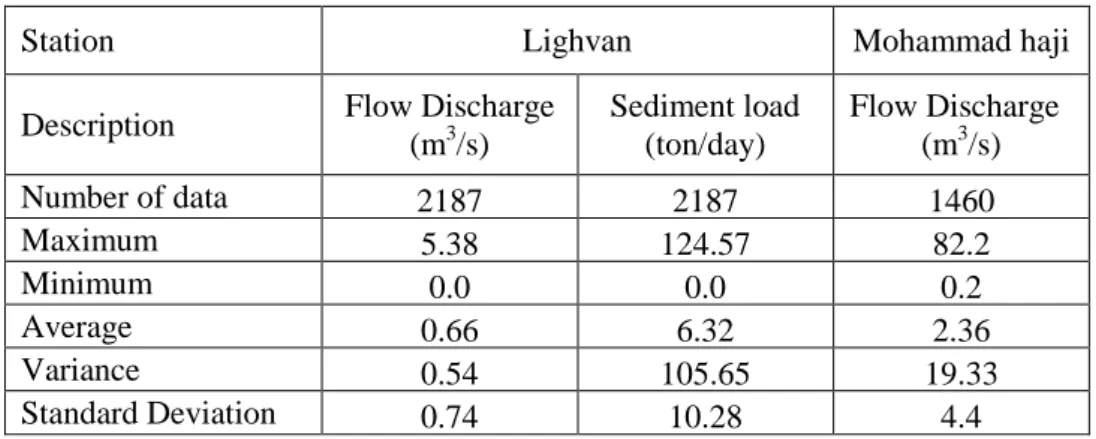
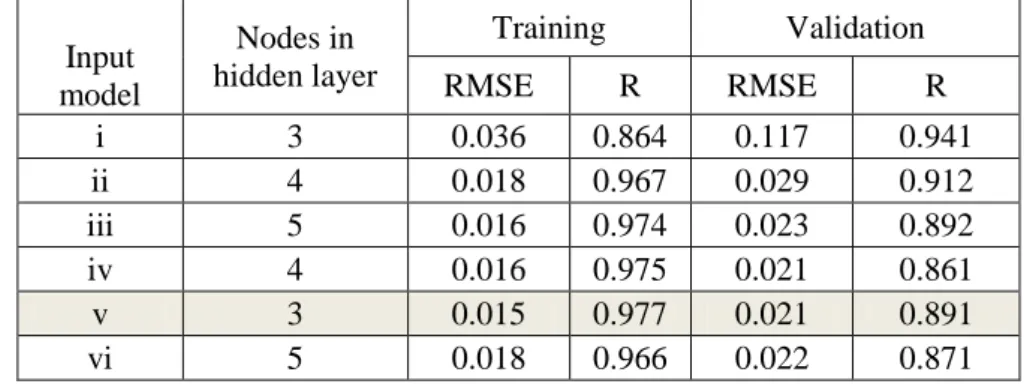
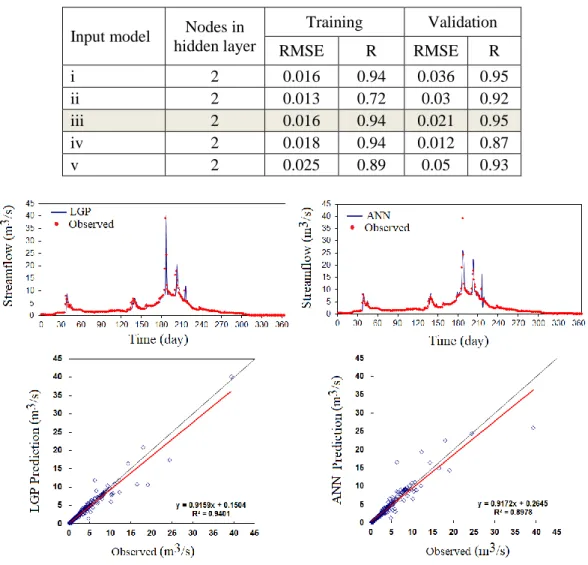
Streamflow and sediment load prediction using linear genetic programming
Tam metin
Şekil
Benzer Belgeler
虎添翼效果加成的作用。 在夏季治療冬病具有以下優勢:
S2 is wire bonded and loaded into an Oxford Triton 400 10mK dilution refrigerator at room temperature. Then, we start cooldown of the system down to 10 K in which temperature we
GEMİ DÜDÜĞÜ (FAKAT KÖTÜ GÖRÜŞLERDE VE BAŞKA GEMİLERİ RAHATSIZ ETMİYECEK ŞEKİLDE & DÜMEN DEĞİŞTİRME TALİMATI8. ( Eğer gemide olmayan madde var ise,
Bu âyetten önceki ifade, müteşâbihin te’viline yeltenmenin kınanmış olduğuna işaret etmektedir Zira Allah, “Kalplerinde eğrilik olan kimseler, fitne çıkarmak ve
Büyüyen Tarihi Sarıyer Muhallebicisi bu gün üç katlı büyük bir muhallebici dükkânı.. Kışın sahlep ve ekmek kadayıfı bulmak
Osman Ergin’in Belediye Camia sına kazandırdığı en büyük eser, bu gün hakikaten iftihar edilebilecek olan Belediye Matbaası, Belediye Kütüpha nesi ve
Thus Ur is quite different from Amarna (a single-period site), Pompeii, and the Athenian agora (where stone and baked bricks could be reused, and thus a high mound was not formed),
Bir milyar dolar kazanmak için 450 milyon dolar harcar mıydınız? Bu kritik sorunun cevabına GE Electric CEO’su Jack Welch duraksamadan evet cevabını vermiştir. Bu kadar
