ÖZET
Doktora Tezi
BİYOMEDİKAL SİNYALLERDE VERİ ÖN-İŞLEME TEKNİKLERİNİN MEDİKAL TEŞHİSTE SINIFLAMA DOĞRULUĞUNA ETKİSİNİN
İNCELENMESİ
Kemal POLAT Selçuk Üniversitesi Fen Bilimleri Enstitüsü
Elektrik-Elektronik Mühendisliği Anabilim Dalı Danışman: Yrd. Doç. Dr. Salih GÜNEŞ
2008, 151 sayfa
Jüri: Prof. Dr. Sadık KARA Prof. Dr. Mehmet BAYRAK Prof. Dr. Saadetdin HERDEM Yrd. Doç. Dr. Nihat YILMAZ Yrd. Doç. Dr. Salih GÜNEŞ
Bu tez çalışmasında, biyomedikal veri kümelerinin sınıflandırılmasında sınıflama performansını arttırmak için veri ağırlıklandırma ve özellik seçme yöntemleri önerilmiş ve kullanılmıştır. Biyomedikal veri kümelerini sınıflamada sınıflama performansını azaltan bazı etmenler vardır. Bu etmenler gürültü, aykırı değer, lineer olmayan bir veri dağılımına sahip olma gibi durumlardır. Yukarıdaki etmenlere sahip olan veri kümelerinin sınıflama performanslarını arttırmak için çeşitli veri ön-işleme teknikleri kullanılır.
Biyomedikal veri kümelerinde, özellik çıkarımından sonra oluşturulan veri setinin boyutu fazla olabilir veya veri setinde ilgisiz/fazla özellikler olabilir. Bu özelliklerin dezavantajları; sınıflama performansını azaltır ve sınıflandırıcının hesaplama maliyetini arttırır. Yapılan çalışmalarda, özellik seçme algoritmaları ile daha yüksek genelleştirme yeteneği ve daha az işlem karışıklığı elde edilmiştir. Bu tez çalışmasında, boyut azaltımı ve özellik seçme algoritması olarak, temel bileşen analizi, bilgi kazancına dayanan özellik seçme algoritması ve Kernel F-skor özellik seçme yöntemleri özelik seçme algoritmaları olarak kullanılmıştır. Bu yöntemler arasında, özellik seçme olarak, bilgi kazancına dayanan özellik seçme algoritması ile Kernel F-skor özellik seçme yöntemi ön plana çıkmaktadır. Boyut azaltımı olarak da temel bileşen analizine ağırlık verilmiştir.
Veri ağırlıklandırma yöntemleri olarak, bulanık ağırlıklandırma ön-işleme, k-NN (k-en yakın komşu) tabanlı veri ağırlıklandırma ön-işleme, genelleştirilmiş ayrışım analizi ve benzerlik tabanlı veri ağırlıklandırma ön-işleme yöntemleri medikal veri kümelerini sınıflamada sınıflama performansını iyileştirmek için kullanılmış ve önerilmiştir.
Bu tez çalışmasında kullanılan biyomedikal veri kümeleri; kalp hastalığı, SPECT (Single Photon Emission Computed Tomography) görüntüleri ile kalp hastalığı, E.coli Promoter gen dizileri, Doppler sinyali ile damar sertliği (Atherosclerosis) hastalığı, VEP (Görsel Uyarılmış Potansiyel) sinyali ile optik sinir hastalığı ve PERG (Örüntü Retinografisi) sinyali ile Macular hastalığı veri kümeleridir. Bu veri kümeleri içinden, kalp hastalığı, SPECT (Single Photon Emission Computed Tomography) görüntüleri ile kalp hastalığı, E.coli Promoter gen dizileri veri kümeleri, UCI (University of California, Irvine) makine öğrenmesi veritabanından alınmıştır. Doppler sinyali ile damar sertliği hastalığı, VEP sinyali ile optik sinir hastalığı ve PERG sinyali ile Macular hastalığı veri kümeleri ise Fatih Üniversitesi Öğretim Üyesi Prof. Dr. Sadık Kara ve Erciyes Üniversitesi Biyomedikal Mühendisliği ekibi tarafından alınan verilerdir.
Veri ön-işleme ve özellik seçme yöntemlerinin performanslarını değerlendirmek için bu yöntemler sınıflama algoritmaları ile hibrid olarak kullanılmışlardır. Kullanılan sınıflama algoritmaları, ANFIS (Adaptif Ağ Tabanlı Bulanık Çıkarım Sistemi), C4.5 karar ağacı, YBTS (Yapay Bağışıklık Tanıma Sistemi), bulanık kaynak dağılım mekanizmalı YBTS ve yapay sinir ağlarıdır.
Biyomedikal veri kümelerinin sınıflandırılması sonucunda, veri ağırlıklandırma yöntemleri arasında en iyi sonuçları veren yöntem, k-NN (k- en yakın komşu) tabanlı veri ağırlıklandırma yöntemi olmuştur. Özellik seçme yöntemleri arasında ise temel bileşen analizi diğer özellik seçme yöntemlere göre üstün sonuçlar elde etmiştir.
Özellik seçme yöntemleri, veri ağırlıklandırma yöntemleri ile sınıflama algoritmaları birleştirilerek 12 yeni hibrid sistem oluşturulmuş ve bu yeni hibrid sistemler tezde kullanılan 6 medikal veri kümesine uygulanmıştır. Hesaplama maliyeti ve sınıflama performansı açısından her bir medikal veri kümesi için en iyi hibrid model seçilmiştir.
Anahtar Kelimeler – Sınıflama, Özellik Seçme, Veri Ağırlıklandırma, Medikal Veri
ABSTRACT
PhD. Thesis
THE INVESTIGATION OF EFFECT OF DATA PRE-PROCESSING TECHNIQUES TO CLASSIFICATION ACCURACY ON MEDICAL
DIAGNOSIS IN BIOMEDICAL SIGNALS
Kemal POLAT Selcuk University
Graduate School of Natural and Applied Sciences Department of Electrical-Electronics Engineering
Supervisor: Assist. Prof. Dr. Salih GÜNEŞ 2008, 151 pages
Jury: Prof. Dr. Sadık KARA Prof. Dr. Mehmet BAYRAK Prof. Dr. Saadetdin HERDEM Assist. Prof. Dr. Nihat YILMAZ Assist. Prof. Dr. Salih GÜNEŞ
In this PhD. thesis, data weighting and feature selection methods are proposed and used for increasing the performance of classification of biomedical datasets. There are some factors that decrease the classification performance on classification of biomedical datasets. These factors are noise, invalid data, non-linearly separable data distribution etc. Various data pre-processing methods are used to increase the classification performance of medical datasets afflicted above factors. In the biomedical datasets, after feature extraction, the dimension of produced dataset can be huge or biomedical datasets may contain the irrelevant or redundant
features. The disadvantages of these features are as follows: they decrease the classification performance and increase the computation cost of classifier. In the conducted studies, higher generalization ability and lesser operational complexity are achieved with feature selection and dimensionality reduction algorithms. In this thesis, principal component analysis, feature selection algorithm based on information gain, and kernel f-score feature selection methods are proposed and used as feature selection and dimensionality reduction algorithms. Among these methods, feature selection algorithm based on information gain and kernel f-score feature selection methods are emphasized. As for the dimensionality reduction process, more weight is given to principal component analysis.
As data weighting methods, fuzzy weighted pre-processing, k-NN based weighted pre-processing, generalized discriminant analysis, similarity based weighted pre-processing methods are proposed and used to improve the performance of classifier in classification of biomedical datasets. Among above methods, the proposed data weighted methods are fuzzy weighted pre-processing, k-NN based weighted pre-processing, and similarity based weighted pre-processing methods.
In this PhD. thesis, the used biomedical datasets are heart disease, heart disease with SPECT (Single Photon Emission Computed Tomography) images, E.coli Promoter gene sequences, Atherosclerosis disease with Doppler signals, optic nerve disease with VEP (Visual Evoked Potentials) signals, and macular disease with PERG (Pattern Electroretinography) datasets. Among datasets, heart disease, heart disease with SPECT (Single Photon Emission Computed Tomography) images, E.coli Promoter gene sequences datasets are taken from UCI (University of California, Irvine) machine learning database. The other datasets including Atherosclerosis disease with Doppler signals, optic nerve disease with VEP signals, and macular disease with PERG datasets are taken from Prof. Dr. Sadık Kara in Fatih University and biomedical engineering team in Erciyes University.
In order to evaluate the performances of data weighting and feature selection methods, these methods are used as hybrid with classifier algorithms. Used classification algorithms are ANFIS (Adaptive Network Based Fuzzy Inference System), C4.5 decision tree classifier algorithm, AIRS (Artificial Immune Recognition Immune System), Fuzzy-AIRS (Artificial Immune Recognition Immune System with Fuzzy Resource Allocation Mechanism) and Artificial neural network.
As a result of classifying the biomedical datasets, k-NN based weighted method was the best data weighting method among others. Among feature selection methods, the principal component analysis was superior to other methods.
The twelve new hybrid systems was created combining feature selection methods, data weighting methods and classifier algorithms. These novel hybrid systems were applied to six medical datasets used in this thesis. The best hybrid system in terms of computation time and classification performance was chosen for each medical dataset.
Keywords – Classification, Feature Selection, Data Weighting, Medical Datasets,
TEŞEKKÜR
Çalışmama verdiği destek ve gösterdiği anlayıştan dolayı danışmanım sayın Yrd.Doç.Dr. Salih GÜNEŞ’e, tez süresince belirttikleri görüşler ve önerilerle tezin yönlenmesinde yardımcı olan Tez İzleme Komitesi Üyeleri sayın Prof.Dr. Sadık KARA ve sayın Prof.Dr. Saadetdin HERDEM’e, Bölüm Başkanımız sayın Prof. Dr. Mehmet BAYRAK’a, Makine Öğrenmesi alanında sağladığı değerli bilgilerden dolayı sayın Prof.Dr. Ahmet ARSLAN’a, beraberce yapmış olduğumuz çalışmalardan dolayı sayın Arş.Gör.Dr. Seral ÖZŞEN’e, sayın Arş.Gör.Dr. Halife KODAZ’a ve Arş. Gör. Bayram AKDEMİR’e, Selçuk Üniversitesi Mühendislik-Mimarlık Fakültesi Elektrik-Elektronik Mühendisliği ve Bilgisayar Mühendisliği Bölümlerindeki tüm çalışma arkadaşlarıma ve özellikle manevi desteğini hiç bir zaman benden esirgemeyen her zaman ve her koşulda hep yanımda olan aileme sonsuz teşekkür ederim.
Kemal POLAT 2008, Konya
İÇİNDEKİLER
ÖZET...i
ABSTRACT...iii
TEŞEKKÜR ...v
İÇİNDEKİLER ...vi
SİMGELER VE KISALTMALAR ...viii
ŞEKİLLER LİSTESİ...x
TABLOLAR LİSTESİ...xii
1. GİRİŞ ...xii
1.1. Literatür Araştırması ...5
1.2. Çalışmanın Temel Amacı ve Literatüre Katkıları...14
1.3. Çalışmanın Kapsamı ve Organizasyonu ...15
2. ÖZELLİK ÇIKARMA VE ÖZELLİK SEÇME YÖNTEMLERİ ...17
2.1. Özellik Çıkarımı İşlemi ve Welch Metodu ...18
2.1.1. Pencereleme İşlemi ...18
2.1.2. Fourier analizi ile güç spektrum yoğunluğunun bulunması...19
2.2. Özellik Seçme ve Boyut Azaltımı Yöntemleri...23
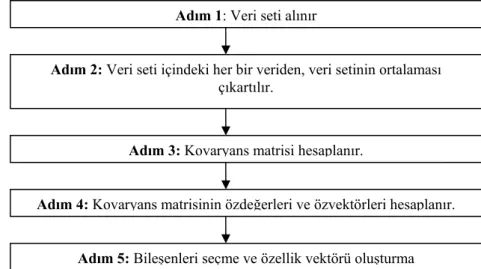
2.2.1. Temel bileşen analizi–TBA (Principal component analysis-PCA)...24
2.2.2. Bilgi kazancına dayanan özellik seçme algoritması...28
2.2.3. Kernel F-Skor özellik seçme yöntemi...33
3. VERİ AĞIRLIKLANDIRMA VE ÖN-İŞLEME YÖNTEMLERİ ...38
3.1. Bulanık Mantık Tabanlı Veri Ağırlıklandırma İşlemi ...39
3.2. k-NN (k-en yakın) Komşu Tabanlı Veri Ağırlıklandırma İşlemi ...43
3.3. Genelleştirilmiş Ayrışım Analiz (GAA) Yöntemi ...46
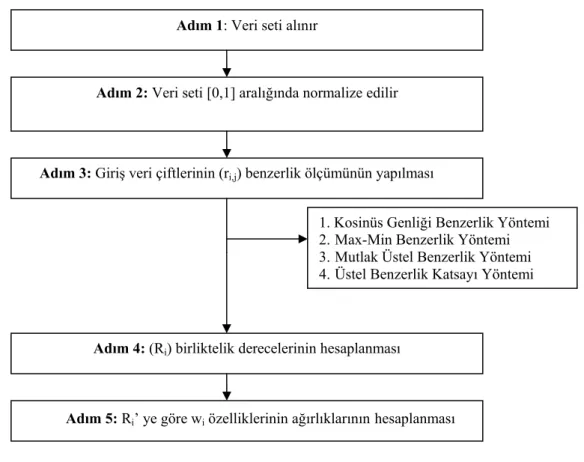
3.4. Benzerlik Tabanlı Veri Ağırlıklandırma Yöntemi ...49
4. BİYOMEDİKAL VERİLERİ SINIFLAMADA KULLANILAN YÖNTEMLER ...55
4.1. Sınıflama Algoritmaları ...55
4.1.1. Çok katmanlı algılayıcı yapay sinir ağları ...56
4.1.2. Geriye yayılım (Back-propagation) algoritması ...57
4.2. ANFIS (Adaptive Network Based Fuzzy Inference System) ...58
4.3. Yapay Bağışıklık Tanıma Sistemi (Artificial Immune Recognition System) Sınıflama Algoritması...64
4.4. Bulanık Kaynak Dağılımlı Yapay Bağışıklık Tanıma Sistemi (Fuzzy- AIRS) ...65
4.5. C4.5 Karar Ağaçları ...70
5. KULLANILAN BİYOMEDİKAL VERİ KÜMELERİ...72
5.1. Özelliği Belirlenmiş Medikal Veri Kümeleri...72
5.1.1. Kalp hastalığı veri kümesi...73
5.1.2. E. Coli promoter gen dizileri veri kümesi...75
5.1.3. SPECT (Single Photon Emission Computed Tomography) görütüleri kalp hastalığı teşhisi veri kümesi ...78
5.2. Özelliği Çıkarılmış Medikal Veri Kümeleri ...80
5.2.1. Doppler sinyali ile damar sertliği veri kümesi uygulamaları...80
5.2.2. VEP (Visual Evoked Potential- Görsel Uyarılmış Potansiyel) sinyali ile optik sinir hastalığı veri kümesi ...83
5.2.3. PERG (Pattern Electroretinography) sinyali ile Macular hastalığı veri kümesi ...87
6. VERİ ÖN-İŞLEME YÖNTEMLERİNİN MEDİKAL VERİ KÜMELERİNİ SINIFLAMADAKİ PERFORMANSI VE UYGULAMA SONUÇLARI...90
6.1. Performans Ölçüm Kriterleri...91
6.1.1. 5-kat kez çaprazlama ile veri kümeleri ayırma ...92
6.1.2. Sınıflama doğruluğu ve duyarlılık-seçicilik değerleri...93
6.1.3. ROC (Receiver Operating Characterictics-Alıcı İşlem Karakteristiği) eğrileri ve eğrinin altında kalan alan (AUC)...95
6.2. Veri Ağırlıklandırma Yöntemlerinin Etkisi ...97
6.2.1. Bulanık mantık veri ağırlıklandırma yöntemi sonuçları ...99
6.2.2. k-NN (k-en yakın komşu) tabanlı veri ağırlıklandırma yöntemi sonuçları ...101
6.2.3. Genelleştirilmiş ayrışım analizi (Generalized Discriminant Analysis) sonuçları ...108
6.2.4. Benzerlik tabanlı veri ağırlıklandırma veri ön-işleme yöntemi sonuçları110 6.3. Boyut Azaltımı ve Özellik Seçme Yöntemlerinin Etkisi ...116
6.3.1. Temel bileşen analizi ile boyut azaltımı yönteminin sonuçları...117
6.3.2. Kernel F-skor özellik seçme yönteminin sonuçları...119
6.3.3. Bilgi kazancına dayanan özellik seçme yönteminin sonuçları...126
6.4. Ön-işleme ve Özellik Seçme Yöntemleri Birleştirilerek Oluşturulan Hibrid Sistemler ...129
7. SONUÇLAR VE ÖNERİLER ...138
7.1. Sonuçlar ...138
7.2. Öneriler ...142
SİMGELER VE KISALTMALAR
ab : Tek bir antikoru ifade etmektedir.
AB : Antikor kümesini ifade etmektedir.
ab.c : Tek bir ab antikorunun sınıf değerini temsil etmektedir.
ab.uyarım : Tek bir ab antikorunun uyarım seviyesini ifade etmektedir.
ab.kaynak : Tek bir ab antikoruna tahsis edilen kaynak sayısını ifade etmektedir.
ADD : Ayrık dalgacık dönüşümü
ag : Tek bir ag antijenini ifade etmektedir.
ag.c : Tek bir ag antijenin sınıfını ifade etmektedir.
ag.f : Tek bir antijenin özellik vektörünü ifade etmektedir.
ANFIS : Adaptif ağ tabanlı bulanık çıkarım sistemi (Adaptive network based fuzzy inference system)
ANN : Yapay sinir ağları (Artificial neural network)
AIRS : Yapay bağışıklık tanıma sistemi (Artificial immune
recognition system)
AR : Özbağlanımlı (Autoregressive)
ATS : Duyarlılık eşik ölçüsü (Affinity threshold scalar)
AUC : ROC eğrisi altında kalan alan (Area under the ROC curve)
AWAIS : Özellik ağırlıklandırmalı yapay bağışıklık sistemi (Attribute weighted artificial immune system)
BBA : Bağımsız bileşen analizi BKO : Bulanık kümele ortalama
BKÖS : Bilgi kazancına dayanan özellik seçme algoritması BVAÖ : Bulanık veri ağırlıklandırma ön-işleme yöntemi ECG : Elektrokardiyogram
EEG : Electroencephalography (Beyin sinyalleri)
Entropi :Verideki rasgeleliği, belirsizliği, kirliliği, beklenmeyen
durumun ortaya çıkma olasılığını karakterize eden bir ölçüdür.
FFT : Hızlı fourier dönüşümü (Fast Fourier transform)
GRNN : Genel regresyon sinir ağları (General regression neural
GUI : Grafiksel kullanıcı arabirimi (Graphical user interface)
Fuzzy-AIRS : Bulanık-yapay bağışıklık tanıma sistemi (Fuzzy-artificial
immune recognition system)
GAA : Genelleştirilmiş ayrışım analizi ID3 : Iterative Dichotomiser 3
Kaynak sayısı : İzin verilen sistem kaynaklarının toplam sayısını ifade
etmektedir.
KFSÖS : Kernel F-skor özellik seçme yöntemi k-NN : k-en yakın komşu (k-nearest neighbor) LAA : Lineer ayrışım analizi
LM : Levenberg marquard
Mutasyon oranı : Bir antikorun herhangi bir özelliğinin mutasyona uğrama
olasılığını işaret eden 0 ile 1 arasında bir parametredir.
ÖVN : Öğrenme vektör niceleme
PERG : Örüntü retinografisi (Pattern Electroretinography) RBF : Radyal taban fonksiyonu (Radial basis function)
ROC :Alıcı işlem karakteristiği (Receiver operating characteristics) SPECT : Tek foton emisyon hesaplanmış tomografi (Single photon
emission computed tomography)
TBA : Temel bileşen analizi
UCI : University of California, Irvine
Uyarma eşiği : Antijenin eğitimi için bir durma kriteri olarak kullanılan 0 ile
1 arasında bir parametredir.
VEP : Görsel uyarılmış potansiyel (Visual evoked potential) YBS : Yapay bağışıklık sistemi
YBTS : Yapay bağışıklık tanıma sistemi YSA : Yapay sinir ağları
ŞEKİLLER LİSTESİ
Şekil 1.1 Tezde kullanılan örüntü tanıma sisteminin blok diyagramı………...3
Şekil 2.1 Özellik çıkarımı ve özellik seçmeyi gösteren bir blok diyagramı...18
Şekil 2.2 44100 Hz’ de örneklenmiş bir Doppler sinyali örneği...21
Şekil 2.3 64 pencereye ayrılmış Doppler sinyalinin Welch yöntemi sonucu güç spektrum yoğunluğu...22
Şekil 2.4 128 pencereye ayrılmış Doppler sinyalinin Welch yöntemi sonucu güç spektrum yoğunluğu...22
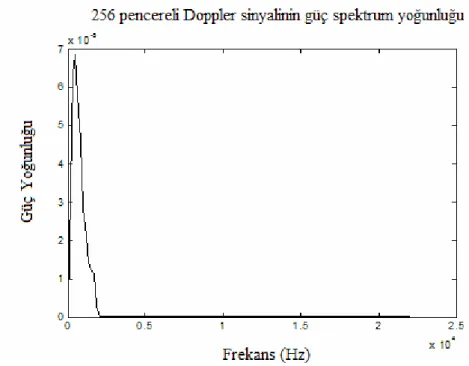
Şekil 2.5 256 pencereye ayrılmış Doppler sinyalinin Welch yöntemi sonucu güç spektrum yoğunluğu...23
Şekil 2.6 Temel bileşen analizinin blok diyagramı...24
Şekil 2.7 Bilgi kazancı tabanlı özellik seçme algoritması...29
Şekil 2.8 C4.5 veri ayrışımı...29
Şekil 2.9 Kernel F-skor özellik seçme yönteminin akış şeması...35
Şekil 2.10 Orijinal XOR veri dağılımı...36
Şekil 2.11 RBF Kernel uzayına attıktan sonraki veri dağılımı...37
Şekil 2.12 Lineer Kernel uzayına attıktan sonraki veri dağılımı...37
Şekil 3.1 Giriş üyelik fonksiyonları...39
Şekil 3.2 Çıkış üyelik fonksiyonları...39
Şekil 3.3 k-NN tabanlı veri ağırlıklandırma ön-işleme metodunun blok diyagramı...43
Şekil 3.4 Genelleştirilmiş ayrışım analizi yönteminin akış şeması...48
Şekil 3.5 Benzerlik tabanlı veri ağırlıklandırma ön-işlemenin blok şeması...52
Şekil 4.1 Danışmalı öğrenme sisteminin şematik gösterimi...56
Şekil 4.2 Çok katmanlı bir perseptron...58
Şekil 4.3 ANFIS’ in öğrenme ve test akış diyagramı...59
Şekil 4.4 İki girişi bir ANFIS mimarisi...63
Şekil 4.5 YBTS' nin eğitme ve test akış şeması...65
Şekil 4.7 (a) Giriş Üyelik Fonksiyonu, (b) Çıkış Üyelik Fonksiyonu...68
Şekil 5.1 DNA nükleoitleri...76
Şekil 5.2 Doppler verisi elde etmek için kullanılan donanımın blok diyagramı...81
Şekil 5.3 Bileşenlerle etiketlenmiş normal VEP sinyali, N75, P100, N145 ise gecikmelerdir...84
Şekil 5.4 İki farklı insan gözünün VEP cevap örnekleri...84
Şekil 5.5 VEP sinyalini elde etmek için kullanılan sistemin blok diyagramı... 85
Şekil 5.6 İki farklı kişiye ait PERG cevabı sinyalleri...88
Şekil 6.1 Medikal verileri sınıflamak için kullanılan sistemin blok diyagramı...91
Şekil 6.2 Beş kat çaprazlamayı gösteren şematik bir diyagram...92
TABLOLAR LİSTESİ
Tablo 2.1 x ve y değişkeninden oluşan bir veri kümesi...27
Tablo 2.2 Ortalama değerden çıkarılmış veri kümesini yeni hali...27
Tablo 2.3 Sürekli değerli üç özelliğe sahip tenis oynama durumu için veri kümesi..31
Tablo 2.4 XOR problemi veri dağılımı...36
Tablo 3.1 Bulanık veri ağırlıklandırma ön-işleme için kullanılan bulanık kural tabanı...41
Tablo 3.2 x ve y değişkeninden oluşan veri kümesi...41
Tablo 3.3 x ve y değişkenin [0,1] aralığındaki normalize değerleri...42
Tablo 3.4 x ve y değişkenin bulanık ağırlıklandırma sonrası yeni değerleri...42
Tablo 3.5 x ve y değişkeninden oluşan veri kümesi...44
Tablo 3.6 x ve y değişkenin k-NN tabanlı veri ağırlıklandırma sonrası yeni dağılımı (k=3 için)...45
Tablo 3.7 x ve y değişkenin k-NN tabanlı veri ağırlıklandırma sonrası yeni dağılımı (k=4 için)...45
Tablo 3.8 x ve y değişkenin k-NN tabanlı veri ağırlıklandırma sonrası yeni dağılımı (k=5 için)...45
Tablo 3.9 x ve y değişkeninden oluşan veri kümesi...48
Tablo 3.10 x ve y değişkeninden oluşan veri kümesine GAA uygulandıktan sonraki veri dağılımı...49
Tablo 3.11 x ve y değişkeninden oluşan veri kümesi...53
Tablo 3.12 x ve y değişkenin [0,1] aralığındaki normalize değerleri...53
Tablo 3.13 x ve y değişkenin, kosinüs genliği benzerlik fonksiyonuna göre veri kümesinin ağırlıklandırılmış yeni dağılımı...53
Tablo 3.14 x ve y değişkenin, mutlak üstel benzerlik fonksiyonuna göre veri kümesinin ağırlıklandırılmış yeni dağılımı...54
Tablo 3.15 x ve y değişkenin, üstel benzerlik katsayı benzerlik fonksiyonuna göre veri kümesinin ağırlıklandırılmış yeni dağılımı...54
Tablo 4.2 Bulanık kaynak dağılımı için kural tabanı...69
Tablo 4.3 Giriş ve çıkış üyelik fonksiyonları için dilsel değerler...69
Tablo 4.4 Fuzzy kaynak dağılımı için örnek bir uygulama...70
Tablo 5.1 Kalp hastalığı veri kümesindeki özellikleri dağılımı...73
Tablo 5.2 Kalp hastalığı veritabanında her bir durum için çıkış değerlerine bağlı özellikler...74
Tablo 5.3 Kalp hastalığı veri kümesinde bulunan özelliklerin istatistiki değerleri....74
Table 5.4 Promoterlar için bir alan teorisi...76
Tablo 5.5 E. Coli promoter gen dizileri veritabanında her bir durum için çıkış değerlerine bağlı özellikler...76
Tablo 5.6 DNA dizilerindeki nükleoitlerin görülme sıklıkları...76
Tablo 5.7 E. Coli promoter gen dizileri veri kümesinde bulunan özelliklerin istatistiki değerleri...77
Tablo 5.8 Kalp ile ilgili SPECT görüntüleri veritabanında her bir durum için çıkış değerlerine bağlı özellikler...79
Tablo 5.9 Kalp ile ilgili SPECT görüntüleri veri kümesinde bulunan özelliklerin istatistiki değerleri...79
Tablo 5.10 Doppler sinyali ile damar sertliği veri kümesinde her bir durum için çıkış değerlerine bağlı özellikler...81
Tablo 5.11 Doppler sinyali ile damar sertliği veri kümesinde bulunan özelliklerin istatistiki değerleri... 82
Tablo 5.12 VEP sinyali ile optik sinir hastalığı veri kümesinde her bir durum için çıkış değerlerine bağlı özellikler...85
Tablo 5.13 VEP sinyali ile optik sinir hastalığı veri kümesinde bulunan özelliklerin istatistiki değerleri...86
Tablo 5.14 PERG sinyali ile Macular hastalığı veri kümesinde her bir durum için çıkış değerlerine bağlı özellikler...88
Tablo 5.15 PERG sinyali ile Macular hastalığı veri kümesinde bulunan özelliklerin istatistiki değerleri... 88
Tablo 6.1 Karışıklık matrisinin gösterimi...93
Tablo 6.2 Sınıflama sonuç tablosu...94 Tablo 6.3 Kalp hastalığı veri kümesinin sınıflandırılmasında ön-işlemesiz
sınıflandırıcılardan elde edilen sonuçlar...97 Tablo 6.4 E.coli promoter gen dizileri veri kümesinin sınıflandırılmasında
ön-işlemesiz sınıflandırıcılardan elde edilen sonuçlar...98 Tablo 6.5 SPECT görüntüleri veri kümesinin sınıflandırılmasında ön-işlemesiz sınıflandırıcılardan elde edilen sonuçlar...98 Tablo 6.6 Doppler sinyali ile damar sertliği veri kümesinin sınıflandırılmasında ön-işlemesiz sınıflandırıcılardan elde edilen sonuçlar...98 Tablo 6.7 VEP sinyali ile optik sinir hastalığı veri kümesinin sınıflandırılmasında
ön işlemesiz sınıflandırıcılardan elde edilen sonuçlar...98 Tablo 6.8 PERG sinyali ile Macular hastalığı veri kümesinin sınıflandırılmasında ön-işlemesiz sınıflandırıcılardan elde edilen sonuçlar...99 Tablo 6.9 Kalp hastalığı veri kümesinin sınıflandırılmasında, bulanık mantık
veri ağırlıklandırma veri ön-işleme ile sınıflandırıcıların birleşiminden elde edilen sonuçlar...99 Tablo 6.10 E.coli promoter gen dizileri veri kümesinin sınıflandırılmasında,
bulanık mantık veri ağırlıklandırma veri ön-işleme
ile sınıflandırıcıların birleşiminden elde edilen sonuçlar...101 Tablo 6.11 SPECT görüntüleri veri kümesinin sınıflandırılmasında,
bulanık mantık veri ağırlıklandırma veri ön-işleme
ile sınıflandırıcıların birleşiminden elde edilen sonuçlar... 100 Tablo 6.12 Doppler sinyali ile damar sertliği veri kümesinin sınıflandırılmasında,
bulanık mantık veri ağırlıklandırma veri ön-işleme
ile sınıflandırıcıların birleşiminden elde edilen sonuçlar... 100 Tablo 6.13 VEP sinyali ile optik sinir hastalığı veri kümesinin
sınıflandırılmasında, bulanık mantık veri ağırlıklandırma veri
ön-işleme ile sınıflandırıcıların birleşiminden elde edilen sonuçlar.... 100 Tablo 6.14 PERG sinyali ile Macular hastalığı veri kümesinin
sınıflandırılmasında, bulanık mantık veri ağırlıklandırma veri
ön-işleme ile sınıflandırıcıların birleşiminden elde edilen sonuçlar...101 Tablo 6.15 Kalp hastalığı veri kümesinin sınıflandırılmasında,
k-NN tabanlı veri ağırlıklandırma veri ön-işleme ile sınıflandırıcıların birleşiminden elde edilen sonuçlar...102 Tablo 6.16 E.coli promoter gen dizileri veri kümesinin sınıflandırılmasında,
k-NN tabanlı veri ağırlıklandırma veri ön-işleme ile sınıflandırıcıların birleşiminden elde edilen sonuçlar...103 Tablo 6.17 SPECT görüntüleri veri kümesinin sınıflandırılmasında,
k-NN tabanlı veri ağırlıklandırma veri ön-işleme ile sınıflandırıcıların birleşiminden elde edilen sonuçlar...104 Tablo 6.18 Doppler sinyali ile damar sertliği veri kümesinin sınıflandırılmasında,
k-NN tabanlı veri ağırlıklandırma veri ön-işleme ile sınıflandırıcıların birleşiminden elde edilen sonuçlar...105 Tablo 6.19 VEP sinyali ile optik sinir hastalığı veri kümesinin sınıflandırılmasında,
k-NN tabanlı veri ağırlıklandırma veri ön-işleme ile sınıflandırıcıların birleşiminden elde edilen sonuçlar...106 Tablo 6.20 PERG sinyali ile Macular hastalığı veri kümesinin sınıflandırılmasında,
k-NN tabanlı veri ağırlıklandırma veri ön-işleme ile sınıflandırıcıların birleşiminden elde edilen sonuçlar...107 Tablo 6.21 Kalp hastalığı veri kümesinin sınıflandırılmasında,
genelleştirilmiş ayrışım analizi ile sınıflandırıcıların birleşiminden elde edilen sonuçlar...109 Tablo 6.22 E.coli promoter gen dizileri veri kümesinin sınıflandırılmasında,
genelleştirilmiş ayrışım analizi ile sınıflandırıcıların birleşiminden elde edilen sonuçlar...109 Tablo 6.23 SPECT görüntüleri veri kümesinin sınıflandırılmasında,
genelleştirilmiş ayrışım analizi ile sınıflandırıcıların birleşiminden
elde edilen sonuçlar... 109 Tablo 6.24 Doppler sinyali ile damar sertliği veri kümesinin sınıflandırılmasında,
genelleştirilmiş ayrışım analizi ile sınıflandırıcıların birleşiminden elde edilen sonuçlar... 109 Tablo 6.25 VEP sinyali ile optik sinir hastalığı veri kümesinin
sınıflandırılmasında, genelleştirilmiş ayrışım analizi ile
Tablo 6.26 PERG sinyali ile Macular hastalığı veri kümesinin sınıflandırılmasında, genelleştirilmiş ayrışım analizi ile
sınıflandırıcıların birleşiminden elde edilen sonuçlar...110 Tablo 6.27 Kalp hastalığı veri kümesinin sınıflandırılmasında, benzerlik tabanlı
veri ağırlıklandırma ön-işleme yöntemi ile sınıflandırıcıların
birleşiminden elde edilen sonuçlar...111 Tablo 6.28 E.coli promoter gen dizileri veri kümesinin sınıflandırılmasında,
benzerlik tabanlı veri ağırlıklandırma ön-işleme yöntemi ile
sınıflandırıcıların birleşiminden elde edilen sonuçlar...112 Tablo 6.29 SPECT görüntüleri veri kümesinin sınıflandırılmasında,
benzerlik tabanlı veri ağırlıklandırma ön-işleme yöntemi ile
sınıflandırıcıların birleşiminden elde edilen sonuçlar...113 Tablo 6.30 Doppler sinyali ile damar sertliği veri kümesinin
sınıflandırılmasında, benzerlik tabanlı veri ağırlıklandırma ön-işleme yöntemi ile sınıflandırıcıların birleşiminden elde edilen sonuçlar...114 Tablo 6.31 VEP sinyali ile optik sinir hastalığı veri kümesinin
sınıflandırılmasında, benzerlik tabanlı veri ağırlıklandırma ön-işleme yöntemi ile sınıflandırıcıların birleşiminden elde edilen sonuçlar...115 Tablo 6.32 PERG sinyali ile Macular hastalığı veri kümesinin
sınıflandırılmasında, benzerlik tabanlı veri ağırlıklandırma ön-işleme yöntemi ile sınıflandırıcıların birleşiminden elde edilen sonuçlar...116 Tablo 6.33 Kalp hastalığı veri kümesinin sınıflandırılmasında, temel bileşen
analizi ile sınıflandırıcıların birleşiminden elde edilen sonuçlar...118 Tablo 6.34 E.coli promoter gen dizileri veri kümesin sınıflandırılmasında,
temel bileşen analizi ile sınıflandırıcıların birleşiminden elde edilen sonuçlar...118 Tablo 6.35 SPECT görüntüleri veri kümesinin sınıflandırılmasında,
temel bileşen analizi ile sınıflandırıcıların birleşiminden elde edilen sonuçlar...118 Tablo 6.36 Doppler sinyali ile damar sertliği veri kümesinin sınıflandırılmasında,
temel bileşen analizi ile sınıflandırıcıların birleşiminden elde edilen sonuçlar...118
Tablo 6.37 VEP sinyali ile optik sinir hastalığı veri kümesinin
sınıflandırılmasında, temel bileşen analizi ile sınıflandırıcıların
birleşiminden elde edilen sonuçlar...119 Tablo 6.38 PERG sinyali ile Macular hastalığı veri kümesinin sınıflandırılmasında,
temel bileşen analizi ile sınıflandırıcıların birleşiminden elde edilen sonuçlar...119 Tablo 6.39 Kalp hastalığı veri kümesinin sınıflandırılmasında,
f-skor özellik seçme ile sınıflandırıcıların birleşiminden elde edilen sonuçlar...120 Tablo 6.40 E.coli promoter gen dizileri veri kümesinin sınıflandırılmasında,
f-skor özellik seçme ile sınıflandırıcıların birleşiminden elde edilen sonuçlar...120 Tablo 6.41 SPECT görüntüleri veri kümesinin sınıflandırılmasında,
f-skor özellik seçme ile sınıflandırıcıların birleşiminden elde edilen sonuçlar...120 Tablo 6.42 Doppler sinyali ile damar sertliği veri kümesinin sınıflandırılmasında,
f-skor özellik seçme ile sınıflandırıcıların birleşiminden elde edilen sonuçlar...121 Tablo 6.43 VEP sinyali ile optik sinir hastalığı veri kümesinin
sınıflandırılmasında, f-skor özellik seçme ile sınıflandırıcıların
birleşiminden elde edilen sonuçlar...121 Tablo 6.44 PERG sinyali ile Macular hastalığı veri kümesinin
sınıflandırılmasında, f-skor özellik seçme ile sınıflandırıcıların
birleşiminden elde edilen sonuçlar...121 Tablo 6.45 Kalp hastalığı veri kümesinin sınıflandırılmasında,
Lineer kernel f-skor özellik seçme ile sınıflandırıcıların birleşiminden elde edilen sonuçlar...122 Tablo 6.46 E.coli promoter gen dizileri veri kümesinin sınıflandırılmasında,
Lineer kernel f-skor özellik seçme ile sınıflandırıcıların birleşiminden elde edilen sonuçlar...122 Tablo 6.47 SPECT görüntüleri veri kümesinin sınıflandırılmasında,
birleşiminden elde edilen sonuçlar...122 Tablo 6.48 Doppler siyali ile damar sertliği veri kümesinin sınıflandırılmasında,
Lineer kernel f-skor özellik seçme ile sınıflandırıcıların birleşiminden elde edilen sonuçlar...123 Tablo 6.49 VEP sinyali ile optik sinir hastalığı veri kümesinin
sınıflandırılmasında, Lineer kernel f-skor özellik seçme ile
sınıflandırıcıların birleşiminden elde edilen sonuçlar...123 Tablo 6.50 PERG sinyali ile Macular hastalığı veri kümesinin
sınıflandırılmasında, Lineer kernel f-skor özellik seçme ile
sınıflandırıcıların birleşiminden elde edilen sonuçlar...123 Tablo 6.51 Kalp hastalığı veri kümesinin sınıflandırılmasında,
RBF kernel f-skor özellik seçme ile sınıflandırıcıların birleşiminden elde edilen sonuçlar...124 Tablo 6.52 E.coli promoter gen dizileri veri kümesinin sınıflandırılmasında,
RBF kernel f-skor özellik seçme ile sınıflandırıcıların birleşiminden elde edilen sonuçlar...124 Tablo 6.53 SPECT görüntüleri veri kümesinin sınıflandırılmasında,
RBF kernel f-skor özellik seçme ile sınıflandırıcıların birleşiminden elde edilen sonuçlar...124 Tablo 6.54 Doppler siyali ile damar sertliği veri kümesinin sınıflandırılmasında,
RBF kernel f-skor özellik seçme ile sınıflandırıcıların birleşiminden elde edilen sonuçlar...125 Tablo 6.55 VEP sinyali ile optik sinir hastalığı veri kümesinin
sınıflandırılmasında, RBF kernel f-skor özellik seçme ile
sınıflandırıcıların birleşiminden elde edilen sonuçlar...125 Tablo 6.56 PERG sinyali ile Macular hastalığı veri kümesinin
sınıflandırılmasında, RBF kernel f-skor özellik seçme ile
sınıflandırıcıların birleşiminden elde edilen sonuçlar...125 Tablo 6.57 Kalp hastalığı veri kümesinin sınıflandırılmasında,
bilgi kazancına dayanan özellik seçme ile sınıflandırıcıların
birleşiminden elde edilen sonuçlar...126 Tablo 6.58 E.coli promoter gen dizileri veri kümesinin sınıflandırılmasında,
bilgi kazancına dayanan özellik seçme ile sınıflandırıcıların
birleşiminden elde edilen sonuçlar...127 Tablo 6.59 SPECT görüntüleri veri kümesinin sınıflandırılmasında,
bilgi kazancına dayanan özellik seçme ile sınıflandırıcıların
birleşiminden elde edilen sonuçlar...127 Tablo 6.60 VEP sinyali ile optik sinir hastalığı veri kümesinin
sınıflandırılmasında, bilgi kazancına dayanan özellik seçme ile
sınıflandırıcıların birleşiminden elde edilen sonuçlar...128 Tablo 6.61 PERG sinyali ile Macular hastalığı veri kümesinin
sınıflandırılmasında, bilgi kazancına dayanan özellik seçme ile
sınıflandırıcıların birleşiminden elde edilen sonuçlar...129 Tablo 6.62 Önerilen hibrid sistemler...130 Tablo 6.63 Medikal veri kümelerini sınıflandırılmasında en iyi sonucu elde
eden hibrid sistemler...131 Tablo 6.64 Kalp hastalığı veri kümesinin sınıflandırılmasında önerilen hibrid
sistemlerden elde edilen sınıflama doğrulukları...132 Tablo 6.65 E.coli promoter gen dizileri veri kümesinin sınıflandırılmasında
önerilen hibrid sistemlerden elde edilen sınıflama doğrulukları...133 Tablo 6.66 SPECT görüntüleri veri kümesinin sınıflandırılmasında
önerilen hibrid sistemlerden elde edilen sınıflama doğrulukları...134 Tablo 6.67 Doppler siyali ile damar sertliği veri kümesinin sınıflandırılmasında
önerilen hibrid sistemlerden elde edilen sınıflama doğrulukları...135 Tablo 6.68 VEP sinyali ile optik sinir hastalığı veri kümesinin
sınıflandırılmasında önerilen hibrid sistemlerden elde edilen sınıflama doğrulukları...136 Tablo 6.69 PERG sinyali ile Macular hastalığı veri kümesinin
sınıflandırılmasında önerilen hibrid sistemlerden elde edilen sınıflama doğrulukları...137
1. GİRİŞ
Veri ön-işleme, danışmanlı bir makine öğrenmesi algoritmasının performansını geliştirmede önemli bir etkiye sahiptir. Gürültülü örneklerin uzaklaştırılması, eksik veri, eksik özellik, aykırı değere sahip veri kümeleri, makine öğrenmesi algoritmalarında karşılaşılan en zor problemler arasındadır. Genel olarak, veri kümesinden uzaklaşan örnekler, birçok boş özellik değerine sahip olan ve oldukça ayrık olan örneklerdir. Eksik veriyi ele alma, veri hazırlama adımlarında sıklıkla ilgilenilen diğer bir konudur (Kotsiantis ve ark. 2006).
Medikal karar verme sistemleri için geliştirilen yöntemlerin bütünü genel olarak birkaç ayrık işlem parçalarına ayrılabilir: ön-işleme, özellik çıkarımı veya seçme ve sınıflama aşamalarıdır. Sinyal veya görüntü elde etme, artifakt (insan eliyle yapılan gürültü) ayıklama, ortalama, eşiklendirme, sinyal veya görüntü geliştirme ve kenar belirlemesi, ön-işleme kapsamında kullanılan temel operatörlerdir. İşaretler (sinyaller), özellik çıkarımı modülü tarafından işlenir. Özellik seçme modülü, özellik vektörünün sadece boyutta azaldığı isteğe göre seçilen bir konumdur. Sınıflandırma modülü, otomatik teşhiste son konumdur. Bu modül, giriş özellik vektörünü inceler ve kendi yapısına göre önerici bir hipotez oluşturur. (Kordylewski et al. 2001, Kwak ve ark. 2002, Güler ve ark. 2006).
Özellik, bir örüntünün parçalanmasında yapılan farklı veya karakteristik bir ölçüm, dönüşüm, yapısal bir bileşendir. Özellikler, önemli bilginin minimum kayıplı örüntülerini göstermek için kullanılır. Bir örüntüyü açıklamak için kullanılan bütün özellik kümesinden oluşan özellik vektörü, o örüntünün azaltılmış boyutlu bir gösterimidir. Bu durum, verilen bir örüntüyü açıklamak için kullanılan bütün özellik kümesinde gerçekten belirlenenlerle sınırlıdır anlamına gelir. Boyut azaltımının amacı, yazılım ve donanım kompleksliği, hesaplama maliyeti ve örüntü bilgisini sıkıştırabilme yeteneğindeki mühendislik sınırlamalarıyla karşılaşmaktır. Ayrıca, örüntü önemli özelliklerle gösterilip basitleştirilirse, sınıflama doğruluğu daha da artacaktır (Kordylewski et al. 2001, Kwak ve ark. 2002, West ve ark. 2000).
Gerçek dünya verilerinde, veri gösterimi, birçok özellik ile gösterilir fakat bunlardan birkaçı sadece hedef içerikle ilgili olabilir. Veri kümesindeki özelliklerin birbirleriyle ilişkili olması fazlalık olabilir. Böylece, veri kümesinin sınıflandırılmasında bütün özelliklerinin içerilmesine gerek yoktur (Guyon, 2003). Özellik alt küme seçimi, mümkün olduğu kadar verilerdeki ilgisiz ve gereksiz bilgi içerenleri tanımlama ve uzaklaştırma işlemidir. Bu işlem, verinin boyutunu azaltır ve öğrenme algoritmalarının daha hızlı ve daha verimli işlem yapmasına izin verebilir. (Kotsiantis ve ark. 2006).
Bu tez çalışmasındaki amaç, veri ön-işleme yöntemleri, boyut azaltımı veya özellik seçme yöntemleri ve sınıflama algoritmaları kullanılarak medikal verileri en iyi sınıflayan modeli bulmaktır. Kullanılan ve önerilen veri ön-işleme ve ağırlıklandırma yöntemleri, bulanık ağırlıklandırma ön-işleme, k-NN (k- en yakın komşu) tabanlı veri ağırlıklandırma ön-işleme, genelleştirilmiş ayrışım analizi (Kernel Fisher Ayrışım Analizi) ve Benzerlik Tabanlı Veri Ağırlıklandırma Ön-işleme yöntemleri kullanılmış ve önerilmiştir. Bu yöntemler arasında, özellik seçme olarak, bilgi kazancına dayanan özellik seçme algoritması ve Kernel F-skor özellik seçme yöntemleri kullanılmıştır. Boyut azaltımı olarak da temel bileşen analizi kullanılmıştır. Kullanılan medikal veri kümeleri özelliği belirlenmiş olanlar Kalp hastılığı veri kümesi, SPECT görüntüleri kalp hastalığı veri kümesi ve Promoter gen dizileri veri kümeleridir. Özelliği çıkarılmış olan medikal veri kümeleri ise Atherosclerosis (damar sertliği) veri kümesi, Macular hastalığı veri kümesi ve Optik Sinir hastalığı veri kümeleridir. Kullanılan medikal veri kümeleri, normal ve anormal (hasta) olmak üzere iki sınıfa sahiplerdir. Tez çalışmasında kullanılan örüntü tanıma sisteminin genelleştirilmiş blok diyagramı Şekil 1.1’ de verilmiştir.
Şekil 1.1 Tezde kullanılan örüntü tanıma sisteminin blok diyagramı
Bu blok diyagramı beş aşamadan oluşmaktadır. İlk aşamada, işlenecek veya özelliği çıkarılacak ham bir biyolojik sinyal kullanılmaktadır. Tez çalışmasında, Damar sertliğini tespit etmek için kullanılan Doppler sinyalleri biyolojik işaret olarak kullanılmıştır. Hasta ve sağlıklı kişilerden alınan bu Doppler sinyalleri zaman ekseninde kaydedildiği için özellik taşıyan bilgiler içinde gömülü bulunmaktadır. O yüzden bu sinyallerin spektrum analiz yöntemleri ile Dopppler sinyallerini zaman ekseninden frekans eksenine taşımak gerekir. Bu aşamada, hızlı Fourier dönüşümü (Welch yöntemi) kullanılarak zaman ekseninde alınmış Doppler sinyalleri frekans eksenine taşınarak bu sinyallerden özellikler çıkarılabilir. Tezde kullanılan diğer medikal veri kümelerine özellik çıkarımı işlemi uygulanmamıştır. Çünkü bu medikal
Ham biyolojik sinyal (Doppler sinyali)
Özellik Çıkarımı (Belirleme)
Hızlı Fourier Dönüşümü (Welch Yöntemi)
Özellik Seçme (Boyut Azaltımı)
a.Temel Bileşen Analizi b. Kernel F-skor Özellik Seçme
c. Bilgi Kazancı Tabanlı Özellik Seçme Veri Ağırlıklandırma ve ön-işleme yöntemleri a.Bulanık veri ağırlıklandırma veri ön-işleme b. k-NN tabanlı veri ağırlıklandırma veri ön-işleme c. Genelleştirilmiş ayrışım analizi (GAA) d. Benzerlik tabanlı veri ağırlıklandırma Sınıflama Algoritmaları a.ANFIS b. AIRS c. Fuzzy-AIRS d. C4.5 Karar Ağacı e. YSA
veri kümelerin özellikleri çıkarıldığı veya belli olduğundan bu veri kümelerine direk olarak Şekil 1.1’ de gösterilen diyagramdaki üçüncü aşamada kullanılan metodlar kullanıldı. Özellik seçme yöntemleri, veri kümelerinde bulunan ilgisiz ve gereksiz özellikleri uzaklaştırmak ve sınıflandırıcının hesaplama maliyetini azaltmak ve sınıflama performansını arttırmak için uygulanır. Dördüncü aşamada bulunan veri ağırlıklındırma ve ön-işleme yöntemleri, non-lineer veri dağılımına sahip medikal veri kümelerini lineer olarak ayrılabilir bir veriye dönüştürmek ve veri kümelerinde bulunan aykırı değerler ile gürültülü verileri ayıklamak için uygulanır. Son aşamada ise, çeşitli ön-işlemelerden geçmiş medikal veri kümelerini sınıflamak için çeşitli sınıflama algoritmaları kullanılmıştır.
Bu tez çalışmasındaki diğer bir amaç da, veri ön-işleme ve ağırlıklandırma yöntemleri ile özellik seçme yöntemlerinin, medikal veri kümelerini sınıflamada hangi veri kümelerinde iyi sonuç vereceğini bulmaktır ve bu sayede bir medikal veri kümesini sınıflamada kullanılacak uygun model belirlenmektedir. Veri ön-işleme teknikleri ve özellik seçme (boyut azaltımı) algoritmalarının performanslarını değerlendirmek için çeşitli sınıflama algoritmaları ile hibrid olarak kullanılmışlardır. Bu sınıflama algoritmaları, ANFIS (Adaptive Neuro-Fuzzy Inference System- Adaptif Sinirsel Bulanık Çıkarım Sistemi), C4.5 karar ağacı sınıflama algoritması, YBTS (Yapay Bağışıklık Tanıma Sistemi), bulanık mantık tabanlı kaynak dağılım mekanizmalı YBTS ve yapay sinir ağlarıdır. Veri ön-işleme teknikleri ve özellik seçme (boyut azaltımı) algoritmalarının performanslarını değerlendirmek için, sınıflama doğruluğu, hassasiyet ve açıklık değerleri ve ROC (Receiver Operating Characteristics) eğrisi altında kalan alan değerleri verilmiş ve bu değerlere göre mukayese edilmişlerdir. Veri ağırlıklandırma yöntemleri arasında en iyi sonuçları veren yöntem, k-NN tabanlı veri ağırlıklandırma ön-işleme yöntemidir. Özellik seçme veya boyut azaltımı yöntemleri arasında ise Temel Bileşen Analizi (TBA) diğer yöntemlere göre üstün sonuçlar sağlamıştır. Ayrıca, veri ağırlıklandırma ön-işleme yöntemleri, özellik seçme algoritmaları ve sınıflama algoritmaları birleştirilerek hibrid sistemler oluşturulmuş ve her bir medikal veri kümesi için en iyi hibrid sistem seçilmiştir.
1.1. Literatür Araştırması
Örüntü tanıma ve makine öğrenmesi alanında, veri ağırlıklandırma ve boyut azaltımı veya özellik seçme yöntemleri ile ilgili literatürde çok çeşitli çalışmalar mevcuttur. Bu yöntemler, biyomedikal veri sınıflama, kümele, yazı tanıma, el yazısı tanıma, yüz tanıma, parmak izi tanıma, anormal durum teşhisi gibi uygulamalarda kullanılmıştır. Veri ağırlıklandırma ve boyut azaltımı yöntemleri, sınıflama işleminden önce yapılan bir işlemdir. Lineer olmayan veri dağılımına sahip, eksik veri değere sahip olan ve özellikleri arasında lineer bir ilişki olan veri kümelerini daha kolay sınıflandırılabilir bir hale getirmek için veri ön-işleme tekniklerinin uygulaması gerekir. Bu sayede hem daha iyi sınıflama performansını elde edilebilir hem de hesaplama maliyeti azaltılabilir. Literatür araştırmasında, tezde kullanılanılan medikal veri kümelerinin sınıflaması, otomatik teşhis sistemleri, veri ağırlıklandırma ve boyut azaltımı veya özellik seçme yöntemleri ile ilgili yapılan çalışmalara yer verilmiştir.
İlk olarak, literatürde var olan yapay bağışıklık tabanlı sınıflayıcılar ve sistemler aşağıda özetlenmiştir.
Ağ tabanlı algoritmalar arasında dikkate değer bir diğer algoritma AIN (Artificial Immune Network) sistemidir. Wierzchon ve Kuzelevska (2001) tarafından oluşturulan AIN sisteminde de temel olarak AINE sistemi alınmış, AINE sistemindeki eşik seviyesi ve uyarım seviyesi hesablama yöntemi değiştirilmiştir. Oluşturulan sistem ile standart verilerde oldukça iyi sonuçlar elde edilmiştir. AIN sistemi ayrıca AINE ve aiNet sistemi ile de karşılaştırılmıştır.
De Castro ve Von Zuben (2001), veri analizi, tanıma ve sınıflandırma problemlerini çözmek için aiNet (Artificial Immune Network) adını verdikleri yapay bağışıklık ağ modelini geliştirmişlerdir. Bu sistemde amaç B hücreleri veya yapay tanıma toplarının yerine antikor popülasyonunu geliştirmektedir. AINE antijenlerin rasgele alt kümesini kullanırken aiNet antikor popülasyonunu rasgele seçmektedir. Daha sonra klonsal seçim ve mutasyon işlemi uygulamaktadır. Algoritma ağın dinamiklerini klonsal seçim ile kontrol etmektedir. aiNet’in performansı spir, chainlink ve 5-NLSC veri kümelerinde değerlendirmiştir.
Nasraoui ve ark. (2002) yapay tanıma topunu geliştirmek için eğitim veri kümesi üzerine bulanık küme uygulayarak bulanık tanıma topu kavramını önermişlerdir. Web kayıt dosyaları üzerinde kümeleme uygulamaları gerçekleştirmişlerdir. Klonlama aşamasını ve popülasyon boyunu kontrol ederek erken yakınsamadan kaçınmaya çalışmışlardır.
Mevcut kaynak sınırlamalı AINE sisteminde hala bir takım eksikliklerin ve dezavantajların bulunması nedeniyle AINE sistemi Knight ve Timmis (2001) tarafından yeniden ele alınmış mevcut eksiklikler giderilmeye çalışılmıştır. Söz konusu yenilikler algoritmadaki kaynak paylaşımı mekanizması ve işlemlerin yapılış sırası ile ilgili olarak gerçekleştirilmiştir. Yenilenmiş AINE algoritmasının performansını eskisi ile karşılaştırmak amacıyla eski AINE algoritmasının uygulandığı problemlerin hepsine yeni AINE algoritması uygulanarak sonuçlar analiz edilmiştir ve yapılan yeniliklerin performansı artırdığı gözlemlenmiştir.
Kalp hastalığı veri kümesinin sınıflamasında ve teşhisinde, literatürde aşağıdaki çalışmalar yapılmıştır.
El-Hanjouri ve ark. (2002), kalp sesleri kullanarak kalp hastalıklarının teşhisi
için bir teşhis sistemi önerdiler. Özellik çıkarımı için, dalgacık ayrışımı ve Mel-frekans cepstrum yöntemlerini kullandılar. Gizli Markov modeli kullanarak farklı kalp hastalıklarını sınıflandırdılar.
Yan ve ark. (2003), beş önemli kalp hastalığının teşhisi için bir karar destek sistemi geliştirmek için Çok Katmanlı Perseptron (ÇKP) sinir ağına dayanan hesaplamalı bir model önerdiler. Önerilen sistem üç katmandan oluşmaktadır. Sistemin giriş katmanı, geniş sayıda hasta durumundan belirlenen 38 giriş değişkeni içerir. Gizli katmandaki düğümlerin sayısı, kaskad bir öğrenme işlemiyle belirlenir. Çıkış katmanındaki 5 düğümün her biri, ilgili kalp hastalığından birisine uygundur. Önerilen karar destek sistemini, momentum oranlı, adaptif öğrenme oranı ve hatırlamalı mekanizmalarla donatılmış bir geri yayılım algoritmasıyla eğittiler. Deneysel sonuçlar, adapte edilen ÇKP tabanlı bir karar modeli, kalp hastalıklarının sınıflamasında yüksek doğruluk değerleri elde edildiğini göstermiştir.
Şahan ve ark. (2005), network (ağ) tabanlı yapay bağışıklık sistemlerinde sıklıkla kullanılan şekil uzay gösteriminde Euclidean mesafesinin hesaplamasınında karşılaşılan negatif etkileri uzaklaştırmak için Özellik Ağırlıklandırmalı Yapay
Bağışıklık Sistemi sınıflama algoritması önerdiler ve kalp hastalığı veri kümesine uyguladılar ve bu önerilen sistemle %82.59 sınıflama doğruluğu elde ettiler.
Zheng ve ark. (2006), beş önemli kalp hastalığının teşhisi için, ÇKP gruplamasına dayana komite (gruplama) makinalarını önerdiler. Özellikle, rastgele alt uzay ve bagging (gruplama yöntemi) yöntemlerini içeren iki gruplama yöntemi düşündüler. 352 örnekli kalp hastalığı veri tabanı, önerilen sistemlerin performanslarını değelendirmek için kullandılar. ÇKP gruplamalı komite makinaları, tek ÇKP’ dan daha iyi performans elde etmiştir.
Polat ve ark. (2006a), kalp hastalığını sınıflamak için bulanık mantık tabanlı veri ağırlıklandırma ön-işleme ile YBTS sınıflama algoritmalarını birleştirdiler ve 10 kat kez çaprazlama kullanılararak kalp hastalığı teşhisinde %96.30 sınıflama doğruluğu elde ettiler.
Polat ve ark. (2007), kalp hastalığını teşhis etmek için bilgi kazancına dayanan özellik seçme algoritması (BKÖS), bulanık ağırlıklandırma ön-işleme (BAÖ) ve yapay bağışıklık tanıma sistemlerine (YBTS) dayanan hibrid bir sistem önerdiler ve %50-50 eğitme ve test veri kümesi ayırımı ile %92.59 sınıflama doğruluğu elde ettiler.
Polat ve ark. (2007a), k-NN tabanlı veri ağırlıklandırma ön-işleme yöntemi, bulanık kaynak dağılım mekanizmalı YBTS sınıflama algoritması ile birleştirerek bir uzman sistem önerdiler ve kalp hastalığı veri kümesininin sınıflamasına uyguladılar. Oluşturdukları uzman sistemle %87 sınıflama doğruluğu elde ettiler.
Kahramanlı ve ark. (2008), yapay sinir ağları ile bulanık sinir ağlarını birleştiren hibrid bir sistem önerdiler ve kalp hastalığı teşhisi problemine uyguladılar. Bu hibrid sistemle %86. 80 sınıflama doğruluğu elde ettiler.
Özşen ve ark. (2008), yapay bağışıklık sınıflama sistemi tasarımında sistem birimleri arasındaki mesafeyi ve uygunluğu hesaplamak için çeşitli ölçüm kriterleri kullandılar ve bu oluşturdukları algoritmaları kalp hastalığı sınıflamasına uyguladılar. Kullandıkları mesafe ölçümleri, Euclidean mesafesi, Manhattan mesafesi ve hibrid benzerlik ölçümleridir. Elde edilen sınıflama doğrulukları, %83.21, %80.74% ve %83.95 sonuçlarını yukarıdaki ölçüm kriterleri ile elde edilmiştir.
E. coli promoter gen dizileri veri kümesinin sınıflandırılmasında literatürde aşağıdaki çalışmalar yapılmıştır.
Geoffrey G. Ve Towell ve ark. (1990), promoter gen dizileri veri kümesini oluşturmuşlar ve standart geri yayılım algoritması, O’ Neill, En yakın komşu ve ID3 algoritmaları kullanarak promoter gen dizilerini sınıflamışlardır. Yukarıdaki yöntemler kullanarak elde ettikleri sınıflama doğrulukları sırasıyla %92.45, %88.67, %87.73 ve %82.07’ dır.
Zhang ve ark. (2006), E.coli promoter’ u tahmin etmek için ileri beslemeli yapay sinir ağlarının gösterimini açıkladılar. Dizi korumuna göre, 60 tabanlı diziler, pozitif örnek olarak seçilirler ve E.coli kodlama alanlarından uygun non-promoterlar, negatif örnek olarak seçilirler ve daha sonra ileri beslemeli yapay sinir ağlarına dayanan sınıflayıcı eğitilir. Elde ettikleri sonuçlar, ileri beslemeli sinir ağları verimli bir şekilde promoterların istatiksel karakteristiklerini belirleyebileciğini gösterdiler.
Akdemir ve ark. (2007), promoter gen dizilerini sınıflamak için özellik seçme, bulanık ağırlıklandırma ön-işleme ve C4.5 karar ağacına dayanan hibrid bir sistem önerdiler. C4.5 karar ağacı, bulanık ağırlıklandırma ön-işleme ve C4.5 karar ağacınını birleşimi, özellik seçme ve C4.5 karar ağacınını birleşimi ve özellik seçme- bulanık ağırlıklandırma ön-işleme ve C4.5 karar ağacınını birleşimin elde edilen sınıflama sonuçları sırasıyla 70.08%, 88.88%, 76.82% ve 93.33’ dür.
Polat ve ark. (2007c), bilgi kazancına dayanan özellik seçme ve en az kareler destek vektör makinalarını kaskad birleştirerek promoter gen dizilerinin sınıflaması problemine uyguladılar ve 10 kat çapraz ile %100 sınıflama doğruluğu elde ettiler.
Polat ve ark. (2007d), bilgi kazancına dayanan özellik seçme ve Fuzzy-AIRS sınıflandırıcıyı birleştirerek yeni bir hibrid sistem önerdiler ve promoter gen dizilerinin sınıflamasına uyguladılar. Fuzzy-AIRS sınıflayıcı %50 doğruluk elde ederken, önerdikleri sistem %90 sınıflama başarısı elde etmiştir.
SPECT görüntüleri veri kümesinin sınıflandırılmasında literatürde aşağıdaki çalışmalar yapılmıştır.
Cios ve ark. (1996), SPECT (Single Photon Emission Computed Tomography) görüntülerini birkaç kategoride (normal, infarct, ischemia, infarct ve ischemia, reverse re-distribution, artifact ve equivocal) sınıflamak ve SPECT görüntülerini analiz etmek için yarı otomatik bir prosedür gerçekleştirdiler. Önerilen
prosedür, SPECT görüntülerinin incelenmesinde doktora yardımcı olan sistem iki adımdan oluşmaktadır. İlk adım, SPECT görüntülerini tekrar yapılandırır. Bu görüntüler, 16 bit çözünürlükle 64x64 piksellik parçalar içerir. Taranmış görüntüler, kenar belirleme, ilgili bölge ve segmantasyon teknikleri kullanılarak nümerik formata dönüştürülür. Her bir görüntüden, dikdörtgensel bölgeyi belirlemek için yeni bir algoritma geliştirdiler. İkinci adım, işlenen görüntüyü yedi sınıftan birine otomatik sınıflamayı içerir. Sınıflama işlemini gerçekleştirmek için, C4.5 karar ağacı, CLIP3 ve sınıflama kurallarını üretmek için bulanık modelleme kullanmışlardır.
Lukasz ve ark. (2001), CLIP3 makine öğrenmesi sınıflama algoritması kullanarak SPECT görüntülerinden kalp hastalığı teşhisinde %84 sınıflama doğruluğu elde ettiler.
Kurgan ve ark. (2002), CLIP4 makine öğrenmesi algoritması geliştirerek SPECT görüntülerinden kalp hastalığı tanısı problemine uyguladılar ve CLIP3’ ün elde ettiği sınıflama doğruluğunu geliştirdiler. CLIP4 algoritması ile %86.10 sınıflama doğruluğu elde ettiler.
Ümit ve ark. (2004), Radial Basis Function (RBF) yapay sinir ağları ve General Regression Neural Network (GRNN) algoritmaları kullanarak SPECT görüntülerinden kalp hastalığı teşhisinde 88.24% ve %93.58 sınıflama doğrulukları elde ettiler.
Polat ve ark. (2007b), Bağımsız Bileşen Analizi (BBA) ile YBTS’ yi birleştiren bir grup sınıflayıcı yöntemi önerdiler ve önerilen sistemi SPECT görüntüleri ile kalp hastalığı teşhis problemine uyguladılar. Elde ettikleri sınıflama doğruluğu %97.74 dür. Ayrıca çalışmalarında, BBA’ dan 3, 4 ve 5 özellikleri elde ederek YBTS ile birleştirerek önerilen sistemle karşılaştırdılar ve BBA(3-özellik)+YBTS sistemi %95.49 sınıflama doğruluğu elde ederken, BBA(4-özellik)+YBTS sistemi %96.99 sınıflama doğruluğu ve BBA(5-özellik)+YBTS sistemi ise %89.47 sınıflama doğrulukları elde ettiler.
Doppler sinyali ile damar sertliği veri kümesinin sınıflandırılması literatürde aşağıdaki çalışmalar yapılmıştır.
Dirgenali ve ark. (2006), Atherosclerosis hastalığının erken teşhisi için hibrid bir yöntem önerdiler. İlk olarak, Doppler sinyalinden özellik çıkarmak için AR (Autoregressive) modelleme uyguladılar. İkinci kısımda ise, elde edilen özellik
sayısını azaltmak için TBA özelliği çıkarılmış Doppler sinyali veri kümesine uyguladılar. Son aşamada ise, yeni oluştulmuş Doppler sinyali veri kümesini sınıflandırmak için YSA uyguladılar ve Atherosclerosis hastalığını %97 doğrulukla teşhis ettiler.
Polat ve ark. (2006b), YBTS sınıflama performansını arttırmak için bulanık kaynak dağılımı mekanizması önerdiler ve Atherosclerosis hastalığı teşhisine uyguladılar. İlk olarak, Doppler sinyaline FFT uygularak sinyalden özellik çıkarımı yaptılar. Daha sonra özelliği belirlenmiş Doppler sinyalini sınıflamak için YBTS ve Bulanık-YBTS uyguladılar ve sırasıyla %75 ve %100 sınıflama doğrulukları elde ettiler.
Ceylan ve ark. (2007), Atherosclerosis hastalığını sınıflamak için iki yaklaşım önerdiler. Bu yaklaşımlar, TBA ve kompleks değerli yapay sinir ağlarının birleşimi ve Bulanık Kümele Ortalama (BKO) ve kompleks değerli yapay sinir ağlarının birleşimidir. İlk önerilen sistemde, doppler sinyallerini sınıflamadan önce veri kümesine TBA uygulayarak yeni özellikli ve daha az boyutta Doppler sinyali veri kümesi elde ettiler ve sonra bu yeni oluşturulan veri kümesini kompleks değerli yapay sinir ağları ile sınıflandırdılar. İkinci önerdikleri çalışmada ise, BKO doppler sinyali veri kümesine uygulanarak veri azaltımı yaparak, veri sayısı azaltılmış Doppler sinyali veri kümesi kompleks değerli yapay sinir ağları ile sınıflandırdılar. 10 kat çaprazlama ile her iki çalışmada da %100 sınıflama doğruluğu elde ettiler.
Özşen ve ark. (2007), çalışmalarında yapay bağışıklık sisteminde yeni bir danışmalı sınıflama algoritması önerdiler ve bu yöntemi Atherosclerosis hastalığını teşhis etmek için Doppler sinyaline uyguladılar. İlk olarak, Doppler sinyalinden özellik çıkarmak için AR (Autoregressive) modelleme uyguladılar, daha sonra özelliği belirlenmiş olan Doppler sinyalini sınıflamak için Danışmalı Duyarlılık Olgunlaşma Algoritması (DDOA) kullanarak 10 kat çaprazlama ile %98.93 sınıflama doğruluğu elde ettiler.
Latifoğlu ve ark. (2007a), çalışmalarında, Yapay Bağışıklık Sistemine Dayanan Özellik Ağırlıklı Yapay Bağışıklık sistemi (AWAIS) ile gerçek dünya verisi olan Doppler sinyalinden Atherosclerosis hastalığını teşhis ettiler ve 10 kat çaprazlama ile %99.33 sınıflama başarısı elde ettiler.
Latifoğlu ve ark. (2007b), yapay bağışıklık tanıma sistemi kullanarak hasta ve normal kişiye ait doppler sinyali ile Atherosclerosis hastalığını teşhis etmişlerdir ve 10 kat çaprazlama ile %99.29 sınıflama doğruluğu elde etmişlerdir.
Özbay ve ark. (2007a), kompleks dağerli dalgacık yapay sinir ağları önerdiler ve yöntemlerini doppler sinyallerinin sınıflamasına uyguladılar. Doppler sinyalleri veri kümesi, sağlıklı ve Atherosclerosis hastalıklı kişilerin doppler sinyallerinin güç spektrum yoğunlukları oluşturulduktan sonra elde edilen özellik vektöründen oluşmaktaktadır. Bu önerilen sistem, Atherosclerosis hastalığını leave-one-out (birisi dışarıda kalan) çaprazlama ile %100 sınıflama doğruluğu elde etmişlerdir.
Özbay ve ark. (2007b), Doppler sinyallerini farklı pencere tiplerine sahip Fast Fourier Transform (FFT), Hilbert dönüşümü ve Welch yöntemiyle işlediler. Bu özellik çıkarımından sonra, kompleks değerli yapay sinir ağları ile Doppler sinyallerini sınıfladılar ve ön-işlemede (özellik çıkarımı) kullanılan pencere fonksiyonlarının sınıflamaya olan etkisini incelediler.
Kara ve ark. (2007a), çalışmalarında Doppler sinyallerine Ayrık Dalgacık Dönüşümü (ADD) uygulayarak sinyali ayrıştırdılar ve her bir ayrışan parçasına Welch yöntemi uygulayarak Doppler sinyalinden özellik çıkardılar. Bu işlemden sonra, elde edilen özellik vektörüne TBA uyguladılar ve Doppler sinyali veri kümesinin boyutunu azalttılar. TBA’ dan sonra, yeni elde edilen Doppler sinyaline yapay sinir ağları uygulayarak Atherosclerosis hastalığı ve sağlıklı kişi olarak Doppler sinyalini sınıflandırdılar.
Latifoğlu ve ark. (2008a), Atherosclerosis (damar sertliği) hastalığını teşhis etmek için FFT, TBA, k-NN tabanlı veri ağırlıklandırma ön-işleme ve YBTS ‘ ye dayanan hibrid bir sistem önerdiler ve Atherosclerosis hastalığının teşhisinde %100 sınıflama doğruluğu elde ettiler.
VEP sinyali ile optik sinir hastalığı veri kümesinin sınıflandırılması literatürde aşağıdaki çalışmalar yapılmıştır.
Kara ve ark. (2006), çalışmalarında PERG sinyallerinden optik sinir hastalığını sınıflamak için çok katmanlı yapay sinir ağlarını kullandılar. Optik sinir hastalığına sahip olan ile sağlıklı kişiye ait PERG sinyallerinin ayrımında %94.2 başarı oranı elde ettiler.
Kara ve ark. (2007b), pattern electroretinography (PERG-örüntü retinografisi) sinyallerinden TBA ile Macular ve optik sinir hastalığını tespit ettiler. Çalışmalarında, Macular hastalıklı PERG sinyalini ve optik sinir hastalıklı PERG sinyaline TBA uygulayarak bu sinyallerin birinci ve ikinci temel bileşenlerini incelediler ve birinci temel bileşenin bu iki hastalığın biririnden ayrılmasında kullanılabileceğini gösterdiler.
Kara ve ark. (2007c), PERG sinyallerinden optik sinir hastalığını teşhis etmek için Öğrenme Vektör Nicelemeli (ÖVN) yapay sinir ağlarını kullandılar. ÖVN li YSA ile elde edilen sınıflama başarısı %92 olarak elde ettiler.
Polat ve ark.(2008a), PERG sinyallerinden hem Macular hem de optik sinir hastalığını teşhisinde, en az kareler destek vektör makinaları, C4.5 karar ağaçları ve YBTS sınıflandırıcıları kullandılar ve karşılaştırdılar. 10 kat çaprazlama kullanılarak C4.5 karar ağacı, en az kareler destek vektör makinaları ve YBTS sınıflayıcılarından sırasıyla %85.9, %100 ve %81.82 sınıflama doğruluğu elde ettiler.
Güven ve ark. (2008), Visual Evoked Potentials (VEP-görsel uyarılmış potansiyeller) sinyallerinden optik sinir hastalığını teşhis etmede Genelleştirilmiş Ayrışım Analizi (GAA)’ nin sınıflandırma doğruluğu etkisini incelediler. Önerdikleri sistem iki aşamadan oluşmaktadır. İlk aşamada sınıflamadan önce, veri ön-işleme olarak VEP sinyallerine GAA uyguladılar. İkinci aşamada ise, GAA ile ayrışımı kolay hale getirilen VEP sinyallerini sınıflamak için C4.5 karar ağacı, yapay sinir ağları, YBTS, lineer ayrışım analizi ve destek vektör makinaları kullanıldı. GAA’ sız elde edilen sınıflama doğrulukları C4.5 karar ağacı, yapay sinir ağları, YBTS, lineer ayrışım analizi ve destek vektör makinaları sınıflama algortitmaları kullanılanılarak sırasıyla %84.37, %93.75, %75, %76.56% ve %53.125’ dir. GAA ön-işlemeli elde edilen sınıflama doğrulukları ise sırasıyla %93.75, %93.86, %81.25, %93.75 ve %93.75 oldu.
PERG sinyali ile Macular hastalığı veri kümesinin sınıflandırılması literatürde aşağıdaki çalışmalar yapılmıştır.
Güven ve ark. (2006), PERG sinyallerinden Macular hastalığını teşhis etmek için çok katman perseptronlu yapay sinir ağları kullandılar ve %98 sınıflama doğruluğu elde ettiler.
Polat ve ark. (2007e), Macular hastalığını sınıflamak için k-NN tabanlı veri ağırlıklandırma ön-işleme ve en az kareli destek vektör makinalarını birleştiren hibrid bir yöntem önerdiler. Ayrıca, k-NN tabanlı veri ağırlıklandırma ön-işlemedeki k değerinin sınıflamaya olan etkisi de incelendi ve k’ nın 10, 15 ve 20 değerleri için 10 kat çaprazlama ile %100 sınıflama doğruluğu elde ettiler. k-NN tabanlı veri ağırlıklandırma ön-işleme kullanılmadan elde edilen başarı ise %90.91 oldu.
Polat ve ark.(2008b), PERG sinyalerinden Macular hastalığını teşhis etmek için ön-işleme metodu olarak sınıfa bağımlı özellik seçme algoritması ve bulanık veri ağırlıklandırma ön-işleme yöntemlerini önerdiler ve C4.5 karar ağacı sınıflama algoritması ile birleştirdiler. Önerdikleri sistemin performansını ölçmek için 5, 10 ve 15 kat çaprazlama ile sınıflama doğruluğunu kullandılar. 5, 10 ve 15 kat çaprazlama ile %96.22, %96.27% ve %96.30 sınıflama doğrulukları elde ettiler.
Literatürde var olan diğer veri ön-işleme yöntemleri aşağıda özetlenmiştir. Baudat ve ark. (2000), kernel fonksiyon operatörü kullanarak non-lineer ayrışım analizi ile ilgilenmek için Genelleştirilmiş Ayrışım Analizi (Generalized Discriminant Analysis -GDA) olarak adlarılan yeni bir yöntem önerdiler. Temel olarak alınan teori, GDA giriş vektörlerini yüksek boyutlu özellik uzayında haritalamayı sağladığı için destek vektör makinalarına yakındır. Dönüştürülmüş uzayda, lineer özellikler giriş özelliğinin genişlemesini kolaylaştırır ve klasik lineer ayrışım analizini non-lineer ayrışım analizine genelleştirir. Bu formülasyon, bir özdeğer problem çözümü olarak açıklanabilir.
Birçok faktör, verilen bir görevde makine öğrenmesinin başarısını ektiler. Örnek verinin gösterimi ve kalitesi ilktir ve başta gelir. Gürültülü veya güvensiz bilgiyi gösteren çok fazla ilgisiz ve fazla bilgi varsa, eğitme sırasında bilgi keşfi çok zordur. Çok iyi biliniyor ki, veri hazırlama ve filtreleme adımları makine öğrenmesi problemlerinde oldukça yüksek bir zaman alır. Veri ön-işleme, veri temizleme, normalizasyon, veri dönüşümü, özellik çıkarımı ve özellik seçmeyi içerir. Kotsiantis ve ark. (2006), makine öğrenmesi problemlerinin çözümünde bu veri ön-işleme algoritmalarını incelemişlerdir.
Cao ve ark. (2007), sınıflandırma ve veri analizi için en ayırt edici ve bilgi verici özellikleri seçmek için bir kernel uzayında özellik seçme problemini gösterdiler. Bu problemi çözmede, özellik seçmek için ilk adım olarak kernel
uzayında temel bir küme oluşturdular. Bu küme kullanarak, birçok özelliğin bağımlı olduğu zaman bile etkisini kanıtlayan marjin tabanlı özellik seçme algoritmasını genişlettiler.
Son zamanlarda, non-lineer boyut azaltımına olan ilgi arttı. Bu, kompleks düşük boyutlu veriyle ilgilenme yeteneğine sahip olduğu iddaa edilen değişik yeni non-lineer tekniklerin önerilmesine neden oldu. Maaten ve ark. (2007), boyut azaltımı için on non-lineer tekniği incelediler. Yapay ve gerçek dünya verilerinde boyut azaltımı için bu non-lineer tekniklerin performanslarını incelediler ve iki temel lineer teknikle (Temel Bileşen Analizi ve Lineer Ayrışım Analizi) performanslarını karşılaştırdılar.
Tez çalışmasında, boyut azaltımı algoritmalarında temel bileşen analizi, bilgi kazancına dayanan özellik seçme ve Kernel F-skor özellik seçme algoritmaları kullanılmıştır. Veri ağırlıklandırma ve işleme için bulanık ağırlıklandırma ön-işleme, k-NN tabanlı veri ağırlıklandırma ön-ön-işleme, genelleştirilmiş ayrışım analizi ve benzerlik tabanlı veri ağırlıklandırma ön-işleme önerilmiş ve kullanılmıştır. Bu ön-işleme algoritmalarının biyomedikal verileri sınıflamada performanslarını görmek ve birbirleriyle karşılaştırmak için çeşitli sınıflama algoritmaları kullanılmıştır.
1.2. Çalışmanın Temel Amacı ve Literatüre Katkıları
Bu çalışmanın amacı, özelliği belirlenmiş ve özelliği çıkarılmış olan biyomedikal verileri; sınıflamak, sınıflama performasınlarını geliştirmek için çeşitli veri ön-işleme ve boyut azaltımı (veya özellik seçme) algoritmaları geliştirmek ve bu yöntemler kullanılarak en iyi hibrid sistemi bulmaktır.
Medikal hastalıkları sınıflandırırken hastalığı belirten veya açıklayan bir veri kümesine ihtiyaç vardır. Bu veri kümesi de hasta ve normal (sağlıklı) kişilerden alınan sinyaller, görüntüler, klinik veriler, laboratuvar sonuçlarından oluşabilir. Oluşturulan bu medikal veri kümesi, hasta ve normal kişi verilerinin birbirine karıştığı ve ayırt edilmesi zor bir durum olabilir. Bu duruma sahip olan veri kümelerine non-lineer veri kümeleri denilmektedir. Non-lineer dağılıma sahip olan veri kümelerini sınıflamak için veri ağırlıklandırma (ön-işleme) ve boyut azaltımı