Privacy preserving and robust watermarking on sequential genome data using belief propagation and local differential privacy
Tam metin
Şekil
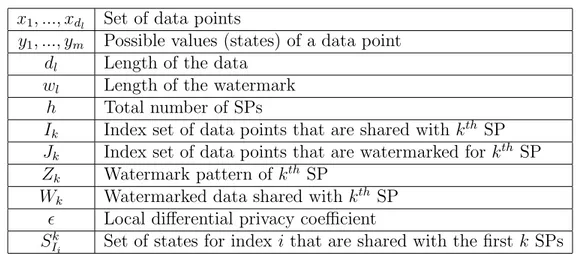
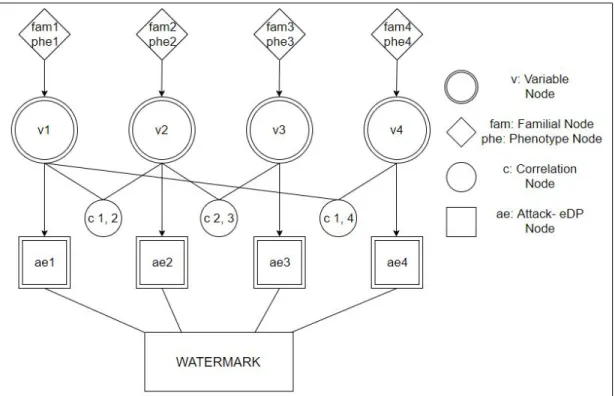
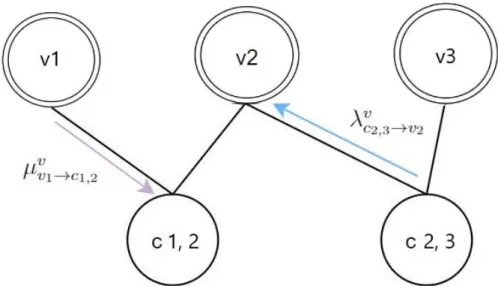
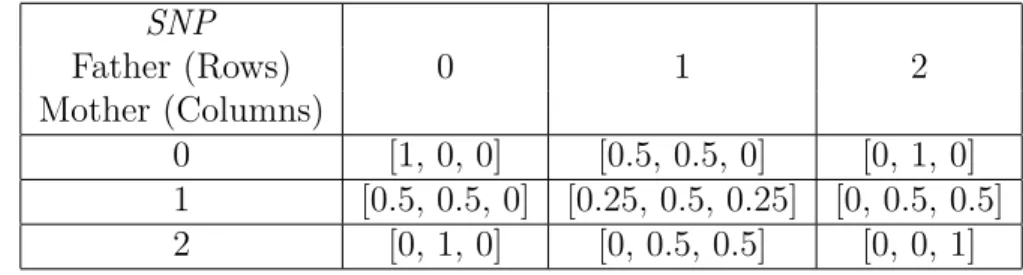
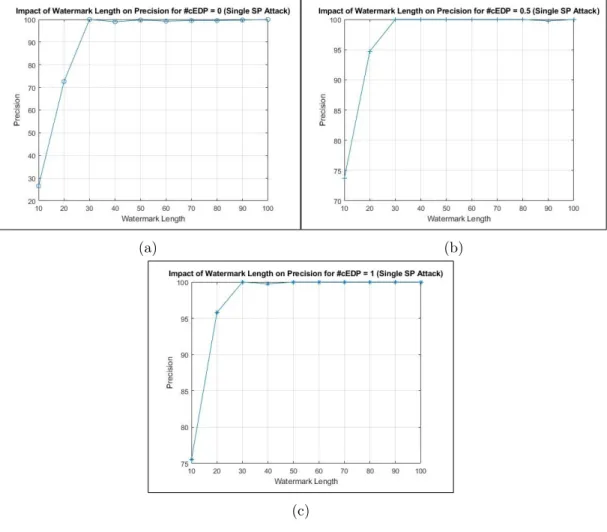
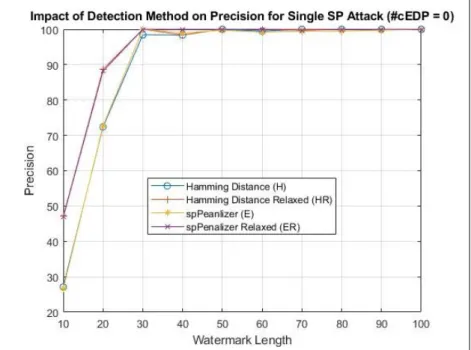
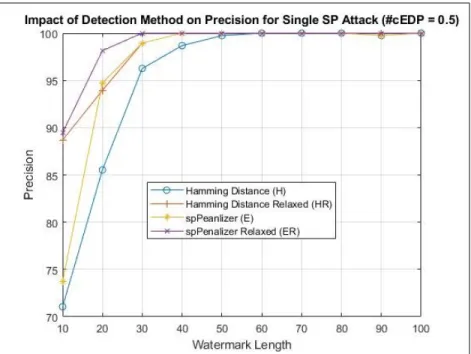
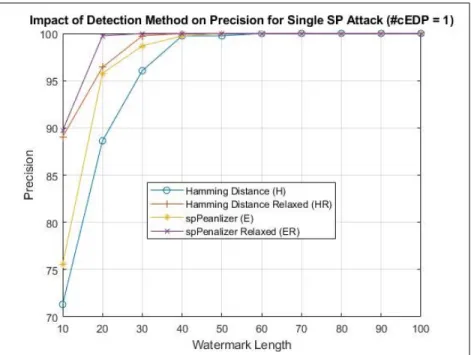
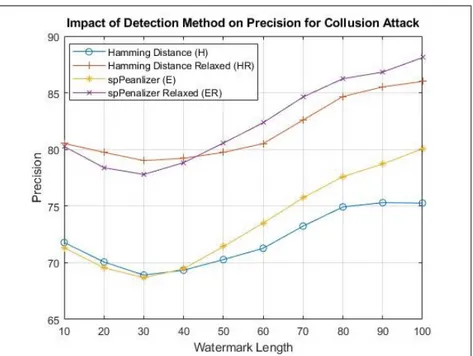
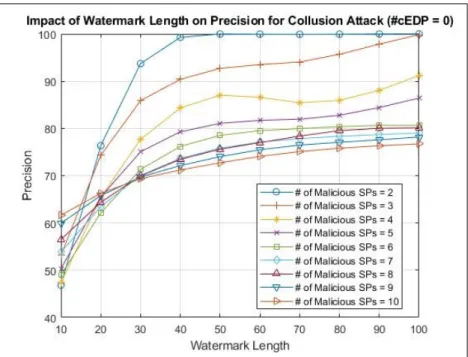
Benzer Belgeler
The importance of the less hierarchical, democratic organizations and having an institutional culture were the final topics of the meeting. The marketing and the
The coincidence of trading strategies could have different implication for the stock price formation for these institutions could be following each other due to their correlated
It is suggested (Frerichs, 2008: 3) that random sampling is a statistical sampling method where each unit remaining in the population has the same probability of being
The two main features of the interaction to be simulated within our model are (i) the oscillatory energy difference between the ferromagnetic and the antiferromagnetic ground
Learner-based Feature Selection is a popular feature selection technique that uses a generic but powerful learning algorithm and evaluates the performance of the algorithm on the
• Since differential privacy is a relatively new notion, a lot of useful data mining methods that can be used in LA have not yet been implemented using differential privacy (e.g.,
internal or external locus of contol' established as determining As already mentioned, an additional purpose of the research was schooVdepartment of business the namely samples, two
Bu problemin çözümü için geliştirilen yeni kuşak po- likarboksilat esaslı katkılar ve onların özel olarak hazırlanan karışım bileşimi içinde kullanılması ile
