Başlık: ROBUST ESTIMATION AND HYPOTHESIS TESTING IN 2k FACTORIAL DESIGN Yazar(lar):ŞENOĞLU, BirdalCilt: 56 Sayı: 2 DOI: 10.1501/Commua1_0000000188 Yayın Tarihi: 2007 PDF
Tam metin
Şekil

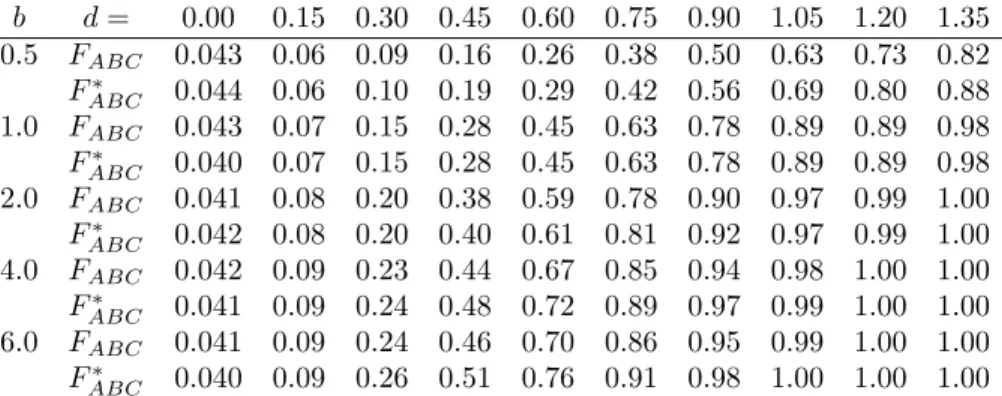
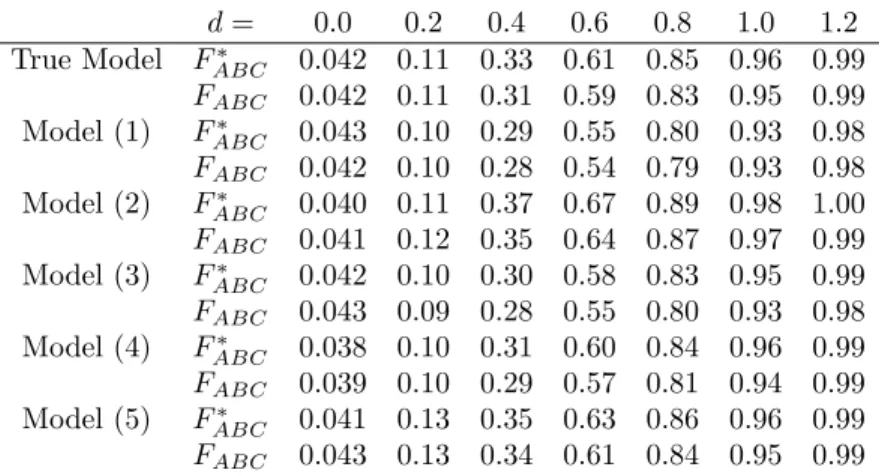
Benzer Belgeler
This article provides an overview of ther- apeutic vaccines in clinical, preclinical, and experimental use, their molecular and/or cellular targets, and the key role of adjuvants in
Extensions of the restricted scheme and an alternative scheme that aims to maximize the num- ber of disabled target nodes (whose CRLBs are above a preset level) are considered, and
This study aims to examine EFL learners’ perceptions of Facebook as an interaction, communication, socialization and education environment, harmful effects of Facebook, a language
Sonuç: Kollum femoris ve intertrokanterik femur kırığı olan ve parsiyel kalça protezi yapılan ileri yaş grubundaki hastalarda kan transfüzyonu miktarları arasında
We compared the micromachining performance of the 1 ns, 3.1 MHz laser system with an industrial fiber laser producing 100 ns-long pulses at 31 kHz and an ultrafast fiber laser
For matrices, Compressed Sparse Row is a data structure that stores only the nonzeros of a matrix in an array and the indices of the nonzero values [14].. [18] introduces a
In this study the electrochemical impact of Li 2 O/metal mole ratio on the cycle life of lithium-ion battery anode materials is demonstrated. Battery tests show that
Yapısal değişimleri dikkate alan ve kalıntıların normal dağılmadığı durumlarda güçlü sonuçlar veren RALS-FSURADF panel birim kök testi sonucuna göre Belçika,
