Başlık: EDGEWORTH SERIES APPROXIMATION FOR CHI-SQUARE TYPE CHANCE CONSTRAINTS Yazar(lar):YILMAZ, MehmetCilt: 56 Sayı: 2 DOI: 10.1501/Commua1_0000000191 Yayın Tarihi: 2007 PDF
Tam metin
Şekil
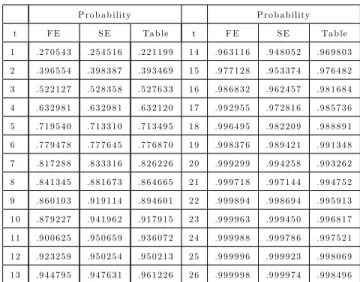
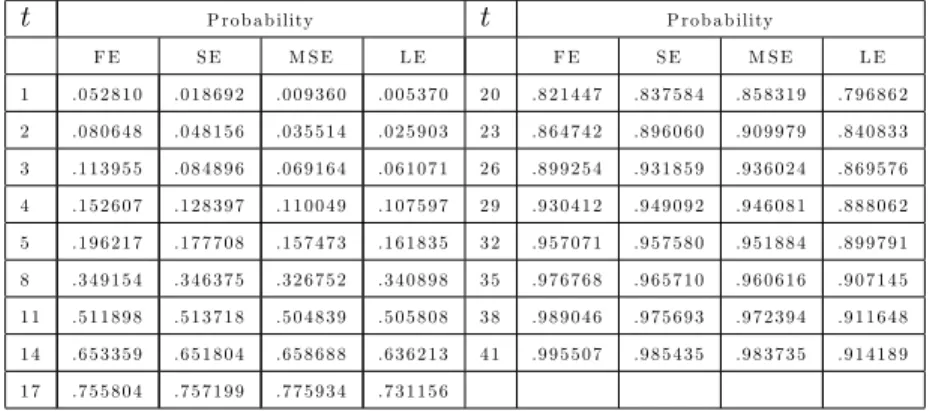
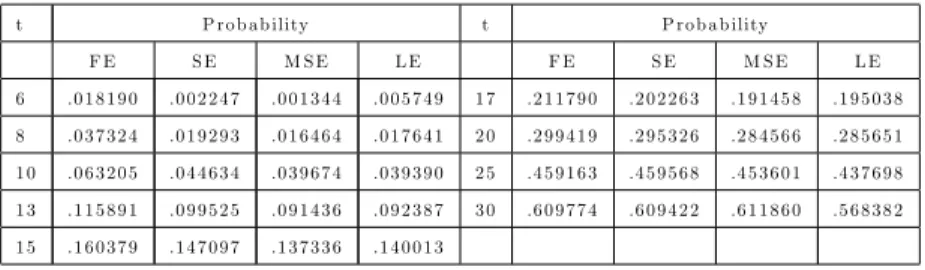
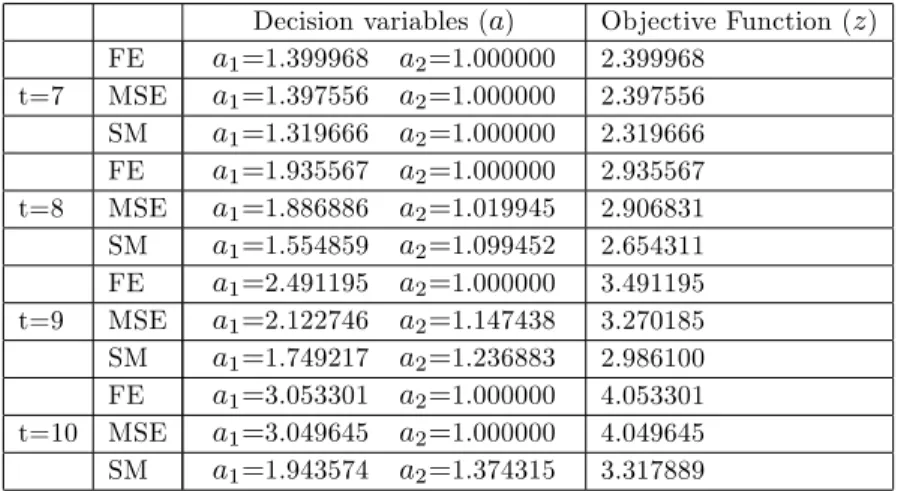
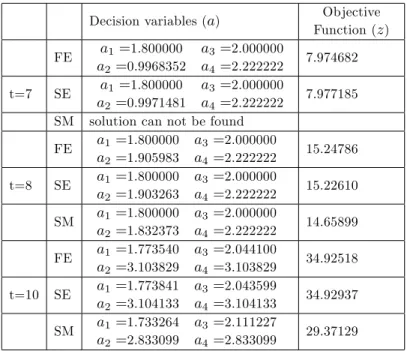
Benzer Belgeler
Bu araştırmada ekran başında şekerli içecek tüketen adölesanların günlük şekerli içecek tüketim miktarı istatiksel olarak anlamlı düzeyde daha fazladır
PCI6WEIEOt6cHFQGFCFCB6EXP6IGEQ6HU6GECEgPDSED6cHFQGFCFHED6aF6\R\GOR6
Medicine x 28 48 76 Medicine y 24 38 62 TOTAL 52 86 138 An example of 2*2 Contingency table Cell • 2 x 2 Contingency table • Table has 4 cells.. ASSUMPTIONS OF CHI SQUARE TEST
Sosyal Politika, Devletin sosyo -ekonomik hak ve özgürlüklere dayalı, sağlık, eğitim, sosyal koruma ve istihdam ve sosyal gibi politikaların uygulayarak herkes için asgari
In line with these previous studies, in our study, both groups of subjects revealed higher delta responses to target stimuli than nontarget stimuli and the delta oscillatory
Hibrid zeki kontrolör PWM referans gerilimini EAS ile önceden ayarlayarak istenen EMF performans değerinden uzaklaşılmasını engellemektedir. Bu durum, filtrasyon
Deneysel sonuçlar gösteriyor ki yapay sinir ağları kullanılarak hızlandırılmış takviyeli öğrenme metodu etmenin optimum yolu daha çabuk bularak hedefine
Swap, “belirli bir miktar ve nitelikteki para, döviz, mali araç, alacak, mal gibi varlıklarla yükümlülüklerin, önceden belirlenen fiyat ve koşullara göre, gelecekteki
