Tanker kazaları sonrası İstanbul Boğazı'ndaki yakıt kirliliği simülasyonu
212
0
0
Tam metin
(2)
(3)
(4)
(5)
(6)
(7)
(8)
(9)
(10)
(11)
(12)
(13)
(14)
(15)
(16)
(17)
(18)
(19)
(20)
(21)
(22)
(24)
(25)
(26)
(27)
(28)
(29)
(30)
(31)
(33)
(34)
(35)
(36)
(38)
(39)
(40)
(41)
(42)
(43)
(44)
(45)
(46)
(47)
(48)
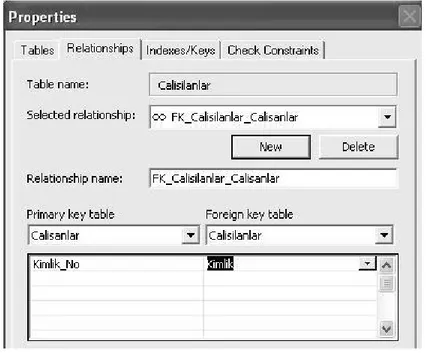
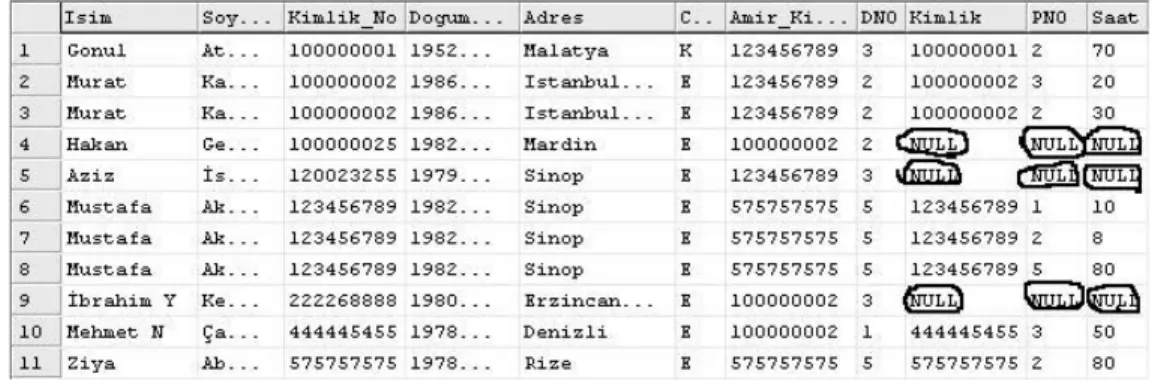
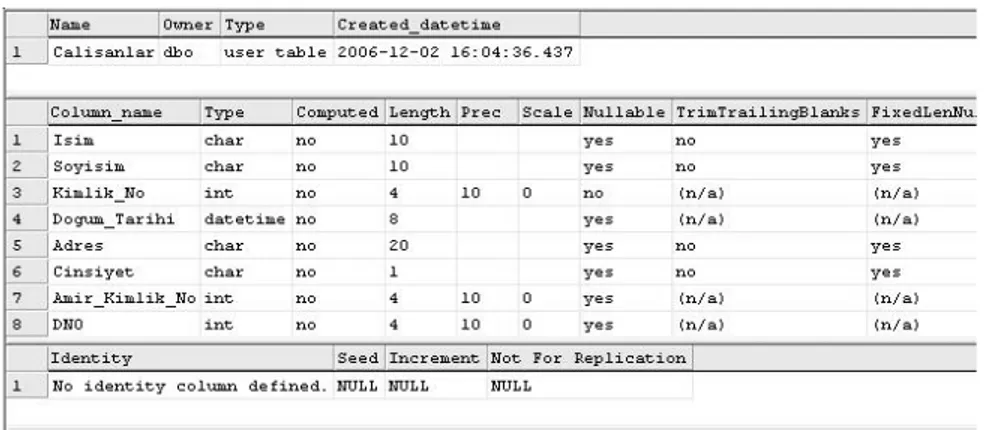
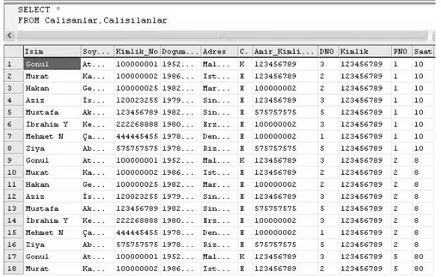
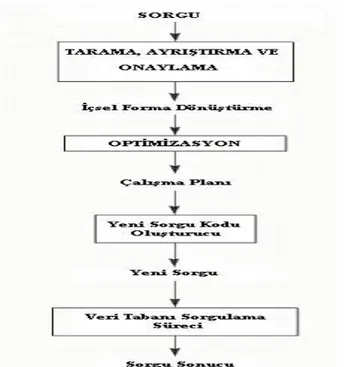
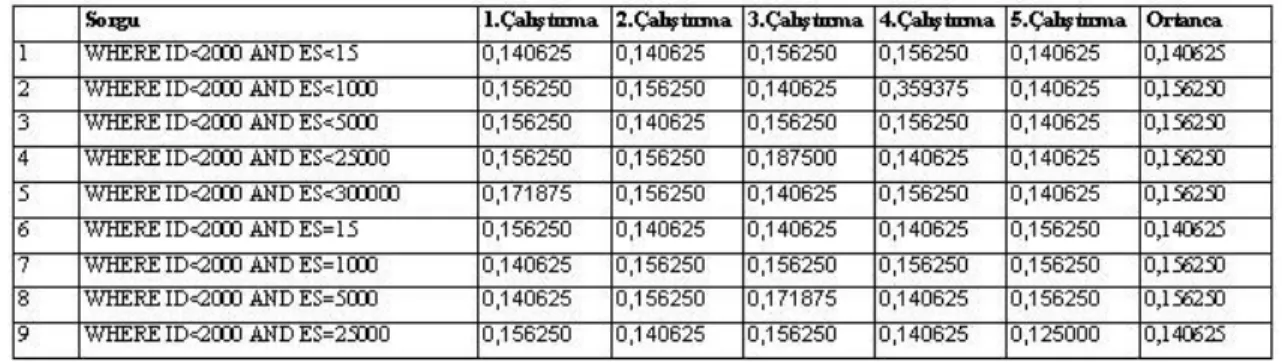
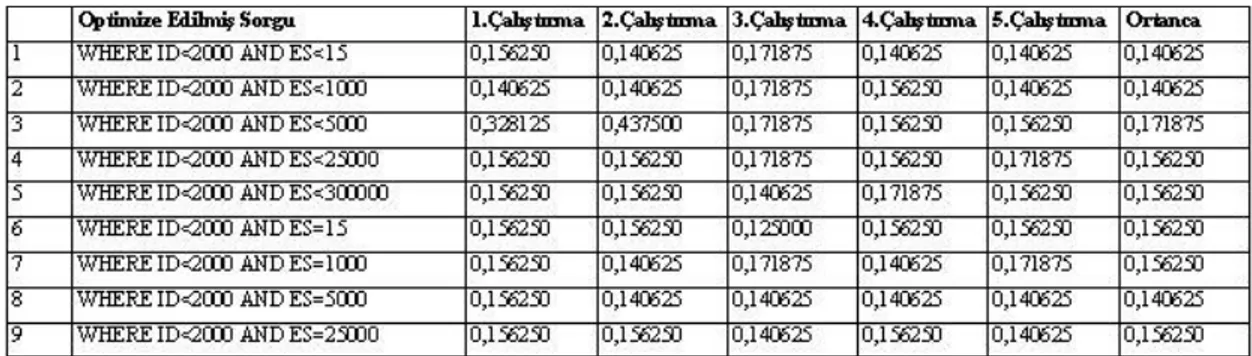
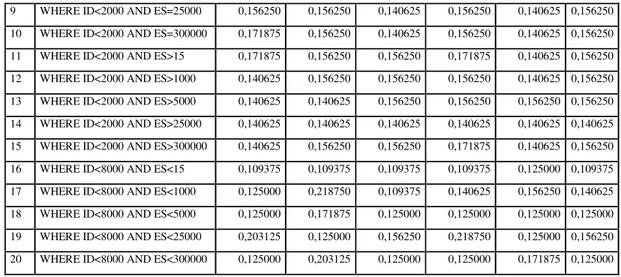
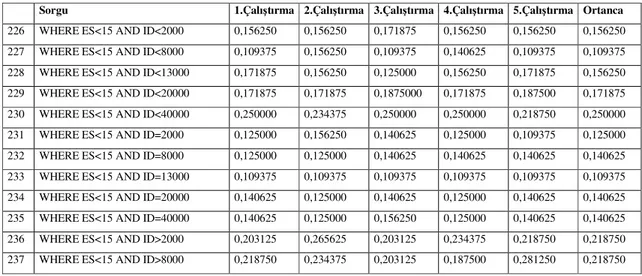
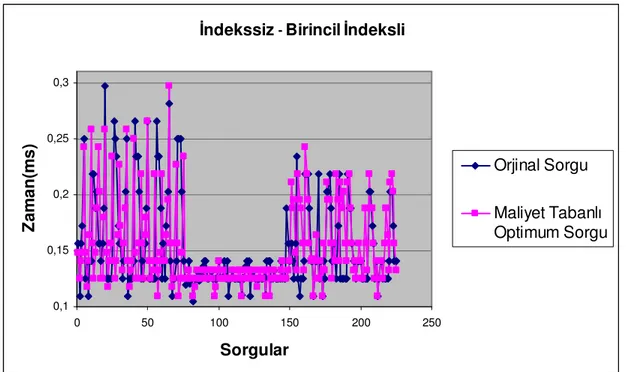
Şekil
+7
Benzer Belgeler
• Soru 4: Opel Astra ve Renault Megane marka araçların her ikisinden de kiralayan müşterilerin ad, soyad ve telefon numarası bilgilerini bulunuz.. Soru1: A004 kodlu aracı
Oracle Database Vault, verinin erişim güvenliği konusunda (kullanıcıların hassas uygulama verilerine erişimi vb.) dinamik ve esnek erişim kontrollerini sağlayan,
Tablolar verilerin satırlar ve sütunlar halinde düzenlenmesiyle oluşan veri grubudur.. Örneğin ders içeriği ve öğrenci bilgilerini veritabanında saklamak için
Personel tablosuna yeni bir kayıt eklemek için gerekli SQL ifadesini yazarak eklenen kaydın ad, soyad ve maaş bilgilerini OUTPUT ile tablo değişkenine aktarılmasını sağlayan
Tüm programlama dillerinde olduğu gibi akış kontrollerinde ve döngü yapılarında kullanılan komutlar birden fazla ise mutlaka BEGIN..END bloğunda yazılmalıdır....
İstenilen şart sağlandığında WHILE döngüsünden çıkmak için BREAK komutu kullanılır.. Programın çalışması WHILE’ın END’inin altındaki satırdan çalışmaya
@@ERROR sistem fonksiyonu ile yapılan hata denetimlerinde her SQL ifadesinden sonra hata denetimi yapılmalıdır.... DELETE FROM KITAP_YAZAR WHERE yazar_no=2 DELETE FROM YAZARLAR
Sütunlara verilen takma isimler verilebilir fakat Group by ve Having işleminde takma isimler yazılamaz.... SELECT SUM(maas) FROM tbl_personel WHERE
