Baseline regularized sparse spatial filters
Tam metin
Şekil
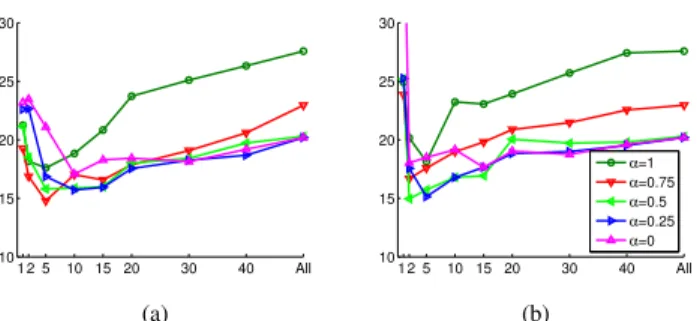
Benzer Belgeler
Asymptomatic patients displaying a type 1 Brugada ECG (either spontaneously or after sodium channel blockade) should undergo EPS if a family history of sudden cardiac
To predicate the phenomenon of location such as (under and surface of earth metals, underground water, pollution of environment, spread out of natural forests, also
The power capacity of the hybrid diesel-solar PV microgrid will suffice the power demand of Tablas Island until 2021only based on forecast data considering the
sanları, sokakta olup bitenleri, balo serpantin lerl gibi şemsiyesinin ucuna takıp beraberin de sürüklediği hissini
Zakir Avşar, Cengiz Mutlu, Mücahit Özçelik, Cihan Özgün, Aysun Sarıbey Haykıran, Ali Özkan, Mustafa Salep, Cemal Sezer, Tahir Sevinç, Bülent Şener,
But now that power has largely passed into the hands of the people at large through democratic forms of government, the danger is that the majority denies liberty to
Exploiting MILP via the formulation presented in this chapter has a fundamental advan- tage over the mainstream sparse signal recovery methods: The proposed formulation is not
This article aims to review the scientific researches about cardiac rehabilitation in Turkey and all in the world to demon- strate their number and distribution in journals by
