Infinite level-dependent QBD processes and matrix-analytic solutions for stochastic chemical kinetics
Tam metin
Şekil


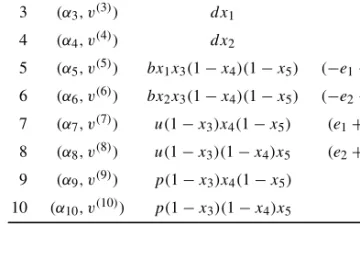
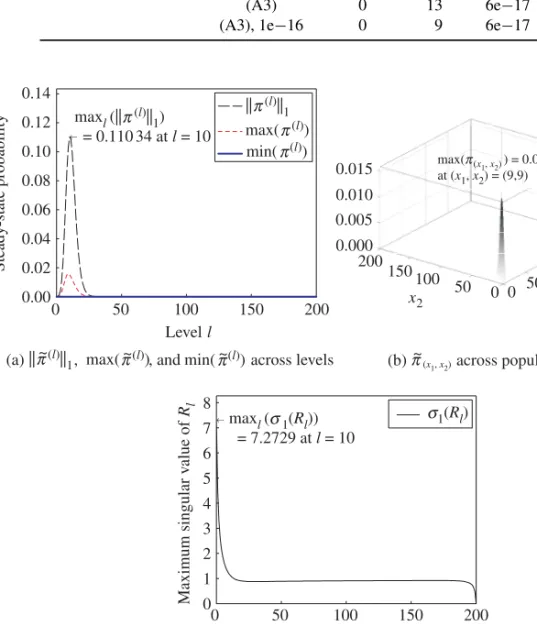
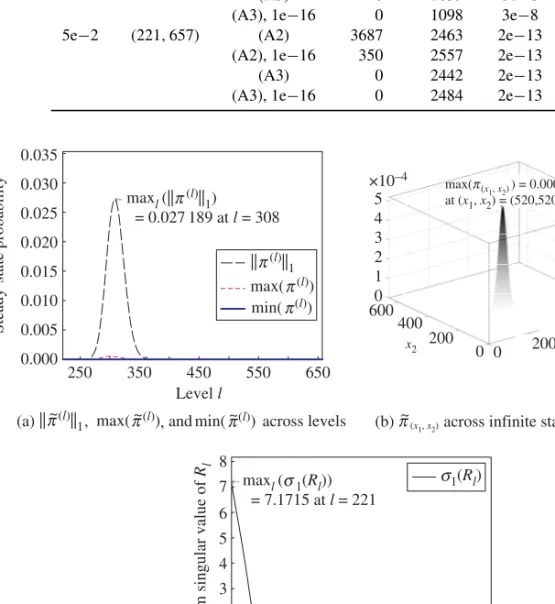
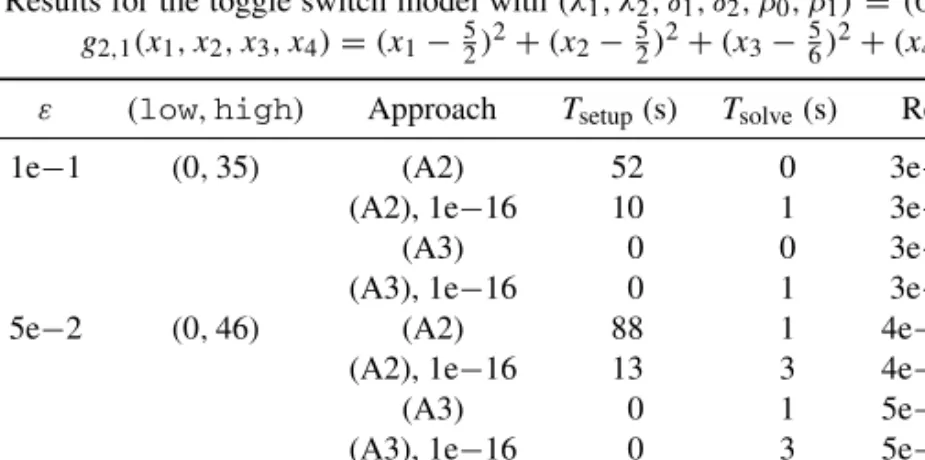

Benzer Belgeler
Spektroskopi Tabanlı Yöntemlerin Karşılaştırılmasına İlişkin Bir İnceleme | 53 FT-IR spektroskopi tekniği ile farklı kimyasal yapılara sahip patlayıcı
Çok önemli bir not daha, İstanbul için söz konusu cazibenin yeni ekonomik koşullar eşliğinde ülkedeki tüm kalkınma bölgeleri için var edilme imkânı.. İstan- bul kadar
DFOT tarafından ölçülen rezervuar su sıcaklığı ve baraj iç sıcaklığının karşılaştırılmasından sonra Şekil 27 ve 28’ de gösterildiği gibi baraj
Gelgelelim, Anday’›n ilk kez 1984 y›l›nda yay›mlanm›fl Tan›d›k Dünya adl› kitab›nda yer alan “Karacao¤lan’›n Bir fiiiri Üzerine
Such an approach precludes the mea- surement of the network within each organization as complete or near complete participation rates are needed ( Wasserman and Faust, 1994 ). We
The ranking methods used are RIMARC (Ranking Instances by Maximizing the Area under the ROC Curve), SVM light (Support Vector Machine Ranking Algorithm) and RIk NN (Ranking
Regarding remuneration during industrial training, interns were provided meals (46 percent), salary (19 percent), transportation (8 percent), medical services (8 percent), insurance
t is the inflation rate, w ÿ pt ÿ 1 is the lag value of the real wage, et is the conditional mean of the inflation, ht is the conditional variance of the inflation, Rt is the
