Banka İflaslarının Öngörülmesinde Eklektik
Bir Yaklaşım
Doç. Dr. Soner Akkoç
*Yrd. Doç. Dr. Nilüfer Dalkılıç
**Yrd. Doç. Dr. Ayşen Altun Ada
***Öz
Gerek ülke ekonomileri gerekse yatırımcılar açısından büyük önem taşıyan banka iflaslarının öngörüsünde, öngörü modellerinin geliştirilmesi ve birçok değişken arasından hangisinin modellemede kullanılacağı önem arz etmektedir. Bu çalışma, Türk bankacılık sektörünün iflas riskinin değerlendirilmesinde, diskriminant analizi, lojistik regresyon ve temel bileşen analizi yöntemleri ile temsil gücü yüksek değişkenler belirlendikten sonra, iflas öngörüsünde yapay sinir ağları kullanarak öngörü modelleri geliştirmeyi amaçlamaktadır. Elde edilen sonuçlar, yapay sinir ağlarının, banka iflas tahmininde etkin olarak kullanılabildiğini ve lojistik regresyon analizinin en iyi değişken seçen yöntem olduğunu göstermektedir.
Anahtar Kelimeler: Değişken Seçimi, İflas Tahmini, Yapay Sinir Ağları. JEL Sınıflaması: G01, G33, C40.
An Eclectic Approach to the Prediction of Bank Bankruptcies Abstract
Developing prediction models and determining which variables among many others will be used in modelling are very important for the prediction of bank failures, which is a significant issue for both national economies and investors. This study first identifies the highly representative variables via discriminant analysis, logistic regression and principal component analysis methods for the evaluation of the failure risk of the Turkish banking sector. Then, it aims to develop prediction models for failure predictions by using artificial neural networks. Results obtained show that artificial neural networks can be used in predicting bank failures and logistic regression analysis is the best method for selecting variables.
Keywords: Selection Variable, Bankruptcy Prediction, Neural Networks. JEL Classification: G01, G33, C40.
1.Giriş
Banka iflasları ülke ekonomileri, düzenleyici ve denetleyici kurumlar ve yatırımcılar açısından büyük önem taşımaktadır. Bankaların başarısızlığa sürüklendiğine işaret eden uyarı sinyalleri, çok daha önce ortaya çıkmaktadır (Ashoori ve Mohammadi, 2011, s. 568). Bu sebeple, söz konusu sinyaller başarısızlığın önceden tahmin edilmesine yönelik öngörü modellerinde girdi değişkenleri olarak ele alınabilmektedir. Banka iflaslarının öngörüsü ve olası kayıpları azaltmaya dönük olarak veri madenciliği ve makine öğrenme teknikleri etkin bir şekilde kullanılmaktadır (Onan, 2015, s. 9).
Öngörü modellerinin geliştirilmesinde önemli aşamalardan birisi değişken seçimidir. Belirli bir veri setinden temsil gücü yüksek verileri seçmek önemli bir adımdır ancak seçim * Dumlupınar Ünv, Uygulamalı Bilimler Yüksekokulu, Bankacılık ve Finans Bölümü Öğretim Üyesi. **
Dumlupınar Ünv, Uygulamalı Bilimler Yüksekokulu, Sigortacılık ve Risk Yönetimi Bölümü Öğretim Üyesi.
yöntemlerinden hangisinin daha iyi olduğu bilinmemektedir (Tsai, 2009, s.120). İflas tahminine ilişkin deneysel literatür 1960’lı yıllara dayanmakla birlikte son zamanlarda ivme kazanmış ve finans kurumlarının dikkatini üzerinde toplamıştır. Akademisyenler ve uygulayıcılar, bankalar ile firmalar arasındaki asimetrik bilgi sorununun, piyasa başarısızlıklarının temelinde yattığının ve izleme tekniklerinin geliştirilmesinin, borçlu tarafın manevi zararının azaltılmasını amaçlayan eksik düzenlemelere önemli bir alternatif sağlayacağının farkına varmıştır (Tseng ve Hu, 2010, s. 1846). İflas öngörü çalışmalarında hangi değişkenlerin daha başarılı olduğunu araştıran veri azaltma araştırmaları ise 2000’lerin ortalarında yapılmaya başlanmıştır.
İflas tahmininde yapay zeka teknolojilerinden biri olan “yapay sinir ağları (neural
network)” en çok kullanılan modellerdendir. Yapay sinir ağları modeli kullanarak Türkiye
bankaları veri setleri üzerinde yapılan araştırmalar genellikle iflas öngörüsüne yöneliktir. Örneğin; Acar Boyacıoğlu ve Kara (2007), Yıldız ve Akkoç (2009) çalışmalarında, finansal güç ve başarı tahminlerinde kullanılacak tekniklerin belirlenmesini ve bu tekniklerin doğru sınıflandırma başarılarını değerlendirmektedirler. Acar Boyacıoğlu ve Kara (2007) yapay sinir ağları modelinin diğer çok değişkenli istatistiksek analiz teknikleri ile kıyaslandığında oldukça başarılı olduğu sonucuna ulaşırken, Yıldız ve Akkoç (2009) sinirsel bulanık ağ modeli için aynı sonuca ulaşmıştır. Keskin Benli (2005) ise lojistik regresyon ve yapay sinir ağı modeline dayanan öngörü modelleri geliştirdiği çalışmasında her iki modeli mali başarısızlığı öngörme gücü açısından karşılaştırmıştır. Elde ettiği sonuç, lojistik regresyon modelinin öngörü başarısı yüzde 76,5 iken yapay sinir ağları modelinin yüzde 82,4 olduğudur. Canbaş ve diğerleri (2005), bütünleşik erken uyarı sisteminin kurulmasına yönelik metodolojik bir çerçeve önerdikleri çalışmalarında temel bileşen analizini kullanmışlardır. Sistemin banka denetlemede etkin bir şekilde kullanılmasının banka yapılandırma maliyetini uzun vadede önemli oranda azaltabileceğini ortaya koymuşlardır. Acar Boyacıoğlu ve diğerleri (2009) çalışmalarında, tahmin performansını iyileştirmek için resmi finansal veriler kullanılarak, çeşitli özelliklere sahip 4 farklı veri kümesi geliştirmişler ve tüm veri kümelerini eğitim ve doğrulama kümesi olmak üzere ikiye ayırmışlardır. Elde ettikleri sonuçlara göre, çok katmanlı algılayıcı ve öğrenme vektör nicelemesi bankaların mali başarısızlıklarını tahmin etme konusunda en başarılı modellerdir.
Bu çalışmada ise, hem banka iflaslarının öngörüsünde yapay sinir ağlarının başarısı ölçülmekte, hem değişken seçim yöntemlerinden hangisinin daha başarılı olduğu araştırılmakta, hem de yapay sinir ağları modelleri için en uygun parametreler tespit edilmeye çalışılmaktadır. Yapay sinir ağları modelleri geliştirilirken bazı parametrelerin başlangıç değerlerinin belirlenmesi gerekmektedir. Bu alanda henüz bir teorinin bulunmamasından dolayı söz konusu parametrelerin belirlenmesinde deneme yanılma yöntemi kullanılmaktadır. Uygun modelin bulunması onlarca denemenin yapılmasını gerektirebilmektedir. Bu durum ise oldukça zaman almaktadır. Bu çalışmada aynı zamanda iflas öngörüsünde yapay sinir ağları modelleri için öğrenme oranı, momentum katsayısı ve gizli katmandaki düğüm sayısı parametreleri için en uygun değerler araştırılmaktadır. Bu yönleri ile Türkiye bankaları için yapılan diğer çalışmalardan ayrılmaktadır.
Çalışmada, yapay sinir ağları yöntemi kullanılarak öngörü modellemesi yapılmakla
birlikte diskriminant analizi, lojistik regresyon analizi ve temel bileşen analizi yöntemleri
kullanılarak değişken seçimi gerçekleştirilmektedir. Temsil gücü yüksek değişkenlerinin belirlenmesi ve modelin bu değişkenler ile oluşturulması, kurulan modelin performansını arttırabilmektedir. Söz konusu yöntemler ile temsil gücü yüksek değişkenler belirlendikten sonra, iflas öngörüsünde oldukça başarılı sonuçlar üreten yapay sinir ağları kullanılarak öngörü modelleri geliştirilmektedir. Değişken seçiminde hangi yöntemin daha başarılı olduğu ve iflasların öngörüsünde hangi değişkenlerin önemli olduğu tespit edilmeye çalışılmaktadır.
Çalışmanın izleyen ikinci bölümünde konu ile ilgili uluslararası çalışmalar aktarılmakta, üçüncü bölümde yapay sinir ağları modeli incelenmektedir. Dördüncü bölümde ise değişken seçiminde kullanılan yöntemler ile veri seti açıklanarak elde edilen bulgular tartışılmaktadır. Ampirik analizler değerlendirilerek çalışma sonlandırılmaktadır.
2. Literatür Taraması
Cielen ve diğerleri (2004), veri zarflama analizi ve karar ağacı modelinin sınıflandırma performansını karşılaştırdıkları çalışmalarında; iflas tahmininde Belçika bankaları için analizlerde bulunmuşlardır. Kesinlik, maliyet, yerleştirme ve anlaşılabilirlik açısından karar ağaçlarına göre veri zarflama analizinin daha iyi bir performans sergilediği sonucuna
ulaşmaktadırlar. Tseng ve Lin (2005) çalışmalarında, ikili yanıt değişkenleri için kuadratik
programlama yaklaşımına dayalı lojistiğin kuadratik aralık regresyon modelinin avantajlı yönlerini bir araya getiren kuadratik aralık lojistik modeli önermektedirler. Modellerini Birleşik Krallık’ta şirketlerin karşılaşacakları mali sıkıntıları tahmin etmek için kullanmışlardır ve modelin gruplar arası ayrım yapmada lojistik modele yardımcı olabileceği ve araştırmacılara daha fazla bilgi sağlayabileceği sonucuna ulaşmışlardır. Kuadratik aralık lojistik modelinin hangi şirketlerin iflas edip etmeyeceğini ve hangilerinin durumunun belirsiz olduğunu tahmin edebildiği, elde ettikleri diğer bir önemli sonuçtur. Tsai (2009), iflas tahmininde yaygın olarak kullanılan 5 adet özellik seçim yöntemini karşılaştıran bir çalışma yapmıştır. Çok katmanlı algılayıcı sinir ağlarının, tahmin modeli olarak kullanıldığı çalışmada, t-testi, korelasyon
matrisi, stepwise regresyon, temel bileşen analizi ve faktör analizinin tahmin performansları
karşılaştırılmıştır. Karşılaştırma yaparken Avustralya Kredi, Alman Kredi, Japon Kredi ve İflas veri seti ile UC Rekabet veri seti kullanılmıştır. Elde ettikleri sonuçlara göre, ortalama olarak t-testi diğerlerinden üstündür. Orijinal değişkenlerin azaltılma yüzdesinde bakıldığında ise, en yüksek özellik azaltım oranını yakalayan stepwise diğer testlerden daha başarılı olarak çıkmaktadır.
Chauhan ve diğerleri (2009), Amerikan Bankaları, Türk Bankaları ve İspanyol Bankaları’na ilişkin iflas tahminine yönelik veri kümeleri ile dalgacık sinir ağı modeli eğitimi için diferansiyel gelişim algoritmasının etkinliğini test etmişlerdir. Diferansiyel gelişim eğitimli dalgacık sinir ağı, Türk bankaları veri kümeleri dışındaki tüm sorunlarda kesinlik ve hassaslık açısından alt sınır kabul eden eğitimli dalgacık sinir ağının önüne geçebilmektedir. Kurulan modellerde en yüksek başarı oranı sırası ile Türkiye, Amerika ve İspanya veri seti için gerçekleşmiştir. Lin ve diğerleri (2009), Tayvan’da faaliyet gösteren ticari bankaların performanslarının tahmini için çalışmalarında parçacık sürü optimizasyonu (PSO) uygulamışlardır. Çalışmada destek vektörü makinesi (SVM) ve karar ağacı için uygun parametre ayarları elde etmek ve sınıflandırma kesinlik oranını düşürmeksizin faydalı özelliklerden oluşan bir alt küme seçmek amaçlanmıştır. Analizler, gereksiz özelliklerin azaltılabileceğini ve sınıflandırma kesinlik oranında önemli bir artış sağlanabileceğini göstermektedir. Ravisankar and Ravi (2010), çalışmasında bankalardaki iflas tahmin hesaplamalarında kullanılan; Veri İşleme Grup Yöntemi (GMDH), Karşı Yayılım Sinir Ağı (CPNN) ve Bulanık Uyarlanabilir Rezonans Teori Haritası (fuzzy ARTMAP) tekniklerini kullanmışlardır. Bu tekniklerin her birinin verimliliği, İspanya bankaları, Türkiye bankaları, İngiltere bankaları ve ABD bankalarına ait dört farklı veri seti kullanılarak test edilmiştir. Elde edilen sonuçlar, GMDH’nin özellik seçimi bulunan veya bulunmayan tekniklerden tüm bankalar için en iyi sınıflandırma yöntemi olduğunu göstermektedir. GMDH–GMDH ve
t-istatistik-GMD gibi karma tekniklerin, tüm bankaların veri setlerindeki özellik seçiminden
sonra en iyi performans sağlayan teknikler olduğu görülmüştür.
Demyanyk ve Hasan (2010), Amerika Birleşik Devletleri’ndeki “yüksek eşikli ipotekli
konut kredisi (subprime mortgage)” krizine neden olan finansal ve ekonomik koşulları analiz ettikleri çalışmalarında, banka başarısızlıklarını öngörmek için yöneylem araştırma literatüründe kullanılan teknikleri incelemişlerdir. Elde ettikleri sonuçlar neticesinde, finansal
krizleri analiz ederken yöneylem araştırma tekniklerinin daha fazla kullanılmasını önermektedirler. Cho ve diğerleri (2010), çalışmalarında etkili bir iflas tahmini için melez bir yöntem sundukları çalışmalarında karar ağaçlarını kullanan değişken seçimi ve Mahalanobis uzaklığını kullanan durum tabanlı çıkarsamayı bir araya getirmektedirler. 1000 üretici Güney Kore firması için analizler yapmışlardır. Karar ağacı indüksiyonu ile seçilen değişkenlerin, regresyon yaklaşımlarıyla elde edilen değişkenlere kıyasla daha fazla etkileşim içinde olduğunu ve değişkenlerin birbiriyle korelasyon halinde olduğunda, Mahalanobis uzaklığının, Öklid uzaklığına göre yakınlığı daha doğru ölçtüğünü belirtmektedirler. Tseng ve Hu (2010) çalışmalarında, lojistik model, kuadratik aralık lojistik model, geriye yayılımlı çok katmanlı algılayıcı ve radyal taban fonksiyon ağı olmak üzere dört farklı teknik kullanarak İngiltere firmalarının iflas durumlarını tahmin etmeye çalışmaktadırlar. Elde ettikleri sonuçlara göre, radyal taban fonksiyon ağı diğer modellerden daha üstün performans sergilemekte, ardından geriye yayılımlı çok katmanlı algılayıcı, berraklaştırma kuadratik aralık lojistik modeli ve lojistik modeli gelmektedir. Chen ve diğerleri (2011), analizlerinde Tayvan Menkul Kıymetler Borsasında yer alan 40’ı iflas etmiş olan 160 elektronik şirketinden faydalanmıştır. Veriler, işletme başarısızlık tahmin sisteminin geliştirilmesinde kullanılmıştır ve finansal krizin başlamasından önce birinci çeyrekten dördüncü çeyreğe kadar test edilmiştir. Şirketlerin finansal başarısızlıklarını öngörülmesini sağlayacak bir model oluşturmak için adaptif ağ tabanlı bulanık çıkarım sistemi (ANFIS) kullanılmıştır. Analizler sonucunda, tek dereceli momentum yönteminin çevrimiçi öğrenme için uygun, 2 dereceli momentum modelinin
aşamalı öğrenme için uygun olduğunu göstermektedir. Chen ve diğerleri (2011)
çalışmalarında, uyarlamalı bulanık k-en yakın komşu (FKNN) yöntemini temel alan yeni bir iflas tahmin modeli sunmaktadırlar. 112’si iflas etmiş olan toplam 240 Polonya şirketi için yapılan analizlerde, önerilen iflas tahmin modelinin, iflas tahmini için güçlü bir erken uyarı
sistemi olmaya aday olduğunu savunmaktadırlar. Aynı zamanda modelin, ayırt edici bir
finansal oranlar altkümesini tespit ettiğini ve yüksek performansa sahip bilgisayar teknolojisi sayesinde oldukça etkin bir şekilde hesaplama yapabildiğini belirtmektedirler. Lin ve diğerleri (2011) çalışmalarında tahminlerdeki doğruluk oranlarını arttırabilmek adına fayda sağlayabilecek nitelikte olup henüz keşfedilmemiş mali olguların ortaya çıkarılmasını amaçlamışlardır. Taiwan Economic Journal veri tabanından yaralanmışlar ve 74 mali oran ile veri madenciliği tekniğini kullanmışlardır. İflasın öngörüsünde kendi önerdikleri modelin, tahminlerin doğruluğu açısından daha önceki araştırmacıların ortaya koyduğu modellerden daha başarılı bir performans sergilediğini iddia etmektedirler.
Sanchez-Lasheras ve diğerleri (2012) çalışmalarında, inşaat sektöründe faaliyet gösteren İspanyol firmalarını ele alarak, firma iflaslarının öngörülmesinde kullanılacak yeni bir yaklaşım sunmaktadırlar. Sundukları melez yöntemde şirketler Kendi Kendini Düzenleyen Haritalar (SOM) kullanarak kümelere ayrılmakta ve daha sonra her küme bütün hepsini özetleyen bir yön vektörü ile değiştirilmektedir. Kümelerdeki şirketlerin yön vektörüyle değiştirilmesinin ardından Çok Değişkenli Uyarlanabilir Regresyon Eğrileri (MARS) ile bir sınıflandırma modeli kullanılmasını önermektedirler. Geriye yayılımlı yapay sinir ağı ve MARS modeli tekniklerini kullandıkları çalışmalarında, önerilen melez yaklaşımın iflas eden şirketlerin tespitinde kıyaslama tekniklerinden daha doğru sonuçlar verdiğini belirtilmektedirler. Andres ve diğerleri (2012), iflas tahmini sorununu ele aldıkları çalışmada geleneksel göstergelerin yerine multinorm analizinin sonuçlarının kullanılmasının önerildiği bir model öngörmektedirler. Standart sınıflayıcılardan yararlanmışlar ve firma performansına ilişkin güvenilir temsilciler elde edebilmek amacıyla her bir oranı, doğrusal olmayan bir endüstri normları sistemine ait sapmalarla değiştirmişlerdir. Bu model firmaların iflaslarını tahmin etmede kullanılmış ve İspanyol üretici firmaların temsili veri setleri üzerinde test edilmiştir. Elde ettikleri sonuç, yaklaşımın hem lineer hem lineer olmayan sınıflandırıcılarda tahminlerin isabet oranlarına büyük katkı sağlayacağıdır. Wang ve diğerleri (2014), çalışmalarında kurumsal iflas tahmininde kullanılabilecek bir yöntem olan FS-Boosting ile kurumsal iflas tahmininde kullanılan bagging ve boosting gibi birçok yöntemi karşılaştırmışlardır. Zaman aralıkları faklı olan ve toplam 372 firmayı içeren iki gerçek dünya
iflas veri seti kullanılmıştır. Elde ettikleri sonuçlar, FS-Boosting yönteminin kurumsal iflas tahmininde alternatif bir yöntem olarak kullanılabileceğini göstermiştir. Temel öğreniciler açısından daha doğru ve farklı sonuçlar verdiği, daha iyi bir performans sergilediği için yöntemi önermektedirler.
3. Yapay Sinir Ağları
Yapay zeka teknolojileri değişkenler arasında doğrusal olmayan bir ilişki bulmaya çalışırken kullanılan etkili yöntemlerdendir. Yapay zeka teknolojileri kullanılan araştırmaların çoğu, geleneksel istatistiki yöntemlere göre daha kesin tahminlerde bulunma olasılığı göstermektedirler. Yapay zeka teknolojilerinden biri yapay sinir ağları (YSA) yöntemidir (Cho ve diğerleri, 2010, s. 3483). YSA’nın iflas tahminlerinde kullanılmasına yönelik araştırmalar 1990 yılında başlamış olup, günümüzde de devam etmektedir ve iflas tahmini problemlerinde yaygın olarak kullanılmaktadır (Olson ve diğerleri, 2012: 467-468; Ashoori ve Mohammadi, 2011, s. 569). Son dönemde yürütülen ticari başarısızlık ve iflas tahmini çalışmalarında YSA modelleri kullanılarak başarılı sonuçlar elde edilmiştir. Geçmiş çalışmalar kapsamında yapılan araştırmalar, YSA modellerinin hem klasik istatistiki yöntemlere hem de diğer yapay zekâ yaklaşımlarına kıyasla daha yüksek sınıflandırma kesinliği sağladığını göstermiştir (Ashoori ve Mohammadi, 2011, s. 570).
YSA canlı varlıklardan ilham alan ve son derece karmaşık yapıdaki doğrusal olmayan fonksiyonların modellemesini yapabilen analitik yöntemdir (Olson ve diğerleri, 2012, s. 466). Bilgiyi deneyimlerinden alır, önceki deneyimler ışığında yeni deneyimlere yönelik öngörü gerçekleştirmektedir (Ashoori ve Mohammadi, 2011, s. 569). YSA modellerinin veri uyumlaştırma kapasiteleri yüksektir ve özellikleri itibariyle, çok karmaşık düğüm bağlantılarını ve ağırlık dizilerini içermektedir (Olson ve diğerleri, 2012, s. 464). YSA uyarlanabilir öğrenme özellikleri sayesinde model sınıflandırılmasında kullanılan etkili araçtır. Yöntem gözlem sayısı konusunda da daha az kısıtlama içermektedir. YSA’yı destekleyen bir nicel teori yoktur. İşleyiş süreci, en çok etkiyi hangi değişkenin yaptığını belirlemenin güç olması gibi özellikleri ile kapalı bir kutuya benzemektedir (Tseng ve Hu, 2010: 1850). YSA, modele ilişkin önceden yapılacak herhangi bir varsayıma ihtiyaç duymamaktadır ve karmaşık, doğrusal olmayan ilişkiler konusunda çıkarımda bulunma yeteneğine sahiptir (Lin ve McClean, 2001, s. 193).
Çalışmada geri yayılımlı çok katmanlı algı yöntemi (ÇKA) sinir ağı mimarisi kullanılmıştır. İflas tahmini gibi ikili sınıflandırma problemlerinde en çok kullanılan sinir ağı modeli çok katmanlı algı ağıdır (Ashoori ve Mohammadi, 2011, s. 569-570). 1990’lardan bu yana, geri yayılım algoritması barındıran ÇKA’nın yakınsama veya sınıflandırma özellikleri başta olmak üzere nicel iflas tahmini araştırmalarında en sık kullanılan yöntem YSA’dır
(Tseng ve Hu, 2010, a.1846). ÇKA yöntemi hem tahminleme hem de sınıflandırma türü
tahmin problemlerinde kullanılan güçlü fonksiyon yakınsayıcısı olarak görülmektedir. ÇKA yöntemi karmaşık, doğrusal olmayan fonksiyonları istenen kesinlik düzeyinde öğrenme yeteneğine sahiptir (Olson ve diğerleri, 2012, s. 466). YSA mimarisine ilişkin şekil aşağıda verilmiştir.
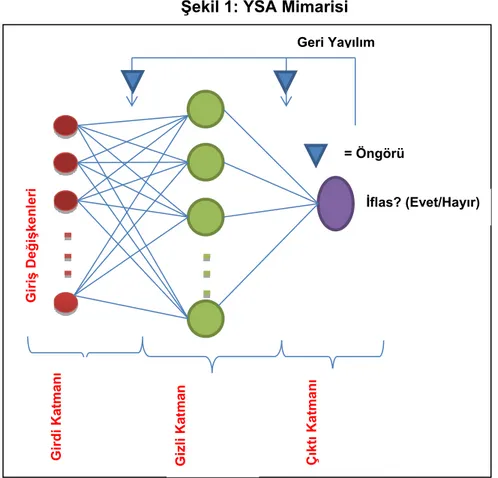
Şekil 1: YSA Mimarisi
Kaynak: Olson ve diğerleri, 2012, s. 466.
Bir ÇKA ağı; girdi düğümü olarak bir dizi duyumsal düğüm içeren bir girdi katmanı,
bilgisayım düğümlerinden oluşan bir ya da daha fazla gizli katman ve yine bilgisayım düğümlerinden oluşan çıktı katmanı içermektedir. Girdi düğümleri bir örneğin nitelik değerleridir; çıktı düğümleri ise örneğin ait olduğu sınıfı temsil etmektedir. Ara bağlantıların her biri, eğitim aşamasında ayarlanan basamaklı ağırlıklarla ilişkilendirilmiştir. ÇKA; girdi katmanı, çıktı katmanı ve gizli katmanlar barındıran üç katmanlı, tam bağlantılı, ileri beslemeli bir ağ olarak tanımlanır (Ashoori ve Mohammadi, 2011, s. 569-570).
4. Ampirik Çalışma
Bu çalışmada diskriminant analizi, lojistik regresyon analizi ve temel bileşenler analizi iflas öngörüsü için değişken seçim yöntemleri olarak kullanılmıştır. Böylelikle, bu yöntemler tarafından iflas eden ve etmeyen bankaların sınıflandırılmasında önem arz eden değişkenler tespit edilmiştir. Sonrasında YSA ile iflas öngörüsü gerçekleştirilmiştir. Dolayısıyla uygulama iki aşamadan oluşmaktadır.
4.1. Değişken Seçiminde Kullanılan Yöntemler
Değişkenlerin ve niteliklerin seçimi, ticari başarısızlık tahmin sürecinde çok önemli bir aşamadır (Ashoori ve Mohammadi, 2011, s.568). Çalışmada bankaların iflas öngörüsünde kullanılmak üzere 36 değişken ele alınmıştır. Bu değişkenlerin hangilerinin önemli olduğu ve hangi değişkenler ile YSA modelinin daha başarılı sonuçlar vereceğini araştırmak üzere değişken seçim yöntemleri kullanılmıştır. Bu yöntemler; diskiriminant analizi, lojistik regresyon analizi ve temel bileşen analizidir.
Gi riş Değişk e nl er i Gi rdi Ka tma nı Gi zli Ka tma n Çıktı Katm anı = Öngörü İflas? (Evet/Hayır) Geri Yayılım
4.1.1. Diskiriminant Analizi
Diskriminant analizi (DA), çoğu alanda uygulanan geleneksel istatistiki bir yöntemdir (Chen ve Hsiao, 2008, s.1148). DA, iflası etkileyen unsurların belirlenmesinde öncü bir istatistiksel yaklaşım olmuştur ve analizde, sınıflandırılacak unsurların belli başlı özelliklerine dayanan grup üyeliği tahmin edilmektedir (Lin ve McClean, 2001, s.192; Cho ve diğerleri, 2010, s. 3482).
DA, bağımsız değişkenlerin çok değişkenli normalliği ve grupların varyans-kovaryans matrisleri eşitliği gibi belli istatistiki gereklilikler yüklemektedir (Vuran, 2009, s.50). Analiz yapılan çalışmaların çoğunu, ayrışık iki grubu ele almıştır. Bazı çalışmalar aşağıdaki lineer diskriminant analiz eşitliğini kullanmıştır (Bramhandkar, 1989, s.37):
𝑍 = 𝑊1𝑋1+ 𝑊2𝑋2+ ⋯ + 𝑊𝑛𝑋𝑛 (1)
Yukarıdaki lineer sınıflandırma prosedürü, değişkenlerin varyanslarının iki grupta da aynı olduğu ve kovaryans matrislerinin eşit olduğu durumlar için en uygundur (Bramhandkar,
1989: 37). Yöntem, farklı grupların tahmininde kullanılması ile birlikte çok kriterli gruplardan
önemli kriterlerin seçilmesi işlemlerinde de kullanılmaktadır. Analizin işleyişinde grup ağırlık merkezinin varyansla gelip gelmediğini kontrol etmeye yarayan ön doğrulama yapılmaktadır. Sonrasında ayrılabilir fonksiyonlar halinde gruplandırılabilecek en fazla sayıdaki ayırt edici özelliklere sahip olan öngörücü değişkenlere ulaşılır. Son olarak ise ayrılabilir fonksiyon dikkate alınarak test verileri değerlendirilmektedir. Test verileri ardından belirli bir gruba atanmaktadırlar (Chen ve Hsiao, 2008, s. 1148).
4.1.2. Lojistik Regresyon Analizi
Lojistik regresyon analizi (LRA) kümülatif lojistik olasılık fonksiyonuna dayanmaktadır (Lin ve McClean, 2001, s.193). LRA sonucunda elde edilen lojistik puanı istatistiki olasılığa dönüştürülebildiği için, pek çok araştırmada tercih edilen bir yöntemdir (Cho ve diğerleri, 2010, s.3483). LRA çok değişkenli normal öngörücü değişkenlerden ziyade kategorik değişkenleri göz önünde bulundurmaktadır. Her bir gözlem birimi için söz konusu olay hakkında bir ya da daha fazla öngörücü değişken fonksiyonu ile gerçekleşme olasılığına ilişkin tahminler sunmaktadır (Shrev ve diğerleri, 2011, s. 248). Çoğu durumda modele ikili bağımlı bir değişkenin dâhil edilmesi uygun görülür (Lin ve McClean, 2001, s. 193). LRA genellikle, ikili sınıflandırma yapılırken kullanılan bir yaklaşımdır. Model kullanırken, tepki değişkeni iki değerli ya da ikili olarak alınır. Diğer bir deyişle, y_i=0 veya bütün i=1,...,n için sonuç 1’dir. Örneğin, gözlem sürecinin sonunda başarılı (1) ya da başarısız (0) bir durumla karşılaşılmaktadır. Bazı özelliklerin ya da olayın var olduğu “1” ya da var olmadığı “0” olarak ifade edilir. Ayrıca, iki değerli değişkenler tahmin yürütmek için de kullanılabilmektedir. Örneğin, bireyin yakın gelecekte bir ürünü satın alıp almayacağı bu yöntemle öngörülmektedir (Ravisankar ve diğerleri, 2011, s. 496).
𝑦
𝑖={1,𝑒𝑣𝑒𝑡;2,ℎ𝑎𝑦𝚤𝑟, (2)
Analizde verilen bir eğitim veri seti için sınıf etiketlerinin olabilirliğini maksimize eden bir
dizi parametre {𝑤0,w}, kullanılır. 𝑥𝑖 ∈ 𝑅𝑑, i. veri noktasını temsil eden d özelliklerinin bir sütun
vektörünü ifade etmektedir. 𝑦𝑖∈{0, 1} ise buna karşılık gelen sınıf etiketini göstermektedir. Bir
veri noktası (eğitim) için y bilinmekte; diğer veri noktası için (test) 𝑦𝑖 bilinmemektedir. LR
modelinde, 𝑦𝑖=1 olabilirliği 𝑥𝑖 için 3. denklemde şöyledir (Ravisankar ve diğerleri, 2011,
𝜓𝑖≡p(𝑦𝑖=1|𝑥𝑖)= exp(𝑤0+𝑤 𝑡𝑥
𝑖)
1+exp(𝑤𝑜+𝑤𝑡𝑥𝑖) (3)
𝑤0∈R ve w∈ 𝑅𝑑 ‘nin sırasıyla lojistik regresyon kesişimi ve katsayı olduğu durumlarda N
bağımsız etiketli veri noktaları için {𝑥𝑖, 𝑦𝑖}𝑛𝑖 = 1ise, sınıf etiketlerinin olabilirliği (4). denklem
gibi yazılabilir (Ravisankar ve diğerleri, 2011, s. 496):
𝑙(𝑤𝑜, 𝑤) = ∑𝑛𝑖=1[(1 − 𝑦𝑖) log(1 − 𝜓𝑖) + 𝑦𝑖𝑙𝑜𝑔𝜓𝑖] (4)
Denklemdeki olabilirliğini maksimize etmek için, standart bir optimizasyon yaklaşımı
kullanılabilir. Çünkü, 4. denklemin {𝑤0,w}’a ilişkin gradyanı kolaylıkla hesaplanabilmektedir.
Lojistik regresyon parametreleri {𝑤0,w} öğrenildikten sonra, etiketsiz (test) bir 𝑥𝑖 veri
noktasının her bir sınıfa ait olma olabilirliği 3. denklem kullanılarak elde edilebilir (Ravisankar ve diğerleri, 2011, 496).
4.1.3. Temel Bileşen Analizi
Temel bileşen analizi’nin (TBA) odak fikri, birbiriyle ilişkili çok sayıda değişken bulunan veri setinin boyutunu azaltmaktır ve veri setinde bulunan varyasyonu mümkün olduğunca korumayı hedeflemektedir. Azaltma işleminde temel bileşenler olarak korelasyonsuz, ilk birkaç değişkeninde tüm orijinal değişkenlerde bulunan varyasyonu en üst düzeyde barındıran yeni bir değişken setine geçilmektedir. Temel bileşenlerin özdeğerleri ve özvektörlerini hesaplayarak lineerlikte en yüksek varyasyonu yaratan orijinal değişkenler kombinasyonu tespit edilmektedir (Tsai, 2009, s. 122). TBA, orijinal verinin sıkıştırılmış temsilden en az karesel hata ile yeniden oluşturulabileceği şekilde veri vektörlerinin daha küçük boyutlu lineer temsilini bulmaktadır. Aşağıdaki şekilde modellenmiş n d x1 veri
vektörlerinin 𝑦1, 𝑦2, . . . ,𝑦𝑛 olduğu varsayılır (Ilin ve Raiko, 2010, s. 1957);
yj ≈Wxj +m (5)
W bir d x c matrisidir, 𝑥𝑗 c x 1 temel bileşen vektörleridir ve m bir d x 1 çapraz
vektörüdür. c≤d≤n olduğu varsayıldığında; temel alt-uzay yöntemleri; W, 𝑥𝑗 ve m’yi yeniden
yapılandırma hatasını minimize edilecek şekilde bulur (Ilin ve Raiko, 2010, 1957-1958).
𝐶 = ∑𝑛 ‖𝑦𝑗
𝑗=1 − 𝑊𝑋𝐽− 𝑚‖ 2 (6)
Matris gösteriminde veri vektörleri ve temel bileşenler dxn ve cxn matrislerinde
toplanabilir, Y = [𝑦1, 𝑦2, . . . ,𝑦𝑛] ve X = [𝑥1, 𝑥2, . . . ,𝑦𝑥𝑛] ve 𝑦𝑖𝑗, 𝑤𝑖𝑘 ve 𝑥𝑘𝑗 sırasıyla Y,W ve
X matrislerinin elamanlarını ifade etmektedir. Çapraz matrisi M, sütun olarak çapraz vektörü
m’nin n sayıda kopyasını içerir. Temel alt-uzay yöntemleri, 𝑌 ≈ 𝑊𝑋 + 𝑀 olacak şekilde ve
minimize maliyet fonksiyonu matrisin karesi alınmış elemanlarının toplamı olmak üzere W ve X’i bulur. Geleneksel tanıma göre, W’nin sütun vektörleri karşılıklı olup birim uzunluğuna sahiptir ve her k=1,…,c için ilk k vektörleri k-boyutlu temel alt-uzayı oluşturur (Ilin ve Raiko, 2010: 1958). İlk temel bileşen, verideki mümkün olan en fazla değişkeni sağlamaktadır. İkinci temel bileşen kalan değişkenliği sağlar ve bu devam eder. Her özellik için değişkenlik düzeyi [0,1] aralığında olmaktadır. 1 özelliği en yüksek düzey değişkenliği temsil etmektedir (Tsai ve Hsiao, 2010, s. 260).
4.2. Veri Seti
Bu çalışmanın veri setinde 55 banka yer almaktadır. Bu bankalardan 21 tanesi 1997 ve 2003 yılları arasında çeşitli nedenlerde mali bünyeleri bozulup Tasarruf Mevduatı Sigorta
Fonu’na (TMSF) devredilen bankalardan oluşmaktadır. 1997 ve 1998 yılında 1’er banka, 1999 yılında 6 banka, 2000 yılında 3 banka, 2001 yılında 8 banka, 2002 ve 2003 yılında ise 1’er banka TMSF’ye devredilmiştir. Devirlerin en çok yaşandığı yıl 2001 olmuştur. Bu çalışmada banka iflasları 1 yıl öncesinden öngörüldüğü için, bankaların iflas etmeden bir yıl önceki mali bilgilerinden yararlanılmıştır. Veri setinde 34 tane faaliyetini sürdüren banka yer almaktadır. Devirlerin en çok yaşandığı yıl 2001 yılı olduğu için, faaliyetlerini devam ettiren
34 bankanın 2000 yılı mali bilgileri veri setinde yer almaktadır. Bankaların mali durumlarını
yansıtan rasyolar Türkiye Bankalar Birliği’nin resmi internet sitesinden elde edilmiştir.
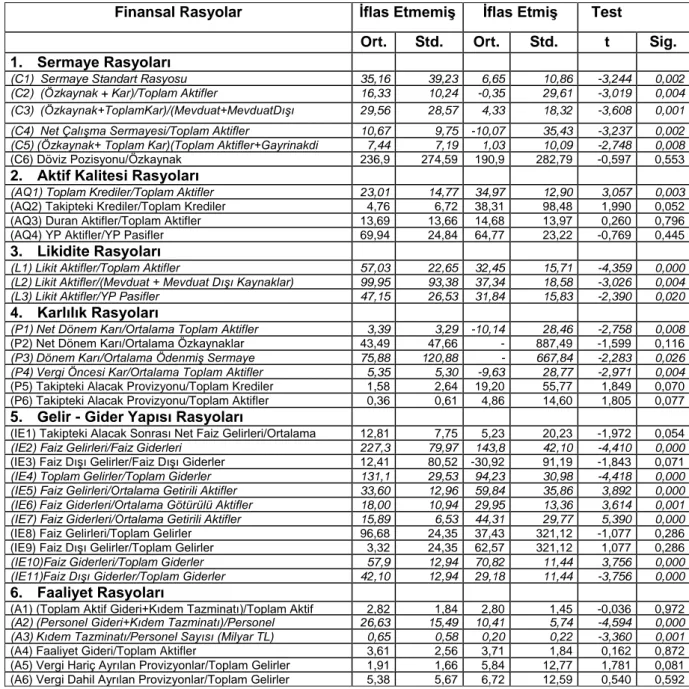
Tablo 1. Finansal Rasyolar Hakkında İstatistiksel Bilgiler
Finansal Rasyolar İflas Etmemiş İflas Etmiş Test Değerleri Ort. Std. Sap. Ort. Std. Sap. t Sig. 1. Sermaye Rasyoları
(C1) Sermaye Standart Rasyosu 35,16 39,23 6,65 10,86 -3,244 0,002
(C2) (Özkaynak + Kar)/Toplam Aktifler
(Özkaynak + Kar)/T.Aktifler
16,33 10,24 -0,35 29,61 -3,019 0,004
(C3) (Özkaynak+ToplamKar)/(Mevduat+MevduatDışı Kaynaklar)
29,56 28,57 4,33 18,32 -3,608 0,001
(C4) Net Çalışma Sermayesi/Toplam Aktifler 10,67 9,75 -10,07 35,43 -3,237 0,002
(C5) (Özkaynak+ Toplam Kar)(Toplam Aktifler+Gayrinakdi Krediler) 7,44 7,19 1,03 10,09 -2,748 0,008 (C6) Döviz Pozisyonu/Özkaynak 236,9 9 274,59 190,9 9 282,79 -0,597 0,553
2. Aktif Kalitesi Rasyoları
(AQ1) Toplam Krediler/Toplam Aktifler 23,01 14,77 34,97 12,90 3,057 0,003
(AQ2) Takipteki Krediler/Toplam Krediler 4,76 6,72 38,31 98,48 1,990 0,052
(AQ3) Duran Aktifler/Toplam Aktifler 13,69 13,66 14,68 13,97 0,260 0,796
(AQ4) YP Aktifler/YP Pasifler 69,94 24,84 64,77 23,22 -0,769 0,445
3. Likidite Rasyoları
(L1) Likit Aktifler/Toplam Aktifler 57,03 22,65 32,45 15,71 -4,359 0,000
(L2) Likit Aktifler/(Mevduat + Mevduat Dışı Kaynaklar) 99,95 93,38 37,34 18,58 -3,026 0,004
(L3) Likit Aktifler/YP Pasifler 47,15 26,53 31,84 15,83 -2,390 0,020
4. Karlılık Rasyoları
(P1) Net Dönem Karı/Ortalama Toplam Aktifler 3,39 3,29 -10,14 28,46 -2,758 0,008
(P2) Net Dönem Karı/Ortalama Özkaynaklar 43,49 47,66
-198,9 6
887,49 -1,599 0,116
(P3) Dönem Karı/Ortalama Ödenmiş Sermaye 75,88 120,88
-190,9 6
667,84 -2,283 0,026
(P4) Vergi Öncesi Kar/Ortalama Toplam Aktifler 5,35 5,30 -9,63 28,77 -2,971 0,004
(P5) Takipteki Alacak Provizyonu/Toplam Krediler 1,58 2,64 19,20 55,77 1,849 0,070 (P6) Takipteki Alacak Provizyonu/Toplam Aktifler 0,36 0,61 4,86 14,60 1,805 0,077
5. Gelir - Gider Yapısı Rasyoları
(IE1) Takipteki Alacak Sonrası Net Faiz Gelirleri/Ortalama Toplam Aktif
12,81 7,75 5,23 20,23 -1,972 0,054
(IE2) Faiz Gelirleri/Faiz Giderleri 227,3
1
79,97 143,8
4
42,10 -4,410 0,000
(IE3) Faiz Dışı Gelirler/Faiz Dışı Giderler 12,41 80,52 -30,92 91,19 -1,843 0,071
(IE4) Toplam Gelirler/Toplam Giderler 131,1
3
29,53 94,23 30,98 -4,418 0,000
(IE5) Faiz Gelirleri/Ortalama Getirili Aktifler 33,60 12,96 59,84 35,86 3,892 0,000
(IE6) Faiz Giderleri/Ortalama Götürülü Aktifler 18,00 10,94 29,95 13,36 3,614 0,001
(IE7) Faiz Giderleri/Ortalama Getirili Aktifler 15,89 6,53 44,31 29,77 5,390 0,000
(IE8) Faiz Gelirleri/Toplam Gelirler 96,68 24,35 37,43 321,12 -1,077 0,286
(IE9) Faiz Dışı Gelirler/Toplam Gelirler 3,32 24,35 62,57 321,12 1,077 0,286
(IE10)Faiz Giderleri/Toplam Giderler 57,9 12,94 70,82 11,44 3,756 0,000
(IE11)Faiz Dışı Giderler/Toplam Giderler 42,10 12,94 29,18 11,44 -3,756 0,000
6. Faaliyet Rasyoları
(A1) (Toplam Aktif Gideri+Kıdem Tazminatı)/Toplam Aktif 2,82 1,84 2,80 1,45 -0,036 0,972
(A2) (Personel Gideri+Kıdem Tazminatı)/Personel Sayısı(MilyarTL)
26,63 15,49 10,41 5,74 -4,594 0,000
(A3) Kıdem Tazminatı/Personel Sayısı (Milyar TL) 0,65 0,58 0,20 0,22 -3,360 0,001
(A4) Faaliyet Gideri/Toplam Aktifler 3,61 2,56 3,71 1,84 0,162 0,872
(A5) Vergi Hariç Ayrılan Provizyonlar/Toplam Gelirler 1,91 1,66 5,84 12,77 1,781 0,081 (A6) Vergi Dahil Ayrılan Provizyonlar/Toplam Gelirler 5,38 5,67 6,72 12,59 0,540 0,592 Tablo 1’de, sermaye rasyoları, aktif kalitesi, likidite, karlılık, gelir–gider yapısı ve faaliyet rasyoları olmak üzere 6 başlık altında bulunan 36 finansal rasyo çalışmanın bağımsız değişkenlerini oluşturmaktadır. Çalışmanın bağımlı değişkeni ise bankaların iflas edip etmediklerine ilişkin olarak kullanılan 0 ve 1 değerleridir. İflas eden ve faaliyetlerine devam eden bankaların finansal rasyoları arasındaki farklılık t testi ile araştırılmıştır. Buna göre 36 finansal rasyodan 21’i arasındaki farklılık yüzde 5 düzeyinde anlamlı bulunmuş ve Tablo 1’de
bu rasyolar italik olarak belirtilmiştir. İflas eden ve faaliyetlerine devam eden bankaların finansal rasyoları başlıklar halinde incelendiğinde; 6 sermaye rasyosundan 5’i, 4 aktif kalitesi rasyosundan 1’i, likidite rasyolarının tamamı, 6 karlılık rasyosundan 3’ü, 11 gelir – gider yapısı rasyosundan 7’si ve 6 faaliyet rasyosundan 2’si arasındaki farklılık istatistiki olarak anlamlı bulunmuştur. T testinden elde edilen bulgular doğrultusunda iflas sürecinde bankaların, özellikle likitide ve sermaye yapısı rasyolarının kötüleştiği belirtilebilir. YSA ile modelleme yapabilmek için veriler eğitim ve test seti olarak ikiye ayrılmıştır. Veriler rastgele olarak yüzde 60’ı eğitim setine yüzde 40’ı da test setine alınmıştır. Eğitim setinde 13 adet iflas eden ve 20 adet faaliyetini devam ettiren banka bulunurken, test setinde 8 adet iflas eden ve 14 adet faaliyetini sürdüren banka bulunmaktadır.
Bu çalışmada iflas eden ve faaliyetlerini sürdüren bankaları birbirinden en iyi şekilde ayıran finansal rasyoların tespitinde; DA, LRA ve TBA veri indirgeme yöntemleri olarak kullanılmıştır. Şekil 2’de gösterildiği üzere bu yöntemler yardımıyla önemli finansal rasyolar belirlenmiş böylece 3 farklı veri seti elde edilmiş sonrasında her bir veri seti için YSA modelleri geliştirilmiş; son olarak da doğru sınıflandırma oranları elde edilmiştir.
Piramuthu (1999), Vellido vd. (1999), Yıldız (2009) gibi çalışmalara bakıldığında; sınıflandırma problemlerin çoğunda “ileri beslemeli çok katmanlı algılayıcı”, işletme uygulamalarında öğrenme algoritması olarak da en çok “geri yayılım algoritması” kullanılmaktadır. Bu açıdan çalışmada tercih edilmişlerdir. Cybenko (1989), Hornik vd. (1989) ve Zhang vd., (1998) gibi araştırmacılar bir çok karmaşık sistem için “tek bir gizli katmanın” yeterli olduğunu belirtmelerinden dolayı geliştirilen YSA modellerinde gizli katman sayısı 1
olarak belirlenmiştir.Eğitim uzunluğu 1.000 devirle sınırlı tutulmuştur. Öğrenme oranı olarak
0,001 - 0,005 - 0,01 - 0,05 - 0,1 - 0,2 - 0,3 ve 0,4 olmak üzere 8 farklı değer kullanılmıştır. Momentum için 0,5 - 0,7 ve 0,9 değerleri kullanılmıştır. Gizli katmandaki düğüm sayısı ise 1/3n, n ve 2n olarak belirlenmiştir. Böylece her bir veri kümesi için 72 YSA modeli geliştirilmiştir.
Şekil 2: Deneysel Süreç
4.3. Bulgular
Değişken seçiminde kullanılan DA sonucunda 5 değişken seçilmiştir. Başka bir ifade ile
diskriminant analizi iflas eden ve faaliyetlerini sürdüren bankaları birbirinden en yüksek
doğrulukla ayıran 5 finansal rasyo tespit etmiştir. Bu değişkenler (AQ1) Toplam Krediler/Toplam Aktifler, (AQ3) Duran Aktifler/Toplam Aktifler, (L1) Likit Aktifler/Toplam
Aktifler, (IE4) Toplam Gelirler/ Toplam Giderler, (A2) (Personel Gideri+Kıdem Tazminatı) /
Personel Sayısı (Milyar TL)’dir. Söz konusu 5 finansal rasyo ile geliştirilen YSA modellerinin Orijinal Veri Seri
Veri İndirgeme Aşaması
Diskriminant Analizi Temel Bileşenler Analizi Lojistik Regresyon Analizi YSA Modelleri Değerlendirme Aşaması Doğru Sınıflandırma Oranı
sonuçları Tablo 2’de yer almaktadır. 5 değişken ile geliştirilen 72 YSA modeli ortalamada bankaların finansal durumlarını yüzde 92,74 oranında doğrulukla öngörmüştür.
Tablo 2: DA Tarafından Belirlenen Değişkenlerle YSA Modeli Banka İflas Öngörüsü
Öğrenme Oranı
Momentum Katsayısı
0,5 0,7 0,9
Düğüm Sayısı Düğüm Sayısı Düğüm Sayısı
2 5 10 2 5 10 2 5 10 0,001 72,73 72,73 90,91 72,73 72,73 90,91 77,27 86,36 90,91 0,005 77,27 86,36 90,91 77,27 90,91 90,91 95,45 95,45 90,91 0,01 81,82 95,45 90,91 90,91 95,45 90,91 95,45 95,45 90,91 0,05 95,45 95,45 90,91 100 95,45 95,45 100 95,45 95,45 0,1 100 95,45 95,45 100 95,45 95,45 100 90,91 95,45 0,2 100 95,45 95,45 100 90,91 100 95,45 95,45 95,45 0,3 100 90,91 100 100 90,91 95,45 95,45 95,45 95,45 0,4 100 90,91 100 100 90,91 95,45 95,45 95,45 95,45
LRA sonucunda 3 değişken seçilmiştir. Bu değişkenler (AQ1) Toplam Krediler/Toplam Aktifler, (IE7) Faiz Giderleri / Ortalama Getirili Aktifler ve (A6) Vergi Dahil Ayrılan Provizyonlar / Toplam Gelirler rasyolarıdır. LRA tarafından belirlenen 3 finansal rasyo kullanılarak geliştirilen YSA modellerine ilişkin sonuçlar Tablo 2’de yer almaktadır. Aynı şekilde geliştirilen modellerden elde edilen en düşük öngörü oranı yüzde 72,73 olurken en yüksek öngörü oranı ise yüzde 100 olarak bulunmuştur. Ancak LRA tarafından tespit edilen değişkenler ile kurulan modellerin ortalama öngörü oranı yüzde 94,38’dir. Bu oran DA tarafından belirlenen finansal rasyolar ile geliştirilen modellerin ortalama doğru öngörü oranından daha yüksektir. Dolayısıyla iflas tahmini değişken seçiminde LRA’nin DA’nden daha başarılı olduğu belirtilebilir.
Tablo 3: LRA Tarafından Belirlenen Değişkenlerle YSA Modeli Banka İflas Öngörüsü
Öğrenme Oranı
Momentum Katsayısı
0,5 0,7 0,9
Düğüm Sayısı Düğüm Sayısı Düğüm Sayısı
1 3 6 1 3 6 1 3 6 0,001 81,82 90,91 90,91 90,91 72,73 90,91 90,91 86,36 90,91 0,005 90,91 86,36 90,91 90,91 86,36 90,91 90,91 90,91 95,45 0,01 90,91 86,36 90,91 90,91 90,91 95,45 95,45 95,45 95,45 0,05 95,45 95,45 95,45 90,91 90,91 95,45 95,45 90,91 95,45 0,1 90,91 90,91 95,45 90,91 90,91 95,45 100 100 100 0,2 95,45 90,91 95,45 100 95,45 100 100 100 100 0,3 95,45 95,45 100 100 100 100 100 100 100 0,4 100 95,45 100 100 100 100 100 100 100
Orijinal veri setinde yer alan 36 finansal rasyo TBA’ya tabi tutulduğunda bu rasyolar 7 faktör altında toplanmışlardır. Söz konusu 7 faktör ile geliştirilen YSA modellerinin sonuçları Tablo 4’de yer almaktadır. 7 faktör ile geliştirilen YSA modellerinin en düşük doğru sınıflandırma oranı yüzde 86,36 olarak bulunurken en yüksek doğru sınıflandırma oranı yüzde 90,91’dir. Veri indirgeme yöntemi olarak TBA’nın kullanıldığı YSA modellerinin doğru sınıflandırma oranı yüzde 88,26 olarak bulunmuştur.
Tablo 4: TBA Tarafından Belirlenen Değişkenlerle YSA Modeli Banka İflas Öngörüsü
Öğrenme Oranı
Momentum Katsayısı
0,5 0,7 0,9
Düğüm Sayısı Düğüm Sayısı Düğüm Sayısı
2 7 14 2 7 14 2 7 14 0,001 90,91 86,36 86,36 90,91 86,36 86,36 90,91 86,36 86,36 0,005 90,91 86,36 86,36 90,91 90,91 90,91 90,91 90,91 90,91 0,01 90,91 90,91 90,91 90,91 90,91 90,91 90,91 90,91 90,91 0,05 90,91 90,91 90,91 90,91 86,36 90,91 90,91 86,36 86,36 0,1 90,91 86,36 90,91 90,91 86,36 86,36 86,36 86,36 86,36 0,2 90,91 86,36 86,36 86,36 86,36 86,36 86,36 86,36 86,36 0,3 90,91 86,36 86,36 86,36 86,36 86,36 86,36 86,36 86,36 0,4 86,36 86,36 86,36 86,36 86,36 86,36 86,36 86,36 86,36
Tablo 5: Veri İndirgeme Yöntemlerinden Elde edilen Değişkenlerle Geliştirilen YSA Modellerinin Performanslarının Karşılaştırılması
Doğru Sınıflandırma Oranı
Veri İndirgeme Yöntemi Ortalama En Düşük En Yüksek
DA %92,74 %72,73 %100
LRA %94,38 %72,73 %100
TBA %88,26 %86,36 %90,91
Tablo 5 incelendiğinde en başarılı veri indirgeme yönteminin LRA olduğu söylenebilir.
Tablo 6’da ise 3 veri indirgeme yönteminin sonuçları bir araya getirilmiştir. Böylece YSA ile iflas öngörüsünde en yüksek doğru sınıflandırmayı veren öğrenme oranı, momentum katsayısı ve düğüm sayıları tespit edilmeye çalışılmıştır. Buna göre en başarılı öğrenme oranları 0,3 ve 0,4 olarak bulunmuştur. Bu öğrenme oranlarının ortalama doğru sınıflandırma oranı yüzde 93,94’dür. En başarılı momentum katsayısı ise 0,9 olarak bulunmuştur. Bu oran kullanılarak kurulan modellerin ortalama doğru sınıflandırma oranı yüzde 92,74’dür. Ortalama doğru sınıflandırma oranı en iyi olan gizli katmandaki düğüm sayısı ise 2n olarak bulunmuştur. Başka bir ifade ile bağımsız değişken sayısının 2 katı kadar düğüm atanması ile oluşturulan modellerin ortalama doğru sınıflandırma oranı yüzde 92,68’dür. YSA ile geliştirilen bütün modellerin ortalama doğu sınıflandırma oranı yüzde 91,79’dur. Dolayısıyla YSA modellerinin banka iflaslarının yüksek doğrulukla öngörebildiği belirtilebilir.
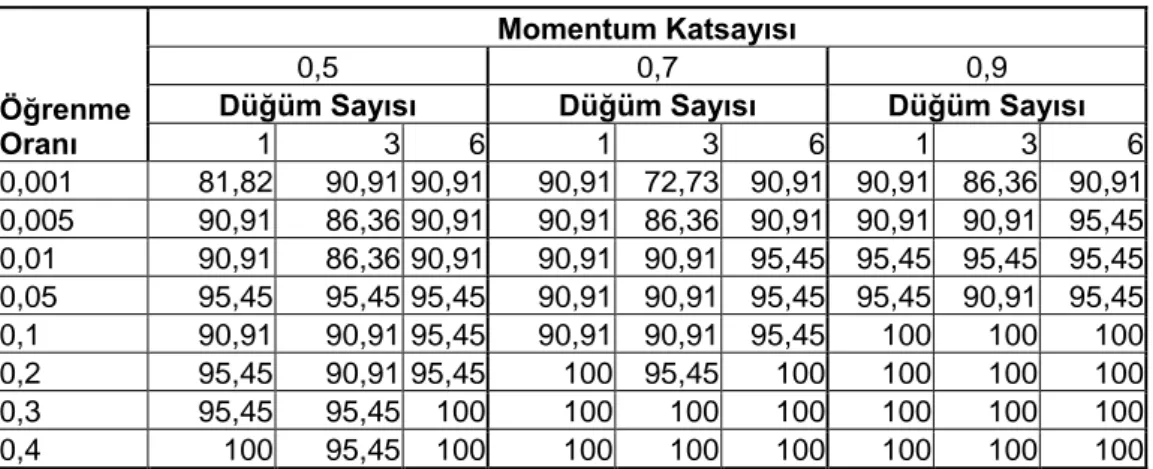
Tablo 6: Öğrenme Oranı, Momentum Katsayısı ve Düğüm Sayısının YSA Modelinin Ortalama Öngörü Başarısına Etkisi
Öğrenme Oranı
Momentum Katsayısı
0,5 0,7 0,9
Düğüm Sayısı Düğüm Sayısı Düğüm Sayısı
n1/3 n 2n n1/3 n 2n n1/3 n 2n 0,001 81,82 83,33 89,39 84,85 77,27 89,39 86,36 86,36 89,39 0,005 86,36 86,36 89,39 86,36 89,39 90,91 92,42 92,42 92,42 0,01 87,88 90,91 90,91 90,91 92,42 92,42 93,94 93,94 92,42 0,05 93,94 93,94 92,42 93,94 90,91 93,94 95,45 90,91 92,42 0,1 93,94 90,91 93,94 93,94 90,91 92,42 95,45 92,42 93,94 0,2 95,45 90,91 92,42 95,45 90,91 95,45 93,94 93,94 93,94 0,3 95,45 90,91 95,45 95,45 92,42 93,94 93,94 93,94 93,94 0,4 95,45 90,91 95,45 95,45 92,42 93,94 93,94 93,94 93,94
Bu çalışmanın veri indirgeme aşamasında DA, LRA ve TBA olmak üzere üç yöntem kullanılmıştır. TBA tüm değişkenleri kullanarak bir dönüşüm yaptığı için bize hangi rasyoların daha önemli olduğuna dair bir bilgi sunmamaktadır. Ancak DA ve LRA bu imkana sahiptir. DA bankaların sınıflandırılmasında aktif kalitesi rasyo grubundan 2 tane, likidite, gelir – gider yapısı ve faaliyet rasyoları gruplarından 1’er tane olmak üzere 5 finansal rasyoyu önemli bulmuştur. LRA ise aktif kalitesi, gelir – gider yapısı ve faaliyet rasyoları gruplarından 1’er tane olmak üzere 3 finansal rasyoyu önemli bulmuştur. Aktif kalitesi rasyo grubu altında yer alan Toplam Krediler / Toplam Aktifler rasyosu her iki yöntem tarafından da önemli bulunan tek rasyodur. Söz konusu süreçte kredilerin aktiflere oranının yüksekliğinin, bankaların iflas sürecine büyük miktarda etkide bulunduğu belirtilebilir. Veri setinde faaliyetlerini sürdüren bankaların için bu rasyo yaklaşık olarak yüzde 23 iken iflas eden bankalar için yüzde 35’dir. İlgili dönemde bankaların kredilerden ziyade menkul kıymetlere özellikle de devletin borçlanma senetlerine yatırım yaptığı bilinmektedir. Kredilerin aktife oranı için yüzde 30’lu rakamların, özellikle 2010’lı yıllar ile kıyaslandığında, çok da yüksek olmadığı söylenebilir. Ancak kredilerin aktife oranının yüksekliğinin yanında, takipteki kredilerin 2001 krizinde oldukça yükseldiği dolayısıyla bu durumun bankaların iflasında önemli bir rolünün olduğu belirtilebilir. Diğer taraftan faiz giderlerinin aktife oranının yüksekliği, likidite oranlarındaki ve toplam gelirin toplam gidere oranındaki düşüklük aynı zamanda beklenenin aksine personel başına düşük giderin, ilgili süreçte iflas eden bankaların belirgin özellikleri olduğu ifade edilebilir.
5. Sonuç ve Öneriler
Yapay zeka teknolojilerinden biri olan yapay sinir ağları, iflas öngörüsünde 1990’lı
yıllardan bu yana kullanılmakta ve yüksek öngörü performansı ile dikkatleri çekmektedir. Bu çalışmada 1997-2003 yılları arasında Tasarruf Mevduatı Sigorta Fonu’na devredilen bankaların öngörüsü yapay sinir ağı modelleri ile öngörülmüştür. Önceki çalışmalardan farklı olarak bu çalışmada diskriminant analizi, lojistik regresyon analizi ve temel bileşenler analizi veri indirgeme yöntemi olarak kullanılmış ve hangisinin bu alanda daha iyi bir yöntem olduğu araştırılmıştır. Çalışmada banka iflas öngörüsünün yapılması ile birlikte değişken seçiminin yapılması çalışmanın özgünlüğünü oluşturmaktadır. Değişkenlerin doğru tespit edilmesi öngörüde zaman ve maliyeti düşürürken, etkin bir öngörüde bulunmayı sağlayacaktır. Yapay
sinir ağı modelleri kurulurken, bu alanda bir teorinin bulunmamasından dolayı, öğrenme
oranı, momentum katsayısı ve gizli katmandaki düğüm sayısı gibi parametreler için en uygun değerlerin belirlenmesi, genellikle deneme yanılma yolu ile gerçekleştirilmektedir. Bu durum oldukça zaman almaktadır. Bu çalışmada söz konusu parametreler için iflas öngörüsünde en uygun değerler de araştırılmıştır.
Yapay sinir ağı modellerinden yüzde 73,72- yüzde 100 arasından değişen, ortalamada
ise yüzde 91,79 oranında doğru sınıflandırma başarısı elde edilmiştir. Dolayısıyla önceki
çalışmalara paralel olarak yapay sinir ağı modellerinin iflas öngörüsünde oldukça başarılı olduğu belirtilmelidir. Veri indirgeme yöntemi olarak kullanılan diskriminant analizi, lojistik
regresyon analizi ve temel bileşenler analizinin ortalama doğru öngörü başarısı sırasıyla
yüzde 92,74; yüzde 94,38 ve yüzde 88,26 olarak bulunmuştur. Dolayısıyla lojistik regresyon
analizinin iflas öngörüsünde en başarılı veri indirgeme yöntemi olduğu belirtilebilir. Lojistik
regresyon analizi tarafından belirlenen değişkenler Toplam Krediler/Toplam Aktifler, Faiz
Giderleri/Ortalama Karlı Aktifler ve Vergi Dahil Ayrılan Provizyonlar/Toplam Gelirler rasyolarıdır. Bu değişkenlerin iflas eden ve faaliyetlerini sürdüren bankaları sınıflandırmada en önemli finansal rasyolar olduğu söylenebilir. Bu değişkenler Türk bankalarının iflas öngörüsünde uyarı sinyalleri olarak nitelendirilebilir. Türk bankaları gelecekte bu değişkenlerin izlenmesi ve yorumlanması ile başarısızlıklarını değerlendirebilirler. Çalışmadan elde edilen bir diğer sonuç ise, yapay sinir ağı modelleri kurulurken belirlenmesi gereken parametrelerden olan öğrenme oranı için en iyi değerler 0,3 ve 0,4; momentum katsayısı için en iyi değer 0,9 bulunmuştur. Gizli katmandaki düğüm sayısı için en iyi değer
bağımsız değişken sayısının 2 katı olarak tespit edilmiştir. Bundan sonraki çalışmalarda korelasyon matrisleri, t testi, wilks lambda, olabilirlik ölçütü gibi teknikler veri indirgeme yöntemi olarak kullanılabilir. Farklı iflas verileri ile modeller geliştirilebilir. Destek vektör makineleri, genetik algoritmalar, uyarlanabilir sinirsel bulanık çıkarım sistemi gibi farklı yapay zeka teknolojileri ile modeller geliştirilebilir.
Kaynakça
Acar Boyacıoğlu, M., Kara, Y. (2007). Türk Bankacılık Sektöründe Finansal Güç Derecelerinin Tahmininde Yapay Sinir Ağları ve Çok Değişkenli İstatistiksel Analiz Tekniklerinin Performanslarının Karşılaştırılması. Dokuz Eylül Üniversitesi İktisadi ve İdari Bilimler Fakültesi Dergisi, 22(2), 197-217.
Acar, Boyacıoglu, M., Kara, Y. and Baykan, Ö.K. (2009). Predicting Bank Financial Failures Using Neural Networks, Support Vector Machines and Multivariate Statistical Methods: A Comparative Analysis in the Sample of Savings Deposit Insurance Fund (SDIF) Transferred Banks in Turkey. Expert Systems with Applications, 36(2), 3355-3366.
Andres, J.De., Landajo, M. and Lorca, P. (2012). Bankruptcy Prediction Models Based on Multinorm Analysis: An Alternative to Accounting Ratios. Knowledge-Based Systems, 30, 67-77.
Ashooria, S., Mohammadi, S. (2011). Compare Failure Prediction Models Based on Feature Selection Technique: Empirical Case from Iran. Procedia Computer Science, 3, 568–573.
Bramhandkar, A. J. (1989). Discriminant Analysis: Applications In Finance. Journal of Applied Business Research, 5(2), 37-41.
Canbas, S., Cabuk, A. and Kilic, S.B. (2005). Prediction of Commercial Bank Failure Via Multivariate Statistical Analysis of Financial Structures: The Turkish Case. European Journal of Operational Research, 166(2), 528-546.
Chauhan, N., Ravi, V. and Chandra, D.K. (2009). Differential Evolution Trained Wavelet Neural Networks: Application to Bankruptcy Prediction in Banks. Expert Systems with Applications, 36(4). 7659-7665.
Chen, L.H., Hsiao, H.D. (2008). Feature Selection to Diagnose a Business Crisis by Using a Real GA-Based Support Vector Machine: An Empirical Study, Expert Systems with Applications, 35(3), 1145–1155.
Chen, H.L., Yang, B., Wang, G., Liu, J., X.X., Wang, S.J., and Liu, D.Y. (2011). A Novel Bankruptcy Prediction Model Based on an Adaptive Fuzzy K-Nearest Neighbor Method. Knowledge-Based Systems, 24(8), 1348-1359.
Cho, S., Hong, H. and Ha., B.C. (2010). A Hybrid Approach Based on the Combination of Variable Selection Using Decision Trees and Case-Based Reasoning Using the Mahalanobis Distance: For Bankruptcy Prediction. Expert Systems with Applications, 37(4), 3482-3488.
Cielen, A., Peeters, L., Vanhoof, K. (2004). Bankruptcy Prediction Using a Data Envelopment Analysis. European Journal of Operational Research, 154, 526–532.
Cybenko, G. (1989). Approximation by Superpositions of a Sigmoidal Function. Mathematical Control Signals Systems, 2(4), 303–314.
Demyanyk, Y., Hasan I. (2010). Financial Crises and Bank Failures: A Review of Prediction Methods. Omega, 38(5), 315-324.
Hornik, K., Stinchcombe, M. and White, H. (1989). Multilayer Feedforward Networks are Universal Approximators. Neural Networks, 2(5), 359–366.
Ilin, A., Raiko, T. (2010). Practical Approaches to Principal Component Analysis in the Presence of Missing Values. Journal of Machine Learning Research, 11, 1957-2000.
Keskin Benli, Y. (2005). Bankalarda Mali Başarısızlığın Öngörülmesi Lojistik Regresyon ve Yapay Sinir Ağı Karşılaştırması. Gazi Üniversitesi Endüstriyel Sanatlar Eğitim Fakültesi Dergisi, 16, 31-46. Lin, F.Y., McClean, S. (2001). A Data Mining Apprach to the Prediction of Corporate Failure.
Knowlwdge-Based Systems, 14, 189-195.
Lin, S. W., Shiue, Y. R. , Chen, S. C., Cheng, H. M.(2009). Applying Enhanced Data Mining Approaches in Predicting Bank performance: A Case of Taiwanese Commercial Banks. Expert Systems with Applications,36, 11543–11551.
Lin, F., Liang, D. and Chen, E. (2011). Financial Ratio Selection for Business Crisis Prediction. Expert Systems with Applications, 38(12), 15094-15102.
Olson, D.L., Delen, D. and Meng, Y. (2012). Comparative Analysis of Data Mining Methods for Bankruptcy Prediction, Decision Support Systems, 52(2), 464-473.
Onan, A. (2015). Şirket İflaslarının Tahminlenmesinde Karar Ağacı Algoritmalarının Karşılaştırmalı Başarım Analizi. Bilişim Teknolojileri Dergisi, 8(1), 9-19.
Piramuthu, S. (1999). Financial Credit-Risk Evaluation with Neural and Neuro Fuzzy Systems. European Journal of Operational Research, 112(2), 310–321.
Ravisankar,P., Ravi, V. (2010). Financial Distress Prediction in Banks Using Group Method of Data Handling Neural Network, Counter Propagation Neural Network and Fuzzy ARTMAP. Knowledge-Based Systems, 23, 823-831.
Ravisankar, P., Ravi, V., Raghava Rao G., Bose, I. (2011). Detection of Financial Statement Fraud and Feature Selection Using Data Mining Techniques. Decision Support Systems, 50, 491–500. Sanchez-Lasheras, F., Andresb, J.De., Lorca, P. and Cos Juezc, F. J.De. (2012). A Hybrid Device for
the Solution of Sampling Bias Problems in the Forecasting of Firms’ Bankruptcy. Expert Systems with Applications, 39(8). 7512-7523.
Shreve, J., Schneider, H. and Soysal, O. (2011). A Methodology for Comparing Classification Methods Through the Assessment of Model Stability and Validity in Variable Selection. Decision Support Systems, 52(1), 247–257.
Tsai, C.F. (2009). Feature Selection in Bankruptcy Prediction. Knowledge-Based Systems, 22(2), 120-127.
Tsai, C.F., Hsiao, Y.C. (2010). Combining Multiple Feature Selection Methods for Stock Prediction: Union, Intersection, and Multi-Intersection Approaches, Decision Support Systems, 50(1), 258– 269.
Tseng, F.M., Lin, L. (2005). A Quadratic Interval Logit Model for Forecasting Bankruptcy. Omega, 33(1), 85-91.
Tseng, F.M., Hu, Y.C. (2010). Comparing Four Bankruptcy Prediction Models: Logit, Guadratic Interval Logit. Expert Systems with Applications, 37(3), 1846–1853.
Vellido, A., Lisboa, P.J.G., Vaughan, J. (1999). Neura Networks in Business: A Survey of Applications (1992–1998). Expert Systems with Applications, 17(1), 51–70.
Vuran, B. (2009), Prediction of Business Failure: a Comparison of Discriminant and Logistic Regression Analyses. Istanbul University Journal of the School of Business Administration, 38 (1), 47-65.
Wang, G., Ma, J. and Yang, S. (2014). An Improved Boosting Based on Feature Selection for Corporate Bankruptcy Prediction. Expert Systems with Applications, 41(5), 2353-2361.
Yıldız, B. (2009). Finansal Analizde Yapay Zeka. Ankara: Detay Yayıncılık.
Yıldız, B., Akkoç S. (2009). Banka Finansal Başarısızlıklarının Sinirsel Bulanık Ağ Yöntemi ile Öngörüsü. BDDK Bankacılık ve Finansal Piyasalar, 3(1), 9-36.
Zhang, G., Patuwo, B.E., Hu, M.Y. (1998). Forecasting with Artificial Neural Networks: the State of the Art. International Journal of Forecasting, 14(1), 35–62.