A Machine Translation System for Turkish-Turkmen Chat
Tam metin
Şekil
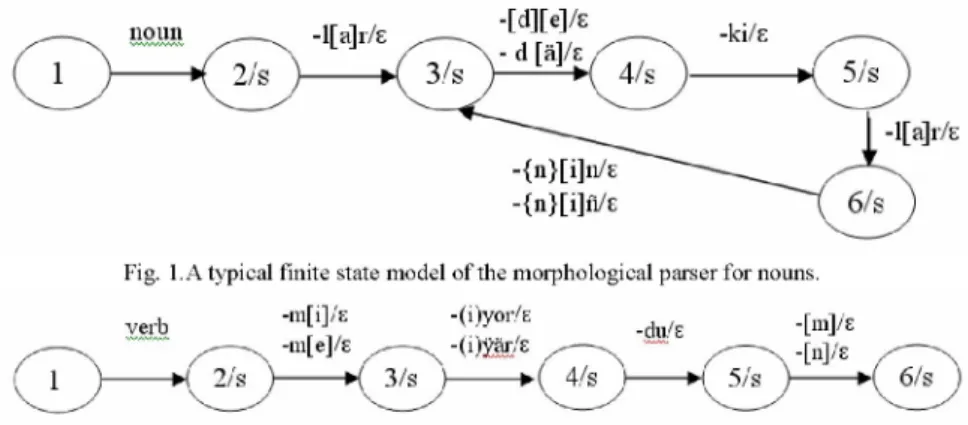
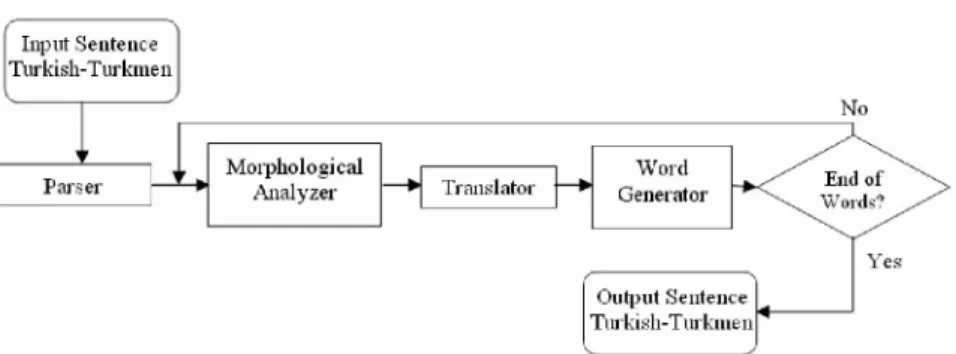


Benzer Belgeler
We reordered English phrases in order to get monotonic phrase alignments and so monotonic morpheme alignments and in- troduced two different levels of language models: a
Transfer-based approaches have been successful at expressing the structural differences between the source and target languages, while statistical approaches have been useful
To find such groups of morphemes and functional words, we applied a sequence of morpheme groupings by extracting fre- quently occuring n-grams of morphemes as follows (much like
Furthermore, the Iranian students with favourable beliefs about the role of translation tended to report using translation strategies for acquisition
It can be concluded that the translator should be very careful while selecting from the translation ecology and translating the culinary culture as he has considerable potential
If the method of explicitation is not properly applied or not applied where necessary, this leads to a translation error called under-translation (Delisle, 2013: 214), which can
disciplines as well 7 , but as Derrida says, the information travelling through disciplines represents something very much different to scholars on the receiving side.
Finally, research showed that the translation knowledge sub-competence and decision- making ability were not related whereas coherence and decision-making ability were
