Privacy threats and practical solutions for genetic risk tests
Tam metin
Şekil
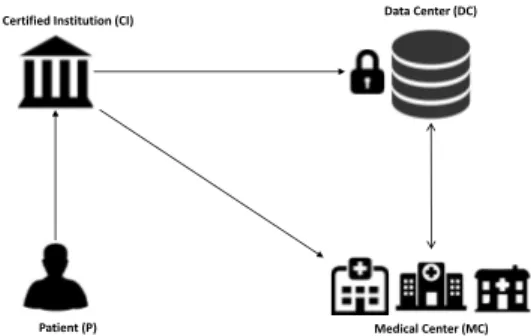
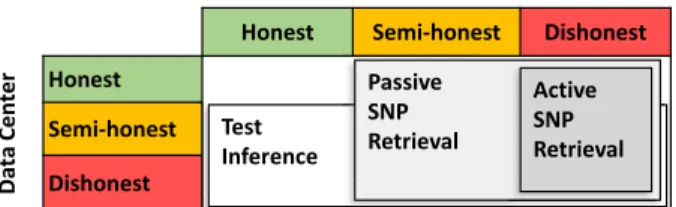
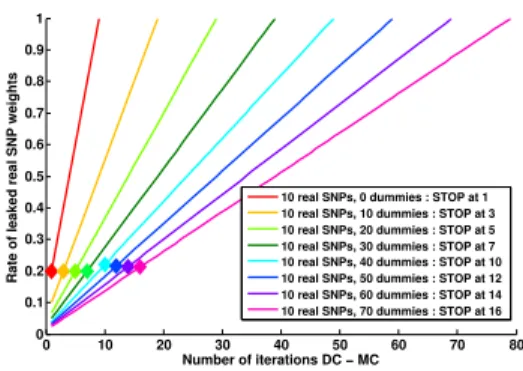
Benzer Belgeler
Then these individuals are evaluated using a fitness function (this thesis used two different fitness functions to assess the performance of the algorithm), after the normal
Disabled people, especially the handicapped people have great difficulties in using the Facebook since they cannot use their hands and fingers to navigate through
A new, observational, multicenter registry study protocol, APOLLON (A ComPrehensive, ObservationaL Registry of Heart FaiL- ure with Mid-range and Preserved EjectiON Fraction),
Today, it is known that cardiovascular risk factors (CVRFs), especially in combination, cause premature atherosclerosis and we think that they may lead to premature and intense
Bu adeta iddia gibi bir şey oldu, her sene bir eserini sahneye koymak işini yüklendim.. Bir sene sonra uzun uzadı ya çalışıldı ve tam eseri
Differentiation among the honey bee (Apis mellifera) subspecies is usually performed by methods of traditional morphometrics which based on multivariate analysis
Intermediate levels of miRNAs expression were observed as long as the disease was not medically reported (parents and sibling of sick children), in contrast to the much lower level
The Association Between Genetic Polymorphisms in Estrogen Receptor Genes and the Risk of Ocular Disease: A Meta-Analysis.. Turk J
