Computationally highly efficient mixture of adaptive filters
Tam metin
Şekil

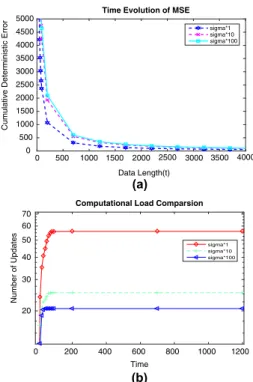
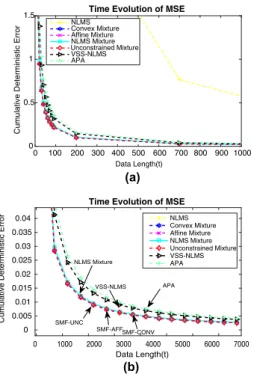

Benzer Belgeler
In this chapter we explore some of the applications of the definite integral by using it to compute areas between curves, volumes of solids, and the work done by a varying force....
Bununla beraber bir planın plan olabilmesi için yalnızca amaçları değil; aynı zamanda o amaçlara ulaşacak araçları da içermesi gerekir (Yılmaz, 1999: 87). Görüleceği
In future, we plan to study sol-gel phase transition and critical behaviours for other mixed polymeric systems by using fluorescence technique, which allow us to investigate
The first bieng that space was broken down into two factors the physical and emotional and both were examined as to the level of relation between them, secondly
HIGHER ORDER LINEAR DIFFERENTIAL
Therefore, using real-life problems such as the turtle paradox (Duran, Doruk & Kaplan, 2016) and the water tank problem that was used in this study in the teaching process of
This different behavior according to the theory previously estaslished occurs because the creep behavior of polyethyle- ne that has a high degree of crystallinity are
According to Léon-Ledesma and Thirlwall (2002), the endogeneity of the natural growth rate means that full employment ceiling is not constant; it can increase und er
