Başlık: An ensemble model for collaborative filtering to involve all aspects of datasetYazar(lar):AR, YılmazCilt: 60 Sayı: 2 Sayfa: 015-026 DOI: 10.1501/commua1-2_0000000112 Yayın Tarihi: 2018 PDF
Tam metin
Şekil
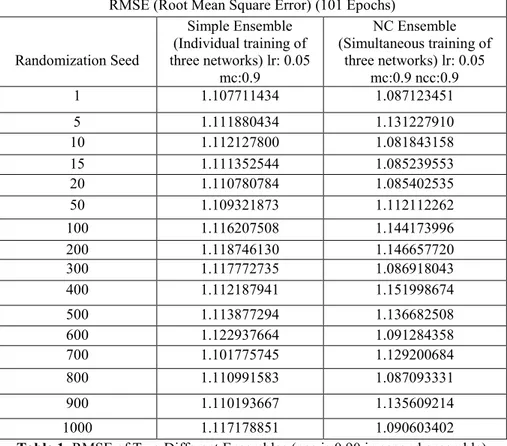
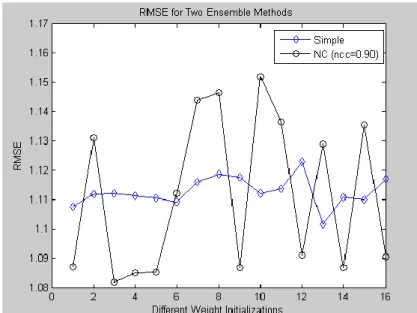
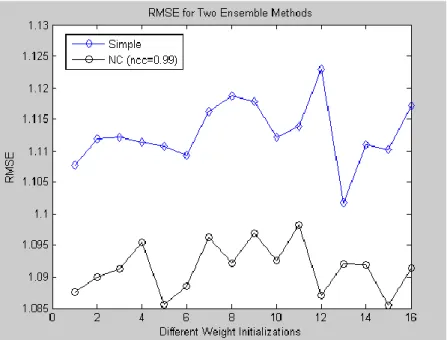
Benzer Belgeler
Verimlilik ölçümü çıktı/girdi yaklaşımına dayandığından ve girdi yönelimli bir modelde amaç, belli bir çıktıyı minimum girdiyle elde etmek olduğu için
Consistently, neurological recovery as assessed by the corner turn and the tight rope test was enhanced in mice treated with ADMSC-EVs NC when compared to both controls and mice
During the last centuries of the Ottoman state, the imperial elite initiated the process of Westernization and adopted their state's formal integration with the European state
Ideally, a warm-start strategy should use a relatively advanced iterate of the un- perturbed problem to compute a successful warm-start especially for smaller pertur- bations and
Son olarak “vâv” ( و ) harfinin - fetha harekede olduğu gibi- kesralıyken de dudakların öne doğru arada boşluk kalacak şekilde uzatılıp geri çekilmesi
In order to obtain an output presented in staff notation from audio recordings the following steps are applied: f0 estimation, automatic makam and tonic detection, segmentation
İnci Enginün'ün “Loti'nin Türklere Bakışı ve Edebiyatçılarımızın Yorumlan ”nı, Zeynep Mennan'ın “Bazı Türk Yazarlanna Göre Oryantalizm Bağlamında Pierre L
Üstâdın etrafını saran bu toplu, luk kendisine sorular yağdırıyor, o da gayet rahatlıkla hepsini karşılı yor ve bu arada çok ilginç konula.. rikatürler
