in London identified out about 350 foreign words. In AH Seydi's work Lisan-i
Osmanide Mustamel Lugat-i Ecnebiye, printed in Matbaa-i Re§adiye, about 1300 foreign
words are presented. In addition to the former, the dictionary edited by M. Baha in 1923 shows words of Western origin that entered the written language after 1910.
In all branches of science the way to reach correct results depends upon obtaining reliable data. Since it takes an extremely long time and is very costly, collecting the complete set of relevant data on the subject interested in is often not feasible. Nowadays by using powerful and reliable statistical methods and by conducting suitable sampling studies with a small proportion, research workers are able to reach correct decisions. In order to get successful results from sampling the frame of the subject must be drawn correctly. The main-body expressed by the word "language" and consisted of words exhibits an extremely complex structure. Demographic factors such as education, settlement, gender, age and profession bring about differences in language characteristics in different sections of society. On the other hand the subject renders functional words from certain semantic fields. There is a great difference between sports pages and economy pages or between news and columnist writings of a newspaper. There is also language difference between various literary types. There is a great difference in the languages of various literary types such as poetry, story, novel, play, essay or article when they treat the same subject. The same difference is valid for written and oral languages. The texts of science, art, entertainment and various communication areas cannot have the same language. Because of these reasons the meaning of "language" must be clearly stated in order to avoid ambiguity in the concept of "Foreign words in language". The best approach in this context is to obtain an intersection common to languages of all social sections of the society. But this is the definition of living language. It may be said that the
novels and stories reflect very effectively the living language. For this reason in our work samples are taken from novels.
Although in a modest scale, some authors interested with purification of our language have resorted to sampling. But it can not be said that these are sufficient qualitatively and quantitatively. These researches, contented with some enumerations and percentages, did not use any hypothesis testing or mathematical model. In a forum, by compairing two issues of Ak§am newspaper published in 1925 and 1962 respectively, Konur Ertop tries to explain the purification of our language (TDK, 1962). By studying samples of size 3000 words each from works of various authors, Aksoy (1973) also argues that the foreign words are decreasing in our written language, since while the proportion of Turkish words was 33 % in §inasi, 34 % in Ziya Pa§a, 38 % in Namik Kemal, 35 % in Atatûrk's Nutuk it rose steadily by time to reach 59 % in Faruk Kadri Timurta§, 62 % in Ahmet Hamdi Tanpinar, Falih Rifki Atay and Peyami Safa, 66 % in Yakup Kadd, 67 % in Sait Faik, 73 % in H. Veldet Velidedeoglu, 80 % in Ya§ar Nabi, 81 % in Salah Birsel and Asim Bezirci, 84 % in Tahsin Saraç, Ya§ar Kemal and Samim Kocagöz, 91 % in Adnan Binyazar and Emin Özdemir. But the reader must be reminded that since the samples of moderate size evaluated in this study are drawn from different fields and literary types they are not comparable. By conducting a large and systematic quantitative research and giving percentages on issues of five newspapers printed in 1930-1965, five magazines, eleven novels and stories, imer (1973) presents tables showing the decrease in Arabic and Persian word and increase in Turkish words. In this work too the situation of western words escapes from view. Because everything out of Arabic, Persian and Turkish are classified under the name of "Other foreign languages".
Etymology
In order to reach valid results in our research it was necessary to firstly identify the etymologies correctly. Therefore significant time and attention was devoted to this stage. Dudng the passage of time the information was revised continuously by using new etymology resources. The references used are as follows
1. Bûyûk Turk Lugati, Hûseyin Kâzim Kadrî
2. Tûrkçe Yabanci Kelimeler Sôzlûgû, Mustafa Nihat Ozon 3. Tûrkçe Sôzlûk, Atatûrk Kûltûr, Dil ve Tadh Yûksek Kummu 4. Kamus-i Tûrkî, §emseddin Sami
5. Meydan Larus, 14 volumes,
6. Okyanus, Ansiklopedik Sôzlûk, Pars Tuglaci, 6 volumes, 7. Redhouse, Yeni Tûrkçe-ingilizce Sôzlûk, Sir James Redhouse 8. Turk Dilinin Etimolojik Sôzlûgû, Hasan Eren
But the sources giving information on foreign words are not restricted to these. There are different lists in Korkmaz (1995), Dankoff (1991), Dankoff (1995), Muallimoglu (1999) and many more researchers.
Some Difficulties
It must be stressed that the etymology is one of the most difficult aspects of this study.
First of all, there is not complete consensus between sources. There has been a continuous interaction between languages throughout history. Although various sources agree on the words borrowed recently, they disagree on those that entered a long time ago. Moreover, several words in English, French or German are taken from the colonial languages and originated from aboriginal populations of America, Australia and Africa or Eskimos: alpaka, ananas, anorak, domates, hamak, kanguru, kakao, kauçuk, koka, lama, mokasen, maun, patates, puma, samba, sigara, gempanze, totem are some examples. These are counted as from the mediator languages. Some words are taken from Latin or Greek through Arabic. On the contrary there are Arabic, Persian, Indian, Japanese even Turkish words passed to westem languages and after taking a different form returned to our language. Especially several words belonging to Persian, an Indo-European language, can be confused with their Westem similar. Some examples are the following words starting with letters A and B: abanoz, afyon, alay, Avrupa, balet, bergamut, bilet, billur, bora, borda, bukalemun. There is not a complete agreement on the etymology of these words. In preface of his dictionary, M. N. Özön states that his work has not any scientific claim and aims to be a reference book for interested readers and a source of material for researchers. In treating the historical developments, he considers 'kaldinm' as a foreign word. While Özön states that 'kabak' is derived from the Italian word 'capoccia'. Eren (1999) by comparing with other Turkish dialects identifies it as a Turkish word. In Özön about thirty words such as canta, çirig, çomar, davlumbaz, hirizma, kabara are considered as foreign of unknown origin. Muallimoglu (1999) who presents foreign word lists, considers 'felsefe' and 'musiki' as Arabic and 'figki' as Turkish. On the other hand, 'kambur' takes place both in Arabic and Turkish words. 'Demet', 'omuz' and 'bom' are counted as Greek in the text but were not included in the list. 'Tedavi' was claimed as a Greek word and alçi, biber, çelebi, çerçi, testi and ugur as Latin. 'Peçe' is included both in Greek and Italian lists. According to Okyanus 'sira' is from Greek. Some of our wdters considered 'ömek' as Armenian after Kerestedjian (1912). These demonstrate that etymology is a very difficult branch. Eren allotted a large space to this subject in foreword of his etymology dictionary and pointed out several mistakes in the works of Bedros Kerestedjian, ismet Zeki Eyuboglu and Martti Rasanen. Under the light of the information obtained from different sources, a sampling technique is applied in compliance with the pdnciples presented below. Later, the foreign words found are arranged as a list, their origins are written at their front and by constructing a file with two columns necessary counting and calculations are carried out by using a computer.
There were no electronic scanners when this study started during the 197O's. Technical developments since then have made sampling and counting operations easier. But the usage of scanners can not be justified due to several reasons. First of all for correct reading, pages should not contain ink spots or other traces and pdnting errors. The scanning of books pdnted before the adoption of Latin alphabet creates a great problem by itself. For this task programs capable of solving Arabic letter texts are required. Moreover, the research worker must read the samples to be inspected thoroughly and must understand contextual meanings of words cleady. Otherwise etymological evaluations based on the lists obtained by scanning a text using
spelling but different meanings. Most of these are names as root words, but there are also verbs, adjectives and other types such as: alay, ar§, as, atak, aya, bar, bas, bazen, bek, bere, bluz, bol, bot, boy, ein, çek, dalya, dam, din, diyet, don, duy, fars, felek, firengi, fit, fon, fors, funda, gam, getir, gine, gönder, gurup, hal, halat, harp, havlu, her, humus, hoyrat, inbat, kalite, kanun, kap, kaput, karga, karine, kart, kast, katir, kaval, kazak, kent, kerte, kirat, koç, kok, koli, kot, koz, kundak, kur, kurs, ku§, küp, lak, lavta, leh, levend, manda, mani, manti, masif, mat, mayis, meç, metro, meze, mi, mil, mis, misket, ortanca, palan, palas, pas, pat, pens, pirinç, pi§ti, plak, prova, pul, punt, pus, pusula, put, safra, saka, sal, salta, sandal, sari, sen, ser, seri, set, sol, somun, sor, spor, step, §an, §ap, §ik, tabaka, tac, tambur, tavla, teskere, tez, toka, tuba, Ure, yat, yeke. There are also examples gained similarity by suffixes or abridgements: aksa, aksan, alman, astim, banka, barka, batman, benzin, bora, boru, boyar, capa, dama, dará, delir, desen, dikiz, dolar, dona, ekip, ekler, eksen, file, filim, fonda, fondan, forma, forsa, gama, kalasi, kana, kanca, kaptan, karta, kasa, ka§a, katana, koka, kola, korsan, korta, kupa, kura, kurda, kurun, kursa, kursun, kuru, küfe, küre, maca, malta, marka, marti, nota, parka, parsa, pasa, pata, pisin, pota, pulluk, rampa, reye, seren, rota, sele, sivilce, sonda, taksa, taksim, tarasa, terim, tipi, toka, tugla, tura, volta, tel (iplik) - tel(graf) are some examples. Examples of both classes may be increased. In studies depending on automatic evaluation of texts this situation must be taken into account.
Another factor creating difficulty in the usage of scanners is the ongoing chaos in the spelling of foreign words. Several words are written in a different way by different authors or in various times. For example the word 'pantolon' was in the form 'pantalon' earlier. Still there are hundreds of words with different spellings. In these, letters with similar sounds replace each other or they are adapted to their pronunciations in foreign languages such as: Ciklet çiklet, §imendifer §ömendifer §ümendüfer, istimbotistinbot, izgara lzgara -lskara, anciiez - ançuyez - an§uva, candarma - jandarma, cip - jip, sigara -sigara, egsos - egsoz - egzos - egzoz - eksoz - ekzos - ekzoz, diretnot - drednot - dretnot - dritnavt. Sometimes letters are swapped like: §artel - §alter. There are words preserving their foreign spelling such as: jip - jeep, §evrole - Chevrolet, Cemse - GMC, Doc - Dodge, fit - feet, grizet - grisette, restorán - restaurant - restorant, naylon - nylon. These writings sometimes go beyond a spelling problem and change the source language from which the word is taken. Such as: Santimetre - santimetro, kopya - kopye, dantel - dantela, gitar - kitara, minor - minor, pandomim - pandomima, peruk - peruka. Some authors write the foreign words as in popular language, like cigara - cigara - cuvara, caket - çeket, pevlika.
Compound words too create a difficulty in counting. Differences are observed in concatenated words depending on writers and periods. These are counted as a single-word during enumeration such as: Birkaç, herhalde, delikanli, suikastçi, berhayat, gökyüzü, robdö§ambr, §ezlong, kartpostal... On the other hand compound word may be hybrids of two languages, one belonging to a Western language: hanimefendi, ba§gardiyan, ba§komiser, ba§kumandan, beyefendi, borazan, gazocagi, gazyagi, havagazi, karaborsa, konsoloshane, marangozhane, musiki§inas, ortahaf, pastane, postane, sporsever and telgrafhane are some examples. These are attributed to the Western language from which they contain a word. Since borsa is Italian, karaborsa is also considered so. Another set of words creating difficulty consists of abbreviations. These are counted from the language of the words abbreviated. But
main problem is that some letters may not represent foreign words, as in AP, CHP, DÍSK, RTÜK, TRT. In the first two abbreviations Parti is French. Hence these abbreviations are counted as French since they contain a letter from this language.
Evaluation of proper names deserves a special attention too. In this work not proper names indicting a person, city, river, mountain but those indicating a continent, sea, country, nation, race or language are considered foreign. For example, not the words George, Pads, Ren, Etna... but, Avustralya, Atlas Okyanusu, Îngiltere, Fransiz, German, ispanyolca.., are considered as foreign.
In spite of all these evaluations there remained around 500 words difficult to determine the origin. Some of these are patented words or abbreviations derived from Greek and Latin roots and are mostly used in pharmacy and chemistry such as: eternit, vinileks, losonil, mogadon, neskafe, alujel, kardilat, nuvokain, nidilat, pentatol, mergal, diyazem, lyosol, mi toi, DDT, DNA, DDVP. Several words are being used as trade marks although they are person, place, institution, or object names: Nacar, Hanomak, Ford, Nagant, Ronson, MAN, Montofon, Movado, Serkldoryan, Zenit, Kodak and Brovning are some of these. There are even such trade marks settled in our language that replaced the genuine names of the objects such as jilet (Gilette), cemse (GMC), reo, kale§nikof, cip (Jeep). The solution for trade marks is to consider them from the language of their names. Against all these classifications some words still remain in darkness. Such as: Mansila, komparsita, agaragora, lolotya, digustrin, oçiçorniya, külvedne, §akulta, kantalup. Their number is around 200 and they are coded under the name 'foreign words of unknown origin'. As they are very few in number, they do not significantly influence global results of our research.
At last, it must be stressed that there is still a long way to go in etymology studies. The emergence dates of words must be determined by depending on old texts. In this respect as a researcher using the etymology only as it is determined by experts, I would like to express my doubts on several words. For example the words parlak and parlamak are given as onomatopés. But other dialects and tongs of our language must be evaluated carefully in this respect. Because the resemblance with words pirlanta or brillant causes some doubts. The same argument is valid for mini mini minnacik and minik. What is their relation with the words minima, minimum, minimal? What is the familiarity of words bebe and bebek with pupa and pup? The similarity between reis and roi draws attention. Similarity of the word "pars" which is claimed in sources as Persian, and the Latin word "felis pardus" invokes doubts. These examples may be increased.
Sampling
It is necessary to take samples from various texts in order to determine the density of Western loan-words. But since different sources will make the comparison difficult, the samples must belong to the same literary type. On the other hand the closest of wdtten works to living language are novel and story. Being the language used and understood by the majodty of the nation in their daily life, living language may be considered as the intersection of vocabularies of different sections and groups. Novel and story target large reader populations. For the popularity of the writer and profit of the publisher this is unavoidable. Although there are examples addressing narrow sections, these extremes are exceptions compared to other literary types. As it contains larger texts, the novel was considered a more
appropriate material than the story for sampling purposes and, in our present study a period exceeding one century was investigated starting from the 1870's when the first novels emerged in our language. The oldest novel included within this sampling was the work Taa§§uk-i Talat ve Fitnat of §emsettin Sami. The most recent ones are dated 1999. In order to demonstrate the transformation process in the language and to explain the future results of alienation accelerated with Tanzimat, our sampling covered a large slice of time. For exhibiting contributions of different authors, 561 novels from 82 writers are studied by executing counts on samples of 500 words each taken from randomly chosen pages so to account for one-tenth of the text. In order to be able to assess the variations in the language of each writer, a special care is spent for selecting the samples from works written in different years.
This study was started in 1972 and sampling efforts are continued until the end of the year 1999. In the statistical sense of the word, the texts from which the samples are drawn, constitute a multi-strata population. The main strata are the writers. The sub strata are the novels of particular writers. The choice of writers and novels was not accomplished according to completely random design, since care is given to choose novels of 82 writers printed in different years. The first print of each novel is studied. When the first print was not available, later prints were investigated provided they were stated to be identical to the first printing, and the results were checked with the first prints found later. Nearly all of the books printed in Arabic letters were found in Seyfettin Ozege Library of Atatürk University, and the rare books printed in Latin alphabet were found in the National Library and Adnan Ötüken Library in Ankara. The choice of text samples from a novel is accomplished according to systematic sampling. The result was a multiple-stratified systematic sampling (Cochran, 1963). The application of systematic sampling from a novel requires that no periodical style fluctuation should exist parallel to sampling intervals. There seems no reasonable cause for violation of this assumption.
Sampling density is 1/10. Therefore from a novel of 400 pages, for example, 40 pages are read on the average. When the text was read, all words of Western origin are written down and arranged in alphabetical order for each sample. The first sample was drawn from the beginning pages of the novel. After examination of a text containing 500 words, its length was measured and multiplied by 10 in order to decide on the number of pages to skip and page to start the second sample. For example the text of novel Karnaval of Ahmet Mithat Efendi published at Tercüman-i Hakikat printing house in 1298 Hegira was sampled starting from page 15. As the first 500 words covered 1.6 pages, the second sample started from the page 31 (=15-1-10x1.6). The second sample was 1.7 pages long therefore the third text was started from page 48. By this way, from this work of length 255 pages 15 samples are taken starting at the beginning of pages 15, 31, 48, 64, 80, 97, 114, 130, 147, 164, 181, 201, 217, 235, and 253. These texts reach a total volume of 25.6 pages which is approximately 1/10 of novel. In fact, the conventional method in systematic sampling is to enumerate the sampling units first, then make selection among them with definite intervals. But since this procedure would require reading the whole novel and counting the words before sampling, the benefit and ease expected from the sampling would not be realized. Since the number of words may change in every page, depending on the number of paragraphs and lengths of sentences, the procedure applied here destroys the dependence of all texts on the first sampled piece and secures the randomness to a greater extent, in particular for large novels.
In this way, a very rich sample of material scattered to vadous points within a time slice exceeding one century was obtained. In order to give an idea on the volume of the study, it may be said that there are a total of 3,150,000 words in 6300 samples taken, and this corresponds to approximately 16,000 book pages when calculated 200 words per page on the average. Such an immense material deserves to be considered from several different angles, and evaluation of the files built in the computer will continue in future.
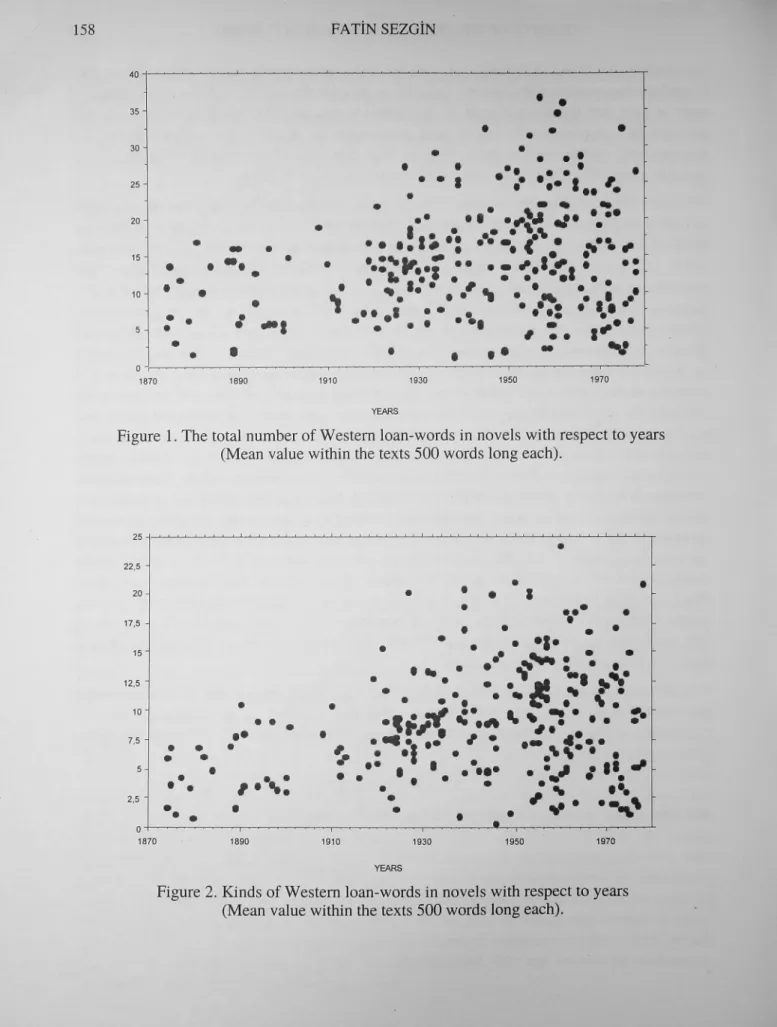
Data obtained from 280 of these 561 novels are evaluated earlier and presented as a paper in Fourth International Turcology Congress (Sezgin, 1982), and later took place in the book titled Dil ve Edebiyatta Bilgisayar ve istatistik Uygulamalari published in 1993 (Sezgin, 1993). Still another evaluation dealing with the results of the 280 novels written before 1980 was interpreted from a different point of view, was published in the Osmanh Ansiklopedisi (Sezgin, 1999). Here the increase of Western loan-words is assessed with respect to time. Graphs prepared for this purpose are presented in Figure 1 and Figure 2. Figure 1 shows total Western origin words seen in samples of size 500 words from the novels. But the same word (or words derived from the same root) may be repeated several times in a text. Therefore it is informative to look at word varieties too. The increase of word varieties may be seen in the graph of Figure 2. In our statistical analysis the regression coefficients of total words and word types against time were 0.068 and 0.045 respectively. These values correspond to yearly increase rate of foreign words. It means that before 1980 the total number of Western origin words in text samples of size 500 words increased on the average 0.068. This, in turn, corresponds to a yearly increase 0.136 per thousand. In compadson to the life of languages, this indicates a serious invasion. Another fact revealed by graphs, is the stylistic controversy observed in the language since Tanzimat. The points are almost situated in a fan constantly enlarging rightward. While Before 1880 there were 6-7 kinds of different western origin words in a text of size 500 words using Western words excessively, this number rose to 10 in 191O's, to 25 in 192O's and 25 in 195O's. As a matter of fact the distance taken by western words is hidden from sight to some extent by populadzed trends of historical and rural novels after the Republic, and in particular after 195O's. For this reason extreme values in graphs for each year bear a more significant value.
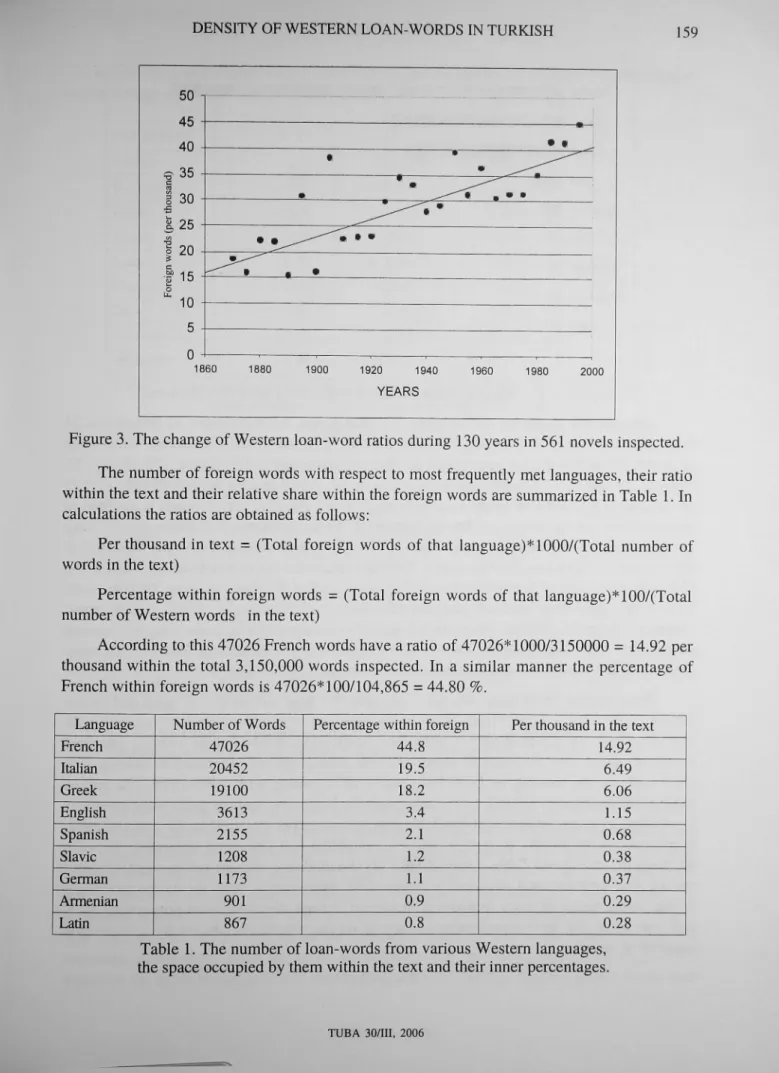
When all counts are evaluated globally, around 105.000 foreign words of Western origin are found. When these words are classified in five year intervals and the scatter of averages against time is drawn, the situation of figure 3 arises. The equation of the line representing the points on the figure is
Y = -309.3-^0.175X
3 5 3 0 2 0 -• "t / - , 1970
Figure 1. The total number of Westem loan-words in novels with respect to years (Mean value within the texts 500 words long each).
1870 1890 1950 1970
YEARS
Figure 2. Kinds of Westem loan-words in novels with respect to years (Mean value within the texts 500 words long each).
Figure 3. The change of Western loan-word ratios during 130 years in 561 novels inspected. The number of foreign words with respect to most frequently met languages, their ratio within the text and their relative share within the foreign words are summarized in Table 1. In calculations the ratios are obtained as follows:
Per thousand in text - (Total foreign words of that language)* 1000/(Total number of words in the text)
Percentage within foreign words = (Total foreign words of that language)* 100/(Total number of Western words in the text)
According to this 47026 French words have a ratio of 47026*1000/3150000 = 14.92 per thousand within the total 3,150,000 words inspected. In a similar manner the percentage of French within foreign words is 47026*100/104,865 = 44.80 %.
Language Erench Italian Greek English Spanish Slavic German Armenian Latin Number of Words 47026 20452 19100 3613 2155 1208 1173 901 867
Percentage within foreign 44.8 19.5 18.2 3.4 2.1 1.2 1.1 0.9 0.8
Per thousand in the text 14.92 6.49 6.06 1.15 0.68 0.38 0.37 0.29 0.28 Table 1. The number of loan-words from various Western languages, the space occupied by them within the text and their inner percentages.
Figure 4. The share of Western loan-words within texts (Per thousand).
Although not displayed on the table, 229 Hungarian, 84 Rumanian, 35 Bulgarian, 24 Portuguese, 24 Polish, 10 Swedish, 2 Danish, 2 Czech, 2 Albanian and 1 Icelandic words were encountered. Although not considered as Western languages, 329 Syriac, 59 Malay, 51 Hebrew, 27 Gypsy, 13 Sanskrit words were also found, which make a very small ratio of 0,15 per thousand as compared to the total volume of texts. Another set of words is situated as pieces of texts written directly in foreign languages. These quotations in the form poems, song words, idioms or conversation pieces total 1600 words which represent 0.51 per thousand of the text and i.5 % of total foreign words. There is still another set of words not included in the table that are in fact of Western odgin but are presented as if related to some Turkish roots. From time to time there has been great discussions on these (Banguoglu, 1981). Among them, evrensel (universal), komut (commande), komutan (commandant), imge (image), egemen (hegemon), okula -later became okul - (schola or école) may be mentioned. These words occur 4661 times and represent a proportion of 1.48 per thousand in the text.
These general ratios are an overall evaluation of a time section of 130 years and do not remain fixed at all periods. Hence it has been necessary to conduct a detailed analysis with respect to time. For this purpose 561 novels are classified according to their printing years and the situations of each language in these intervals. Groupings are organized to contain five years each and by starting as 1870-1874, 1875-1879 ending with 1995-1999. The results reached are gathered in Table 2. In this table only the beginning years of periods are indicated. In addition, by using the counts of this table proportions as per thousand in the text and ratios as percentages within the foreign words are calculated and presented separately for each language in Table 3 and Table 4 respectively. By the guidance of these tables word densities against time are drawn and presented in flgures 5-15. Moreover in order to see the increasing or decreasing trends of word densities with respect to time, denoting word proportions by Y and time by X, the lines representing the points on the graphs are shown by a regression equation of the form
Y = a -H bx.
Here, the a and b coefficients obtained for per thousands in the text and percentages within foreign words are summarized in Table 5 and Table 6 respectively.
Languages French English Italian Greek Latin German Slav Spanish Armenian a -214 -21.9 -28.8 3.1 -4.34 -4.93 -5.90 -10.83 -1.98
ß
0.1170*** 0.0118*** 0.0181 0.0016 0.0024*** 0.0027*** 0.0032*** 0.0059*** 0.0012 a 0.000 0.000 0.074 0.803 0.000 0.000 0.002 0.000 0.273 R 2 0.651 0.689 0.090 0.000 0.478 0.417 0.313 0.411 0.023 Table 5. Regression analysis results on the change of the Western origin foreignword volumes within the text with respect to years.
Languages French English Italian Greek Latin German Slav Spanish Armenian a -308.3 -44.7 143.7 277.7 -5.9 -2.4 -9.1 -21.4 3.80
ß
0.182*** 0.025*** - 0.063* -0.132*** 0.004 * 0.002 0.005 0.012 * 0.002 a 0.001 0.000 0.033 0.000 0.047 0.535 0.186 0.015 0.642 R 2 0.358 0.393 0.142 0.459 0.119 0.000 0.033 0.192 •' 0.000Table 6. The results of regression analysis of variation of the share of different foreign languages within the total foreign words of Western origin with respect to years.
The coefficients deserving special attention among those given in the tables are ß values.
These correspond to the slopes of straight-line equations and represent the increase during unit time (year). Minus sign in these numbers means a negative increase that implies a decrease.
But it is seen that sometimes these coefficients take values very close to zero. Therefore it is
not sufficient to consider only the values of b's taken in this research. Since a sampling procedure is applied here, these must be considered as estimates of underiying true ß values that represent all novels written in our language. Because the 82 novelists investigated represent all novelists given works in our language and the novels taken from each writer represent the novel language of that writer. Naturally text samples that are of 500 words each
and constitute one-tenth of the volume of a novel are representing that particular novel. In statistical works of this kind depending on sampling, the b values may not be equal exactly to ß. The same situation is also valid for "a" values. It means that a different investigator conducting the same research would find different a and b values. And this means that, perhaps, although there is no real change in proportions, it is possible to find a value larger or smaller than zero by chance. In this case although ß=0 it may be concluded by mistake that ß>0 or ß<0 and this is an error. In Statistics this is called Type I error and denoted by a. For reliability of results it is desired that a does not exceed 5 %. In Table 5 and Table 6 Type I error values are given in column a. Another column taking place in tables is R^ that is called coefficient of determination. This value measures to what extent the model applied explains the variation in the data, and, as it approaches one this is an indication that it explains almost the whole variation and the points in the scatter graph are situated almost on the line drawn. By contrast values near zero mean a weak association. Inspection of tables and the graphs drawn depending on them reveals the existence of some outlier points in early periods. Obviously since novels written in these periods are scarce, an over aboundance in one or two of them will influence the general average of these periods. Since in early periods foreigner heroes were present in novels quite frequently, and Beyoglu or its environment where levantens lived, or European cities, were being adopted as scene, excessiveness of this kind was unavoidable. In Tanzimat novels, due to the structure of the society of that pedod, heroines were chosen mostly among non-Mushm concubines, foreign women, or non-Muslim Ottoman subjects (Gôkçek, 2000)
Examples of this are the novels Demir Bey and Hasan Mellah published in 1888 and 1874 respectively. They caused some deviations in global means of these periods. In analyses executed by omitting these outliers, the rate of increase in the proportion of foreign words is found slightly higher.
When the total space occupied within the text is taken into account, no significant increase was recorded in Italian, Greek and Armenian. This situation may be explained from two points of view: The loan-words from these languages belong to older pedods and there had been no entrance of new words since Tanzimat. At the same time there had been no increase in the usage of words already taken. Because if the usage of existing objects increase, the density of words will increase too in spite of no introduction of new words. There was however such a significant increase in the densities of French, English, Latin, German, Slavic and Spanish words that can not be attributed to chance.
When the shares of different languages within the Western origin words are examined, it will be seen that shares of French and English are increased very significantly and shares of Latin and Spanish are increased significantly. But the share of Italian fell significantly and the shares of German, Slavic and Armenian did not have any significant change. When these languages are inspected in order, the following can be said about flgures 5-13:
The ratio of French words within the
whole text (per thousiuid) nd ) Frenc h (Pe r t 26 20 1 5 • 10 5 • 0 1 1860 • • 1880 i t • • 1900 1920 1940 YEARS t • ' 1960 1960
.-
1
2000The ratio of French within the Western words (percent) Frenc h (% ) 70 60 50 40 30 20 10 0 1860 m • 1 • * 1880 " a > 1900 1920 1940 YEARS w m 1960 1980 — -m 2000
Figure 5. The place occupied by French words within the total text and within the Westem origin words only (As per thousand and percent respectively).
FRENCH: Figure 5 shows the developments in French words. But a point in the period 1885-1889 exhibiting an excessive deviation from the overall trend must be pointed out here. Such a deviation was caused by the fact that sixteen of forty seven samples of size 500 words each representing this period belong to Ahmet Mithat's novel Demir Bey in which several heroes are French and events pass in foreign countries. An analysis accomplished by excluding this extreme value, the density increase of French words reaches a slightly larger value than found here. The ratio of French words within the text, reached from three per thousand in early novels to 25 per thousand in 1999. This steady rise was due not only to introducing new words directly from this language but also to adapting the pronunciation of words taken from other Western languages to French accent. The slope of line expressing the increase rate is 0,117 and this corresponds to a rise of one per ten thousand per year. Word imports from this language continued up to present day without slowing down. Korkmaz (1995) states that during the period following World War Two and extending until present day, the density switched from French to English. This impression depends mainly to oral language of some social groups, working-place names and some television programs, but this increase has not yet started to be felt fully in written language. The share of French among all foreign languages also rose steadily. This increase is around two per ten thousand a year. This share rose from 20 % of early periods to 60 % at present.
The ratio ofEnglidi words within the
whole text
(per tiiousand) Englis
h {" / 1860 • • • il • • • 1880 1900 1920 1940 1960 1980 Y E A R S 2000
The ratio of English within die Western words
(percent)
Figure 6. The place occupied by English words within the total text and within the Western origin words only (As per thousand and percent respectively).
ENGLISH: Although the ratio of English words in early period texts was about five per ten thousand, it reached up to two per thousand at present. The slope of the line at the lower graph of Figure 6 expressing this is 0.0118, and that corresponds to an increase of one per hundred thousand per year. The ratio within foreign words, starting from approximately one per thousand reached five per thousand. One extreme point that takes source from some Enghsh words of the novel Hasan Mellah of Ahmet Mithat Efendi inl870-1874 period draws attention here. The graph reveals that English words exhibit a very steady and systematic increase.
The share of Italian words within the
whole text (per thousand)
1
1
•m 12 10 8 1860 ft * 1880 1900 1920 Y E V - - . . • - • - • - • 1940 1960 1980 2000 A R SThe ratio of Italian within the Western words (percent) 35 T 30 è^ 25 c ^ 20 ™ 15 10 5 • • * • 1860 1880 1900 1920 1940 Y E A R S • * * • » • 1960 1980 2000
Figure 7. The place occupied by Italian words within the total text and within the Western origin words only (As per thousand and percent respectively).
ITALIAN: The trend of increase within the total text has the value 0.01 (per thousand) which is not found significant statistically. Therefore it may be said that some words were taken formerly from Italian but there has been no significant increase in their usage. Even, first by expansion of French and later of English, some Italian words are discarded from our language. Taraça was replaced by teras, urba by rop, and lokanta by restorán. Samples may be increased such as: banka - bank, salça - sos, §iringa - enjektör, metro - metre... This ratio of six per thousand of early periods remains around the same value at present. But the inspection of the second graph reveals that, Italian has not been able to continue its development against the expansion of other foreign languages, therefore the share of Italian in total Western words was decreasing significantly. The share of Italian fell from about 40 % of early years until 15 % at present.
The share of Greek wordswithin the
whole text
(per thousand) Gree
k (pe r tousand ) 10 a 8 7- 6- 54 -3 2-1 . 0 J, 1860 • • 1880 » -1900 • m 1920 Y E / 1940 • * • 1960 1980 j 1 1 ! 2000
The ratio of Greek within the Western words
(percent)
Figure 8. The place occupied by Greek words within the total text and within the Western odgin words only (As per thousand and percent respectively).
GREEK: The situation is similar to that of Italian. The Greek words had a ratio of six per thousand within the text and could not increase it significantly. For this reason its share within the western words diminished steadily and fell from about ^0 % to 15 %. Yeady decreasing rate was about one per ten thousand and found significant in statistical test. As in Italian some Greek words also were discarded by the entrance of French and English equivalents such as: avlu - hoi, panayir - fuar. The word panayir in the last example began to be used for agdcultural expositions of small scale by a restriction of meaning.
The ratio of Latin words within the
whole text (per thousand)
The ratio of Latin within the Western words
( pereent)
Figure 9. The place occupied by Latin words within the total text and within the Western origin words only (As per thousand and percent respectively).
LATIN: Latin, although an extinct language, by pieserving its significance as an important source for terms in Western languages, increased its proportion in texts approximately from one to almost five per ten thousand. A significant increase was observed in its share in Western words too. The existence of defendants of basing our scientific language to Latin caused a substantial enhancement in the share of this language. This ratio found in novels would be found significantly higher if the works from different scientific fields were examined.
The ratio of German words within the
whole text (per thousand) 0,8 0,7 0,6 0,6 0,4 0,3 0,2 0,1 0 • * • * • 1860 1880 1900 1920 1940 1960 1980 2000
The ratio of German within the Western words
(percent)
Figure 10. The place occupied by German words within the total text and within the Western origin words only (As per thousand and percent respectively).
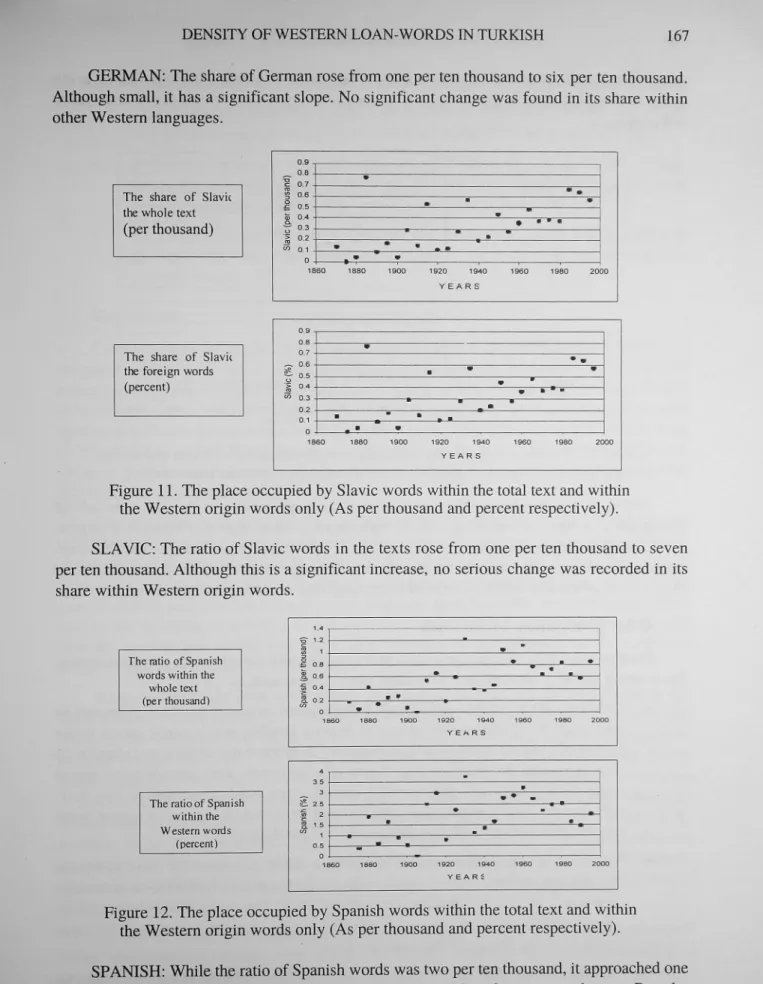
GERMAN: The share of German rose from one per ten thousand to six per ten thousand. Although small, it has a significant slope. No significant change was found in its share within other Western languages.
The share of Slavic the whole text
(per thousand)
The share of Slavic the foreign words (percent) ^ 0.6 -Sl a • « fc • -m 1860 1880 1900 1920 1940 1960 1980 2000 Y E A R S
Figure 11. The place occupied by Slavic words within the total text and within the Western odgin words only (As per thousand and percent respectively).
SLAVIC: The ratio of Slavic words in the texts rose from one per ten thousand to seven per ten thousand. Although this is a significant increase, no sedous change was recorded in its share within Western odgin words.
The ratio of Spanish words within the
whole text (per thousand) (pue « h (pe r Iho u
1
1.2 0.8 0.6 0.2 ie160 * • * • 1880 1900 1920 1940 1960 Y E A R S 1980 2000The ratio of Spanish within the Western words
(percent)
Figure 12. The place occupied by Spanish words within the total text and within the Western origin words only (As per thousand and percent respectively).
SPANISH: While the ratio of Spanish words was two per ten thousand, it approached one per thousand in recent years. It increased its share within foreign words too. But the
observations obtained for this language exhibit a very large variation, and this situation is due to the fact that semantic fields of Spanish words cover only narrow areas such as navigation and commerce.
The ratio of Armenian words within the
whole text (per thousand)
The ratio of Armenian within the Western words
(percent)
Figure 13. The place occupied by Armenian words within the total text and within the Western origin words only (As per thousand and percent respectively).
ARMENIAN: Armenian words entered our language mostly in the early periods of immigration to Anaolia and are related to agriculture, construction and household objects. There have been no new additions on these. Many Armenian words are living in local dialects. Some of them are introduced to Turkish during language reform via word collections. Its share in total words and within those of Westem odgin did not change substantially.
Other Evaluations to Be Done
Foreign word files of extremely large size obtained and recorded into computer during this research will be evaluated later from many more aspects such as:
Stylistic characteristics and attitude differences of wdters in word selection may be handled. While some writers do not go beyond familiar words, some others prefer more odd and eccentric ones. It is necessary to appraise this attitude and classify the foreign words according to their degree of assimilation. For example many people may think that Peyami Safa is using more foreign words compared to Sait Faik. The reason for this impression is the fact that Peyami Safa uses more special terms from fields such as medicine, philosophy and psychology.
• By assessing the differences between works in detail the reason for these vadations must be determined. For example the novels taking place in different environments use words of different density and kind. By classifying novels into subsets such as rural, urban, historical, detective, psychological... etc, the words used by these genres may be classified into semantic areas.
• Words can be classified into semantic classes and the vadation of each class may be evaluated with respect to time.
• Usage statistics of word types, such as name adjective and verb, may be derived. • Appearance and extinction times of words may be determined. In this way it will
be possible to see that once popular words are replaced by some others by time. • In enumeration obtained by computer, a total of about six thousand different
loan-words are recorded. Some of these are derived from a common root and some others are compound words. This aspect requires an evaluation.
• As a subject more relevant to linguists and foreign dictionary editors, sentence examples may be chosen containing foreign words in order to demonstrate different usages.
Conclusion
Closed systems having no external effects are not met even in the inanimate world. And the nation, which has a very dynamic structure, interacts in every field with other nations and cultures surrounding it. The Turkish language too had serious transformations depending to civilization circles to which it belonged and came into contact. Due to Its geographical position the Ottoman Empire had been in continuous contact with all main civilizations of its time from its foundation to its fall. While European languages were fed from Latin and Greek sources, Ottoman Turkish was fed from Arabic and Persian, and inclined to take not only words but also suffixes and grammatical rules.
The scientific accumulations and progresses of the Western world in science and technology, pushed our nation into the circle of attraction of a different civilization especially in the nineteenth century. While in early periods the loan-words, taken from languages of local subjects or languages of other nations by military or commercial relations, were limited to a few objects and concepts missing in our language, after Tanzimat new desires and trends rose in the direction of entering to a different civilization circle, new ways of life, new thoughts carried new words with them. This situation in our language is, in a sense, a reflection of transformations and controversies in our social life.
Although there had been some efforts to supply substitutes for Western origin words using Turkish, Arabic or Persian, these did not accomplish the desired result in the long run. Western loan-words not only discarded Arabic and Persian words, they started to threaten the genuine Turkish words too. The role of admiration for the West can not be denied on this serious situation. But it is also necessary to accept the contribution of perplexing developments in science and technology. Statistical evaluation of scientific and technical developments reveals that accumulation of information in every field, doubles every 10 years. Hence the number of patents, machines, tools, scientific papers, journals and books increase geometrically. This rate of increas started to be felt strongly in the nineteenth century, enriched the civilization languages of nations accomplishing these discoveries by derivation of several new words from the source-languages.
Besides the technical and scientific terms compulsorily taken since Tanzimat, the words being most important creating greatest peril are stylistic ones. The words corresponding to names of concepts and objects already exist in our language. But the word is taken merely to create a completely new style and aura. Similar situations arose for languages we are
influenced by. For example, French was used as an official language by the British dudng the Middle Ages. Until 1731 French maintained its validity as the legal language in England. Therefore in the historical process English took 9 words in 12*, 134 words in 13"^, 306 words in 14"" centuries. In subsequent centuries 164, 157, 98, 59 and 71 words were taken respectively. In this respect English may be considered lucky for living and surviving this effect in a period where the languages were more static and renovations were scarce. French, however, having taken approximately a total of 100 English words till the end of 17* century, received 134 new words in 18* and 377 words in 19* centuries. This trend reached a very dangerous dimension in this century. Moreover, since the situation gained a stylistic character, French intellectuals started a campaign to save their language and issued a law in 1994 named after Jacques Toubon, the Minister of Culture of that time. By the expansion of American culture the same danger started now to threaten German as well. The reason for a greater destruction caused by alienation in our language since the late Ottoman era, is the coincidence of the admiration for Europe with the period of great explosions in the number of new discovedes and concepts. In our opinion the best remedy for this situation is to reinforce our identity consciousness.
References
Aksoy, Omer Asim (1973) Gelijen ve Ozle§en Dilimiz. TDK Yaymlan, 3. Baski, Ankara Universitesi Basimevi, Ankara.
Banguoglu, Tahsin (1981) On Yabanci Dilden Oztlirkçe (!) Kelimeler. Ya§ayan Tiirkçemiz, Tercüman Gazetesi Yaymlan, Kervan Kitapçihk, Istanbul, Sf. 73-77.
Cochran, W. G. (1963). Sampling Techniques. John Wiley and Sons, New York.
Dankoff, Robert (1991) Evliya Çelebi Lügati: Seyahatname'deki Yabanci Kelimeler, Mahalli ífadeler. Cambridge MA, Harward University Sources of Odental Languages and Literatures, 14. Dankoff, Robert (1995) Armenian Loanwords in Turkish. Harrasowitz verlag Wiesbaden.
Eren, Hasan (1995) Türkce'deki Ermeniee alintilar üzerine, Turk Dili, Sayi 524, Sf. 859-904. Eren, Hasan (1999) Turk Dilinin Etimolojik Sözlüp, Bizim Büro Basimevi, Ankara.
Ersoylu, Halil (1994 a) Türkiye Türkcesinin çagda§ problemleñ 4: Bau kaynakli kelimeler I, Turk Dili, Sayi 509, Sf. 375-384.
Ersoylu, Halil (1994 b) Türkiye Türkcesinin çagda§ problemled 5: Bati kaynakli kelimeler II, Turk Dili, Sayi 5i3, Sf. 200-212.
Hüseyin Kâzim Kadd (1927-1945) Büyük Turk Lügati. 4 eilt, Turk Dil Kurumu, Istanbul.
imer, Kâmile (1973) Turk yazi dilinde dil devriminin ba§langicindan 1965 yih sonuna kadar özle§me üzerine sayima dayanan bir arajtirma. AÜDTC Türkoloji Dergisi, Cilt 5, Sf. 175-190. Kerestedjiyan, Bedros (1912) Quelques matériaux pour un dictionnaire étymologique de la langue
turque. Luzac, Londra.
Korkmaz, Zeynep (1995) Bati kaynakii yabanci kelimeler ve dilimiz üzerindeki etkiled. Turk Dili, Sayi 524, Sf. 843-858.
Levend, Agâh Sirn (1972) Turk Dilinde Geli§me ve Sadele§me Evreleri. Ücüncü baski, Turk Dil Kurumu Yaymlan, Ankara Universitesi Basimevi. Ankara.
Meydan-Larousse (1979-1985) Büyük lügat ve ansiklopedi. Meydan Yaymlan, Istanbul.
Muallimoglu, Nejat (1999) TUrkçe Bilen Araniyor. Avciol Basimevi, ístanbul.
Özön, Mustafa Nihat (1962) Türkce Yabanci Kelimeler Sözlügü, ínkilap ve Aka Kitabevleri, ístanbul. Redhouse, Sir James. (1979) Redhouse yeni Türkce-íngilizce sözlük = New Redhouse
Turkish-English, Redhouse, ístanbul.
Sezgin, Fatin (1982) Turk Romaninda Batí Kaynakli Kelimeler ve bu Acidan Yazarlarimizm Siniflandinlmasi. IV. Milletler Arasi Türkoloji Kongresi, ístanbul.
Sezgin, Fatin (1993) Dil ye Edebiyatta ístatistik ve Bilgisayar Uygulamalan. Dergâh Yayinlan, Emek Matbaacihk, ístanbul.
Sezgin, Fatin (1999) Türkce'de Batí Kaynakli Kelimelerin Tarih ícindeki Seyri, Osmanh, Cilt. 9, Sf. 494-503, Editor: Güler Eren, Yeni Türkiye Yayinlan, Semih Ofset Basimevi, Ankara. Sunel, Hamit (1992) Çagda§ Turkçede Yabanci Dillerin Etkisi, Turk Dili, Sayi 485, Sf. 951-960. Çemseddin Sami (1901) Kamus-i Türkí, Dersaadet (1317).
§im§ir, Bilal N. (1992) Turk Yazi Devrimi, Atatürk Kültür, Dil ve Tarih Yüksek Kurumu Yaymlan, Turk Tarih Kurumu Basimevi, Ankara
TDK (1962) Dilde özle§menin sinin ne olmaiidir? Ankara Üniversitesi Basimevi, TDK Tanitma Yayinlan, Açikoturum Dizisi No. 1.
TDK (1988) Türkce Sözlük, 2 cilt. Atatürk Kültür, Dil ve Tarih Yüksek Kurumu Yaymlan, Turk Dil Kurumu, Turk tarih Kurumu Basimevi, Ankara.
Tuglaci, Pars (1971,1972) Okyanus, Ansiklopedik Sözlük, 6 cilt. Pars Yayinlan, ístanbul.
Ünver, ísmail (1991) Yabanci diller etkisinden kurtanlartiayan Türkcemiz. Turk Dili, Sayi 470, Sf. 77-79.
Tota l Weste m c: Unkn o ID O H Foreig n Tex t rivatio n D e
l i
Other s y riac CO c ea Arme n c ni CO avi e CO Germa n Lati n Gree k Italia n W Frenc h impl e ize s YEAR S 52 5 en o in o 2 in in 17 0 20 3 OO OO 00 in 187 0 ei s o _ O o o m _ NO C-J o in in 19 5 15 2 10 2 in NO 187 5 52 7 o „ o m o o "^ o o 15 8 13 8 19 8 0 0 188 0 eo e o NO es o o m 0 0 m en O N in OO NO m 32 2 r-188 5 0 0 O O O o r-o C O es O N OC en r-. (N 18 1 13 7 en 12 9s
189 0 89 0 32 6 es O es O s OC m in 20 0 12 7 -19 5S
189 5 74 0 CN en O O m O -en CN -26 8 12 1 12 31 2 190 0 39 3 o _ O NO O (N _ o m 12 9 en 15 7 CN 190 5 73 4 in en Ov CN O OJ oc m 19 7 16 9 in CN 30 0 00 N O 191 0 36 6 m in O t^ O o -ON m in in en Os 16 0 191 5 191 3 tN OC o NO O NO in O N o 60 2 38 8 m 80 3 16 3 192 0 415 2 00 m Ovs
18 4 un OO OO (N S OO O CN es 104 4 39 6 13 5 170 4 30 9 192 5 358 7 OC in es in tN OC es se t m in (N CN CN 0S 8 69 9 o OO 171 2 02: s 193 0 330 7 oc NO oc Ov O r-in en CN m m in os en en es 66 3 63 5 r-162 2 19 2 193 5 263 0 r-es o es oc ON OO in m O CN OO CN en NO 57 7 ON 116 6 19 7 1 194 0 211 8 es in o en es in m 0 0 r-Ol es 90 S eo s 89 5 15 4 1 194 5 8 IO S O fN 15 4 CN •O es m 13 9 oc in 79 3 94 7 21 0 267 8 26 6 1 195 0 618 2 — o m 22 6 o o m es ON 17 7 oc m O N OO •il-in 122 3 138 0 33 4 272 2 41 6 1 195 5 713 8 m OO r-en 34 4 '^ m r^ in 23 2 so t 154 1 199 9 23 6 273 3 41 6 1 196 0 442 5 es OO m 25 6 m QO O es m in O N CN 36 6 107 5 14 9 174 4 31 0 196 5 1051 9 CN es 10 9 13 3 66 2 OC NO es m m 16 8 22 7 m 11 6 10 2 206 9 205 0 40 8 505 6 72 2 1 197 0 951 7 SO l 59 8 O O r-(N 10 9 23 2 CN 10 3 in OO 157 3 189 6 43 9 479 5 64 8 197 5 851 6 o 18 8 52 1 OO r-O m o 21 2 Ov O N 11 2s
133 2 167 6 30 1 436 6 52 0 198 0 1044 7 r-O »n 32 3 53 6 O m in OO 89 ! OO a\ 00 163 3 199 5 34 1 536 0 53 4 198 5 812 2 (N m o 13 0 38 0 O O m es m m <n NO 11 6 ON tN 122 1 134 1 32 9 452 4 40 5 1 199 0 579 2 \D r j 26 2 O^ 2 O en OO es 11 5 O O 85 9 99 2 27 4 318 3 27 2 1 199 5 a, a o o S T3 (U .g q C '5bI
•H o s TUBA 30/ni, 2006o