Analysis of serial production lines: Characterisation study and a new heuristic procedure for optimal buffer allocation
Tam metin
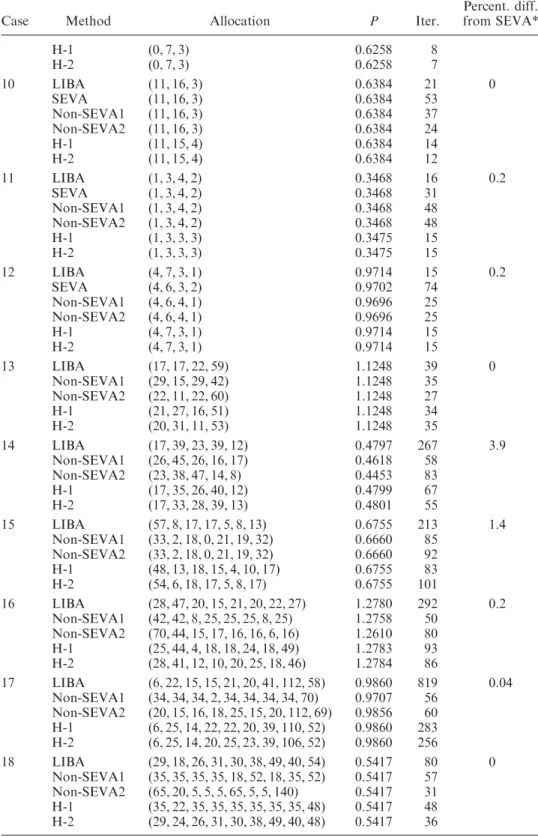
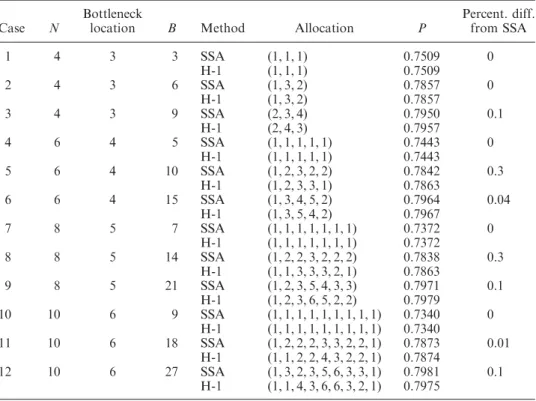
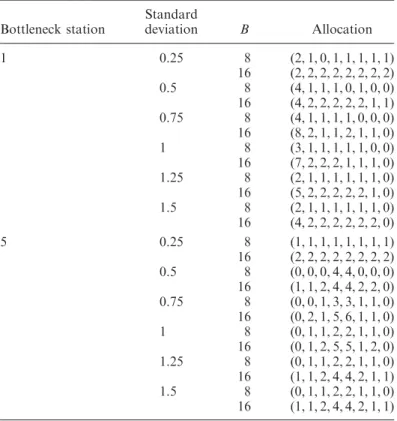
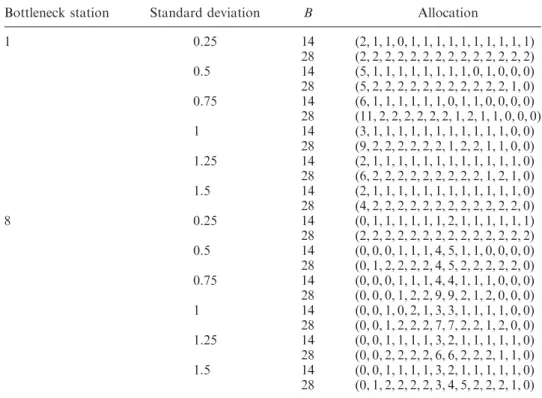
Şekil


Benzer Belgeler
The three source languages, CQL, StreamIt, and Sawzall, oc- cupy three diverse points in the design space for streaming lan- guages and the benchmark applications exercise
Bu sonuç, kamu sektörün- deki çalışanların özellikle çeşitli internet filtreleme ve izleme uygulamalarının olması ya da buna yönelik güçlü bir algının var olması
Model sonuçlarına göre gerek makroekonomik problemler (enflasyon ve faiz oranlarının artması, TL’nin değer kaybetmesi) gerekse de bankacılık sektörünün sorunları
Bi rinci bölümde, “cinsiyet, mesleki deneyim, mezun oldu ğu okul, hizmetiçi eğitime katılma durumu, geçirdikleri teftiş sayısı” ile ilgili kişisel bilgiler
The AR, ORL, and Yale face databases are used in ex- perimental studies, which indicate that recognition rates obtained by the 2-D mel-cepstrum method are superior to the
Our approach is similar to the one used in (Morgül, 2009), where only one dimensional discrete time chaotic systems were considered.. This paper is organized
one-tick market. Observing one-tick price changes virtually all of the time is not surprising given the dominance of one-tick spreads in the data. A one-tick change means an even
We hypothesize that if target text is a (meaningful) translation of source text, then the clustering structures C s (source) and C t (target) should have a meaningful similarity,
