CROSSLINGUISTIC ANALYSIS OF LEXICAL BUNDLES IN L1
ENGLISH, L2 ENGLISH, AND L1 TURKISH RESEARCH
ARTICLES
FATİH GÜNGÖR
DOCTORAL DISSERTATION
ENGLISH LANGUAGE TEACHING DEPARTMENT
GAZI UNIVERSITY
GRADUATE SCHOOL OF EDUCATIONAL SCIENCES
i
TELİF HAKKI VE TEZ FOTOKOPİ İZİN FORMU
Bu tezin tüm hakları saklıdır. Kaynak göstermek koşuluyla tezin teslim tarihinden itibaren 12 ay sonra tezden fotokopi çekilebilir.
YAZARIN
Adı : Fatih
Soyadı : GÜNGÖR
Bölümü : İngiliz Dili Eğitimi
İmza :
Teslim tarihi :
TEZİN
Türkçe Adı : Ana dil İngilizce, ikinci dil İngilizce ve birinci dil Türkçe araştırma makalelerindeki çok sözcüklü birimlerin diller arası karşılaştırmalı analizi
İngilizce Adı: Crosslinguistic analysis of lexical bundles in L1 English, L2 English, and L1 Turkish research articles
ii
ETİK İLKELERE UYGUNLUK BEYANI
Tez yazma sürecinde bilimsel ve etik ilkelere uyduğumu, yararlandığım tüm kaynakları kaynak gösterme ilkelerine uygun olarak kaynakçada belirttiğimi ve bu bölümler dışındaki tüm ifadelerin şahsıma ait olduğunu beyan ederim.
Yazar Adı Soyadı: Fatih GÜNGÖR İmza:
iii
JÜRİ ONAY SAYFASI
Fatih GÜNGÖR tarafından hazırlanan “Crosslinguistic analysis of lexical bundles in L1 English, L2 English, and L1 Turkish research articles” adlı tez çalışması aşağıdaki jüri tarafından oy birliği / oy çokluğu ile Gazi Üniversitesi İngiliz Dili Eğitimi Anabilim Dalı’nda Doktora tezi olarak kabul edilmiştir.
Danışman: Doç. Dr. Hacer Hande UYSAL
İngiliz Dili Eğitimi Ana Bilim Dalı, Gazi Üniversitesi ……….
Başkan: Prof. Dr. İsmail Hakkı ERTEN
İngiliz Dili Eğitimi Ana Bilim Dalı, Hacettepe Üniversitesi ………. Üye: Doç. Dr. Cem BALÇIKANLI
İngiliz Dili Eğitimi Ana Bilim Dalı, Gazi Üniversitesi ……….
Üye: Doç. Dr. Kadriye Dilek AKPINAR
İngiliz Dili Eğitimi Ana Bilim Dalı, Gazi Üniversitesi ………
Üye: Yrd. Doç. Dr. Olcay SERT
İngiliz Dili Eğitimi Ana Bilim Dalı, Hacettepe Üniversitesi ………..
Tez Savunma Tarihi: 07/10/2016
Bu tezin İngiliz Dili Eğitimi Anabilim Dalı’nda Doktora tezi olması için şartları yerine getirdiğini onaylıyorum.
Unvan Adı Soyadı: Prof. Dr. Ülkü ESER ÜNALDI
iv
ACKNOWLEDGEMENTS
First, I would like to express the deepest appreciation to my advisor, Assoc. Prof. Dr. Hacer Hande Uysal. It would not be possible to finish this dissertation without her expertise, understanding, helpful guidance and continuous support.
I would like to thank my dissertation committee members, Assoc. Prof. Dr. Cem Balçıkanlı and Assist. Prof. Dr. Olcay Sert. They have broadened my perspective on crosslinguistic influence and corpus linguistics with their distinguished suggestions. I also would like to thank Dr. Philip Durrant. In my last three months of the dissertation writing process at University of Exeter, he has provided invaluable insight in his field of expertise and continuous encouragement at least as much as the committee members.
I cannot thank my parents, Recep Güngör and Fahriye Güngör, enough who have encouraged furthering my studies. My mother, who passed away suddenly four years ago, has always been an inspiration and motivation source to finish my doctoral degree. My brother, Murat Güngör, gave his time listening to my concerns in both academic and personal life. I also owe special thanks to Zeynep Altın for her continuous support in Turkey and United Kingdom. She has shared my happiness and sorrow since the day I have met her.
I would like to thank my colleagues from different universities for their help and support: Prof. Dr. Murat Peker, Assist. Prof. Dr. Ahmet Yamaç, Res. Asst. Erhan Ünal and Res. Asst. Ahmet Murat Uzun.
I also thank TÜBİTAK (The Scientific and Technological Research Council of Turkey) for their grant to me as the researcher to develop my dissertation at University of Exeter, United Kingdom for three months (see Appendix 7).
v
CROSSLINGUISTIC ANALYSIS OF LEXICAL BUNDLES IN L1
ENGLISH, L2 ENGLISH, AND L1 TURKISH RESEARCH
ARTICLES
(Doctoral Dissertation)
Fatih GÜNGÖR
GAZI UNIVERSITY
GRADUATE SCHOOL OF EDUCATIONAL SCIENCES
October 2016
ABSTRACT
The present study was set out to analyze the four-word lexical bundles in terms of the potential crosslinguistic influence between L2 English, namely interlanguage, and L1 Turkish, namely native language, of Turkish authors and has identified the frequencies, structures and functions of the lexical bundles in L1 English, L2 English and L1 Turkish research articles. A three-million-word specialized research article corpus was designed, having one million words for each language variable. The lexical bundle analyses yielded 79 four-word lexical bundles for the MCRA-L1 and 119 four-word lexical bundles for the MCRA-L2 with the cut-off criteria of 20 frequency of occurrence per million words and dispersion in at least 10% of the research articles. In addition to the frequency analyses, lexical bundles were classified structurally and functionally. While the majority (81%) of lexical bundles in the native academic writing was constructed with noun and prepositional structures, namely phrasal structures, the Turkish authors heavily used (44%) verb based structures, namely clausal structures, in their research articles. On the other hand, the research-oriented bundles were the most frequently used function category by the Anglo-American authors while the Turkish authors used the text-oriented bundles significantly more than any other category. Following these analyses, the potential crosslinguistic influence was scrutinized through the detection-based approach, and the
vi
three types of evidence (intralingual homogeneity, interlingual heterogeneity and crosslinguistic performance congruity) were examined to assert the crosslinguistic influence. This detection-based approach revealed that the Turkish authors were likely to transfer 54 of 119 bundles from their native language, Turkish, to English. Furthermore, the Turkish authors, to a great extent, transferred the clausal structures that function as inferential, procedure and comparative bundles. These findings are expected to present a number of suggestions to less proficient writers, writing instructors, material designers and researchers on the achievement of native-like academic writing.
Keywords : Academic writing, English for academic purposes, research article genre, lexical bundles, register analysis, interlanguage development, crosslinguistic influence.
Page Number : 207
vii
ANA DİL İNGİLİZCE, İKİNCİ DİL İNGİLİZCE VE BİRİNCİ DİL
TÜRKÇE ARAŞTIRMA MAKALELERİNDEKİ ÇOK SÖZCÜKLÜ
BİRİMLERİN DİLLER ARASI KARŞILAŞTIRMALI ANALİZİ
(Doktora Tezi)
Fatih GÜNGÖR
GAZİ ÜNİVERSİTESİ
EĞİTİM BİLİMLERİ ENSTİTÜSÜ
Ekim 2016
ÖZ
Bu çalışma dört kelimeli sözcüksel birimleri ikinci dil İngilizce, yani aradil, ve Türkçe, yani ana dil, arasındaki olası diller arası etkisini incelemeyi ve anadil İngilizce, aradil İngilizce ve anadil Türkçe araştırma makalelerindeki çok sözcüklü birimlerin yapılarını ve işlevlerini tespit etmeyi hedeflemiştir. Her bir dil değişkeni için bir milyon kelimeyi içeren 3 milyon kelimelik özgün bir derlem tasarlanmıştır. Çok sözcüklü birim analizleri, bir milyon kelimede 20 rastlama sıklığı ve araştırma makalelerinin %10’una dağılım kıstasları ile anadil İngilizce olan derlem için 79 dört kelimeli sözcüksel birim ve aradili İngilizce olan derlem için 119 dört kelimeli sözcükler birim ortaya koymuştur. Bu sıklık analizlerinin yanı sıra, çok sözcüklü birimler yapısal ve işlevsel açıdan da sınıflanmıştır. Anadil akademik yazında çok sözcüklü birimlerin büyük çoğunluğu (%81) isim ya da edat yapıları yani öbek yapılar kullanırken Türk yazarlar çoğunlukla (%44) fiil merkezli yani tümce yapıları kullanmıştır. Diğer bir yandan araştırma odaklı çok sözcüklü birimler Anglo-Amerikan yazarlar tarafından en çok kullanılan işlev kategorisi iken Türk yazarlar metin odaklı çok sözcüklü birimleri diğer herhangi bir kategoriden belirgin derecede fazla kullanmıştır. Bu analizler sonrasında olası diller arası etki tespit odaklı yaklaşım yoluyla irdelenmiş ve diller arası etkiyi ileri sürebilmek için üç tür delil (dil içi türdeşlik, diller arası çok türellik ve diller arası edim eşleşim) incelenmiştir. Bu tespit odaklı yaklaşım, Türk yazarların kullandığı 119 çok sözcüklü birimin 54 tanesini ana dilleri olan Türkçe’den İngilizce’ye aktarmalarının olası olduğunu ortaya koymuştur. Dahası, Türk yazarlar büyük ölçüde çıkarımsal, yöntem ve karşılaştırma birimleri işlev gören tümce yapıları transfer etmiştir. Bu bulguların, ana dil kadar iyi akademik yazmanın başarılması
viii
hususunda yeterli derecede uzman olmayan yazarlara, yazma öğreticilerine, materyal tasarımcılarına ve araştırmacılara bir dizi öneriler sunması beklenmektedir.
Anahtar Kelimeler : Akademik yazma, akademik amaçlar için İngilizce, araştırma makalesi türü, çok sözcüklü birimler, kesit analizi, aradil gelişimi, diller arası etki.
Sayfa Adedi : 207
ix
TABLE OF CONTENTS
ABSTRACT ... v
ÖZ……... vii
TABLE OF CONTENTS ... ix
LIST OF TABLES ... xi
LIST OF FIGURES ... xiii
LIST OF ABBREVIATIONS ... xiv
CHAPTER 1 ... 1
INTRODUCTION ... 1
Background to the Study ...1
Significance of the Study ...8
Purpose and Scope of the Study ... 12
Limitations of the Study ... 13
Definitions of Some Key Concepts... 14
CHAPTER 2 ... 16
REVIEW OF LITERATURE ... 16
Lexical Bundles ... 19
Lexical Bundles and Academic Discourse ... 24
Lexical Bundles in Language Teaching and Learning ... 27
Crosslinguistic Influence on Lexical Bundles ... 32
Major Relevant Studies on Lexical Bundles ... 33
CHAPTER 3 ... 45
METHOD.. ... 45
x
Data: The Multilingual Corpus of Research Articles (MCRA) ... 48
Identifying the Lexical Bundles ... 51
Descriptive Statistics of the Lexical Bundles ... 52
Structural Taxonomy of the Lexical Bundles ... 53
Functional Taxonomy of the Lexical Bundles ... 54
A Quest for Crosslinguistic Influence ... 57
CHAPTER 4 ... 63
RESULTS AND DISCUSSION ... 63
Frequencies of Lexical Bundles in MCRA-L1 and MCRA-L2 ... 63
Structural Characteristics of Lexical Bundles in MCRA-L1 and MCRA-L2 ... 75
Functional Characteristics of Lexical Bundles in MCRA-L1 and MCRA-L2 ... 86
Research-oriented Lexical Bundles ... 91
Text-oriented Lexical Bundles ... 99
Participant-oriented Lexical Bundles ... 112
Potential Crosslinguistic Influence for Lexical Bundles ... 115
Intragroup Homogeneity ... 116
Intergroup Heterogeneity ... 117
Crosslinguistic Performance Congruity ... 119
CHAPTER 5 ... 146
CONCLUSION AND IMPLICATIONS ... 146
Pedagogical Implications ... 150
REFERENCES ... 152
xi
LIST OF TABLES
Table 1. The Frequency and Dispersion Criteria of the Some Previous Studies ... 20
Table 2. Structural Taxonomy... 21
Table 3. Functional Classification of Lexical Bundles ... 22
Table 4. Functional Classification of Lexical Bundles ... 23
Table 5. The Corpus Statistics ... 51
Table 6. The Structural Taxonomy in the Present Study ... 53
Table 7. Research-oriented Bundles ... 55
Table 8. Participant-oriented bundles ... 55
Table 9. Text-oriented Bundles ... 56
Table 10. The Most Frequent 50 Lexical Bundles in the MCRA-L1 ... 64
Table 11. The Comparison of the MCRA-L1 Results with the Results of Other Studies (The Most Frequent 50 Bundles)... 65
Table 12. The Most Frequent 50 Lexical Bundles in the MCRA-L2 ... 68
Table 13. The Comparison of the MCRA-L2 Results with the Results of Other Studies (The Most Frequent 50 Bundles)... 69
Table 14. Log-likelihood and Effect Size Results of the Shared Bundles ... 72
Table 15. Structural Classification of the Lexical Bundles in the MCRA-L1 and the MCRA-L2 ... 76
Table 16. Prepositional Phrase Fragments in the MCRA-L1 ... 80
xii
Table 18. Noun Structures in the MCRA-L1 ... 81
Table 19. Noun Structures in the MCRA-L2 ... 82
Table 20. Verb Based Structures in the MCRA-L2 ... 843
Table 21. Verb Based Structures in the MCRA-L1 ... 834
Table 22. Functional Classification of the Lexical Bundles in the MCRA-L1 and the MCRA-L2 ... 87
Table 23. Research-oriented Bundles in the MCRA-L1 ... 92
Table 24. Research-oriented Bundles in the MCRA-L2 ... 92
Table 25. Text-oriented Bundles in the MCRA-L1 ... 99
Table 26. Text-oriented Bundles in the MCRA-L2 ... 100
Table 27. Frequency Comparison of Clausal Inferential Bundles with COCA and BNC ... 104
Table 28. Participant-oriented Bundles in the MCRA-L1 ... 112
Table 29. Participant-oriented Bundles in the MCRA-L2 ... 112
Table 30. Structural Classification of the Lexical Bundles in the MCRA-L2 and the Distinctive Bundles by Turkish Authors ... 120
Table 31. Functional Classification of the Lexical Bundles in the MCRA-L2 and the Distinctive Bundles by Turkish Authors ... 121
Table 32. The Inferential Bundles Distinctive to Turkish Authors ... ………122
Table 33. The Procedure Bundles Distinctive to Turkish Authors ... 127
Table 34. The Comparative Bundles Distinctive to Turkish Authors ... 132
Table 35. The Structuring Bundles Distinctive to Turkish Authors ... 136
Table 36. The Framing Bundles Distinctive to Turkish Authors ... 138
xiii
LIST OF FIGURES
Figure 1. Distributional categories... 18
Figure 2. Core components of learner corpus research ... 28
Figure 3. The use of corpora in language learning and language teaching ... 30
Figure 4. The contrastive analysis of L1 English, L2 English and L1 Turkish research articles ... 46
Figure 5. A sample from the organization of the research articles in the corpus ... 50
Figure 6. Three types of evidence to assert a crosslinguistic influence ... 59
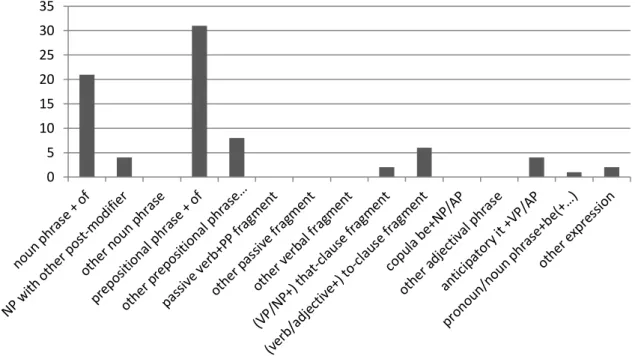
Figure 7. Distribution of structural types in the MCRA-L1 ... 77
Figure 8. Distribution of structural tokens in the MCRA-L1 ... 77
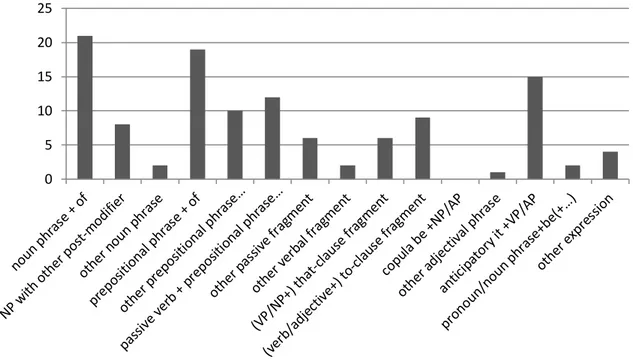
Figure 9. Distribution of structural types in the MCRA-L2 ... 78
Figure 10. Distribution of structural tokens in the MCRA-L2 ... 78
Figure 11. Distribution of functional types in the MCRA-L1 ... 88
Figure 12. Distribution of functional tokens in the MCRA-L1 ... 88
Figure 13. Distribution of functional types in the MCRA-L2 ... 89
xiv
LIST OF ABBREVIATIONS
L1 Native language
NL Native language
L2 Second language, target language
IL Interlanguage
TL Target language
CA Contrastive analysis
CIA Contrastive interlanguage analysis MCRA Multilingual Corpus of Research Articles
MCRA-L1 Subcorpus of English research articles by the Anglo-American researchers MCRA-L2 Subcorpus of English research articles by the Turkish authors
1
CHAPTER 1
INTRODUCTION
This chapter provides a brief description of the theoretical background for the present study. After the significance of this study is elaborated, the research questions are given in the purpose and scope of the study sections. Then, some possible limitations of the study are noted down. Lastly, some basic definitions are given to make the study more comprehendible for any reader.
Background to the Study
For about seven decades, the language transfer phenomenon has been one of the most prominent subjects in second language research. Since 1945, researchers have been continuously scrutinizing the role of native language (L1) in learning second language (L2) (Gass, Behney, & Plonsky, 2013), and the great number of books and articles in the field has indicated the strong effect of cross-linguistic influence on language learning (Odlin, 2003). Crosslinguistic influence is an important issue as no theories in L2 acquisition could start without considering the prior linguistic knowledge of learners (Ellis, 2008). For example, research trends in contrastive analysis and interlanguage, which focused on the role of L1 influence on second language learning, have arisen out of the insight of C. C. Fries (1945) and his colleague, Lado (1957). C. C. Fries was a linguist who was always interested in teaching English both to native and non-native speakers, and Lado was a Spanish-English bilingual who was well aware of the effect of crosslinguistic and cultural differences on
2
language learning. These two expert linguists grew up under the influence of Bloomfield’s structuralism, and they came across at Michigan School. Due to the increasing interest in language learning after World War II, the main concern of C. C. Fries and Lado became to describe how the best teaching materials should be like (Selinker, 2013), and this inspiration led to the application of Bloomfield’s ideas to the teaching in the United States of America (Lennon, 2008). According to Bloomfield (1933), the structure of the language should be examined in three sublevels: phonology, morphology and syntax. Based on Bloomfield’s rule-governed system, Fries (1945, p. 9) described the most efficient teaching materials as the ones “that are based upon a scientific description of the language to be learned, carefully compared with a parallel description of the native language of the learner”, and Lado (1957, p. 2) established links with this statement by adding that “individuals tend to transfer the forms and meanings, and the distribution of forms and meanings of their native language and culture to the foreign language and culture”. These views ended up with the birth of a new method for language teaching: Audio-lingual method or the Michigan method. In other words, contrastive analysis and behaviorist psychology yielded a new method which makes use of the imitation of spoken language, repetition and drills. However, in behaviorism, interference from previous knowledge was thought to be hurdle for learning (Ellis, 2008), and the main emphasis of researchers was to find differences and similarities between learners’ native language and target language in its traditional way, through contrastive phonology and contrastive grammar. To clarify the issue from Lado’s perspective (1957), the assumption was that learners would find it difficult to learn the structures different from their native language, and they would find it easy to learn the structures that are similar to their native language.
For a long time, the discussions on the error analysis had prevailed in the field of language learning. Although Stephen Pit Corder (1967) attempted to revive error analysis through focusing on the cognitive contribution of error analysis for learning, contrastive analysis or error analysis was criticized harshly in the following years. For instance, Schachter (1974) found an error in error analysis that learners could avoid using some structures, and, in turn, this might become a handicap for the detection of errors. Furthermore, language learners, whatever their native languages are, tend to make developmental errors. Therefore, contrastive analysis was not very successful in terms of the prediction of errors except for the identification of phonological errors. Considering these flaws, researchers understood that intralingual, interlingual and some other factors such as psychological and sociocultural
3
setting might cause learners to make errors, and language transfer was not simply considered as a contrastive analysis of language universals. Hence, the main focus should have been not only to explore errors but also to describe a language as a whole (Lennon, 2008).
The criticisms mentioned above induced the researchers in the field to think again and build further on the error analysis. Considering that language transfer was not necessarily made up of making errors in a second or foreign language (Selinker, 2013), Selinker (1969) coined a new term “interlanguage” (IL) through brainstorming with Corder and other researchers in the field, and opened up new doors for transfer research. According to Selinker, interlanguage is an independent language system which is influenced by L1, L2 and IL of language learners. In addition to the utterances in native language and target language, interlanguage behavior should also be analyzed to study psycholinguistic processes in language transfer (Selinker, 1972). The five central processes which exist in the latent psychological structure of Selinker are language transfer, transfer-of-training, strategies of second language learning, strategies of second language communication, and overgeneralization of target language linguistic material (Selinker, 1972). Fossilization, with some other factors such as markedness and strategies, might also play a significant role for the tendency of learners to produce IL due to the provided instruction series. Interlanguage (IL) deals with lexical, pragmatic, and discourse level issues coupled with phonology, morphology, and syntax which were sole focus of contrastive analysis (Tarone, 2010). Among these, morphology, syntax, and the lexicon are the structures which Scovel (1988) assumed to develop up to the target language norms. Recently, there have been also some studies which attempt to measure interlanguage by identifying native language, namely language transfer with the terms of Odlin (1989), through L1-influence metrics (e.g. Brooke & Hirst, 2012). Although interlanguage research still investigates phonology, morphology, syntax, and lexis, it also touches upon the psycholinguistic and sociolinguistic aspects of language.
Over the past four decades, many researchers contributed to the knowledge about L1 influence, and the field has been having its state-of-art days since 1990s (Ellis, 1994). For instance, Ringbom (1987, 1992) argued for the facilitating effect of positive transfer in his research. Also, the advances in technology and data-driven learning led to the expansion of the field with corpus studies. The establishment of corpora and new native language identification (NLI) techniques gave way to a new area of research (Jarvis & Paquot, 2015),
4
and this area has been concerned with the interaction between computers and human languages as can be seen in the study of Tsur and Rappoport (2007, June) and in the detection-based approach of Jarvis (2000, 2010, 2012). Probably, the other reasons behind this conspicuous growth of interest in L1 influence is the remaining confusion in the field and multifaceted nature of L1 influence, but whatever the backstage reasons are, cross-linguistic influence and transfer research keep its prominence in language learning and teaching research even if the research has changed its direction (Jarvis, 2000; Odlin, 2003). In addition to a great number of investigations on cross-linguistic influence with a focus on grammar, over the past four decades, the tendency has currently been shifting to lexical transfer (Jarvis, Castaneda-Jiménez, & Nielsen, 2012) with the effect of growing interest in phraseology research (Biber, 2009) and the significant role of phraseology in the development of L2 writing (Bestgen & Granger, 2014). According to the researchers in the field, the knowledge of multi-word units helps learners develop their writing skills (Li & Schmitt, 2009), and sound as native users of L2 (Allen, 2010; Hyland, 2008a; Li & Schmitt, 2009). Conversely, the lack of knowledge in multi-word units has been considered to cause non-native feeling in their writing (Li & Schmitt, 2009), lack of fluency (Hyland, 2008b) and communication breakdowns (Millar, 2009). Following this tendency, multi-word units have been studied in order to understand the interaction of languages a person knows, which is basically aim of the transfer research (Jarvis & Pavlenko, 2008), and researchers in the field have recently focused largely on lexical transfer, probably an outstanding one among the types of transfer research (Jarvis, Jimenez, & Nielsen, 2012).
Phraseology, which is pervasive in both oral and written communication (Granger & Meunier, 2008), plays a critical role in the teaching of academic writing in English as a foreign language (EFL) classes (Nattinger & DeCarrico, 1992). L1 lexical phrases are proven to be learned gradually as wholes, and a proficient language user has knowledge of a great number of multi-word units (Ellis, 2008; Li & Schmitt, 2009). Therefore, EFL learners frequently refer to the L1 lexicon for multi-word lexical collocations, multi-word units, and lexicogrammatical patterns (Paquot, 2013), and they experience difficulties in L2 about collocational patterning, discourse characteristics, and pragmatic appropriacy (Flowerdew, 2001). Obviously, it would not be reasonable to attribute all uses in target language to an L1 model; however, the specific lexical patterning of the learners who have the same L1 background indicate as a matter of fact that L1 may have an effect in the
5
acquisition of lexical items (Jarvis, 2012), and many such studies on lexical transfer give ideas about the word choices of learners (Jarvis, Jimenez, & Nielsen, 2012). Paquot (2013) also suggests that the examination of words in isolation will reveal the choices of multi-word sequences in particular L1 backgrounds.
The increasing interest on multi-word units over the last fifteen years (Allen, 2010) as markers of register, genre and discipline should be regarded a central concern of academic discourse which is worth examining for each member of a specific discourse community (Allen, 2010; Biber, 2006; Salazar, 2014). With the role of multi-word units in data-driven learning (Johns, 1991), many studies (Biber & Barbieri, 2007; Biber, Conrad, & Cortes, 2004; Biber, Johansson, Leech, Conrad, & Finegan, 1999; Cortes, 2004; Gilquin & Paquot, 2008; Gledhill, 2000; Hyland, 2008a; Qin, 2014) have touched upon register and genre-specific usage of multi-word units recently (Greaves & Warren, 2010). The aim of these kinds of studies has been to detect varieties of multi-word sequences and classify them based on their usage within their everyday context (Biber, 2009).
When we compare the genres, the studies about academic genres hold sway over as the one which is composed of idiosyncratic multi-word sequences in excessive numbers (Greaves & Warren, 2010). The following positive findings about the lexical bundle research led to the increasing interest on the analysis of multi-word units or lexical bundles. According to Biber et al. (1999), approximately 21% of the words in an academic prose take place in recurrent lexical bundles, and 17% of these recurrent bundles appear more than once. When the formulaicity of these recurrent multi-word units is considered to be neither a linguistic universal nor about the native writer’s innate capacity (Kachru, 2009; Wray, 2008), the two possible ways through which L1 and L2 academic writers learn multi-word units are formal instruction and non-formal incidental learning (Ellis, 2008; Li & Schmitt, 2009). Therefore, Coxhead and Byrd (2007, pp. 134-135) justifies why the multi-word units based on the corpus analysis should be emphasized in writing classes: (1) it is easier to use recurrent lexical bundles than to compose each sentence word by word; (2) recurrent lexical bundles become idiosyncratic structures of a certain genre that they provide fluency and meet expectations of the readers in a certain field; (3) it is difficult to reveal these word sets without the help of corpus analysis.
Furthermore, the absence of formulaic writing is often characterized with L2 writers (Bestgen & Granger, 2014; De Cock, Granger, Leech, & McEnery, 1998; Granger, 1998;
6
Peromingo, 2012) and their lack of mastery in the English academic writing (Cortes, 2004, 2008; Durrant & Mathews-Aydınlı, 2011; Li & Schmitt, 2009; Neff, 2008; Römer, 2009a). Moreover, L2 learners might overuse certain bundles at which they become proficient (Granger, 1998; Li & Scmitt, 2009). Furthermore, some bundles that are calqued on similar sequences in L1 are used repeatedly (Bestgen & Granger, 2014), or it is possible to see some speech-like bundles in academic writing (Bestgen & Granger, 2014; De Cock 2003, Juknevičienė 2009). For instance, Japanese academic writers overuse some English lexical bundles which have L1 equivalent in Japanese (Allen, 2010), or Spanish EFL writers frequently repeat the English multi-word connectors which stand for the similar expressions in their L1, Spanish (Peromingo, 2012). Conversely, L2 learners underuse some of the native-like bundles in their academic writing because of the “lack of register awareness, phraseological infelicities, and semantic misuse” (Gilquin, Granger, & Paquot, 2007, p. 319). For instance, De Cock and Juknevičienė (2009) found that L2 learners underuse noun phrases with postmodifier fragments. In terms of overuse and underuse of lexical bundles, Paquot (2007) pointed out the differences between Dutch-speaking learners, and French- and Spanish-speaking learners. Also, there were some different lexical choices of these learners such as the Dutch-learners’ underuse of first personal pronouns. Similarly, Aarts and Granger (1998) indicated the underuse of gerund infinitives by Dutch, Finnish and French learners, and the overuse of to-infinitives by French learners. Durrant and Schmitt (2009) also suggest that L2 learners overuse the collocations which have high raw frequencies or high t-scores while they underuse the ones with high mutual information (MI) scores that have low frequency but inseparable ones.
To understand idiosyncratic multi-word units, if that is available, the two corpora of learners have been initiated: The International Corpus of Learner English (ICLE, see Granger, Dagneaux, & Meunier, 2002) and the Longman Learners’ Corpus (see Longman Corpus Network, 2003). When these corpus studies have been supplemented with some other individual corpora studies, a range of L2 English learners could have been examined: Chinese (Chen & Baker, 2010; Ping, 2009), French (De Cock, Granger, Leech, & McEnery, 1998) Japanese (Ishikawa, 2009), Lithuanian (Juknevičienė, 2009), and Swedish (Ädel & Erman, 2012).
To describe the usage of lexical bundles in academic writing, Pérez-Llantada (2014) conducted a research study on Spanish expert academic writers. Liu (2012) and Salazar
7
(2010) studied on the variations between American and British academic written English, and Philippine and British scientific English respectively. The studies on the most frequently used lexical bundles and academic formula lists were carried out Byrd and Coxhead (2010), Liu (2012), and Simpson-Vlach and Ellis (2010). Some other studies made a comparison on academic writing between native and non-native speakers of English, and presented the differences in usage of lexical bundles (e.g. Ädel & Erman, 2012; Chen & Baker, 2010; Cortes, 2004). Grabowski (2015), Biber and Barbieri (2007), and Biber, Conrad and Cortes (2004) pointed out the register variation in their studies. Research on lexical bundles has expanded even to connect lexical bundles and moves in certain sections of research articles, such as introductions (e.g. Cortes, 2013).
Recently, the significance of lexical bundles has also been understood by Turkish researchers. The first study was carried out at Georgia State University on the analysis of four-word multiword units in the research articles written by the Turkish authors (Bal, 2010). Bal (2010) found that the Turkish authors made use of ninety-nine frequent bundles while writing their articles; however, more than half of these 99 bundles were not identified in the relevant literature before. Therefore, Bal (2010) raises the question if there is L1 transfer in lexical bundle use. Öztürk (2014) took a step forward with a comparison study, and he investigated the structural and functional analysis of English lexical bundles used by Turkish and native English writers. He found that Turkish postgraduate students used more lexical bundles than the native students and authors did. Similar to the findings of Bal (2010), his results revealed that Turkish postgraduate students employed different bundles than the native authors and students, and he suggested a further study on the crosslinguistic examination of lexical bundles in Turkish and English texts. In addition, some comparative studies of Turkish with other languages took place within the last three years. For instance, Tokdemir Demirel and Shahriari Ahmadi (2013) compared the lexical bundle use in the research article acknowledgements of Turkish and Iranian researchers, and found that Iranian writers used some certain lexical bundles more than their Turkish counterparts while Turkish writers avoided some of these bundles in their writing. Karabacak and Qin (2013) compared the lexical bundles used by Turkish, Chinese and American university students, and argued the explicit teaching of lexical bundles as the even advanced learners of English could not learn some of the bundles through simple exposure. A year later, Qin (2014) undertook a study on the use of formulaic bundles by non-native English graduate writers from different countries including Turkey and published American authors in applied
8
linguistics, and she found that the usage and variety of the lexical bundles increased as the study level of the participants progressed. With the increasing interest, the recurrent phrases in the spoken English of Turkish learners of English and native English speakers were also analyzed (Şahin Kızıl & Kilimci, 2014). The inclusion of lexical bundles studies into the Turkish literature also initiated the studies lexical bundles in Turkish texts. Çalışkan (2014) was the first researcher who addressed the structural features of lexical bundles in Turkish. She concluded that lexical bundles in Turkish consist of mainly content words due to the agglutinative characteristic of Turkish language. Since 2010, a limited number of studies were carried out on the issue of lexical bundles; however, no study so far has attempted to deal with a comparison of the use of Turkish lexical bundles and English lexical bundles in academic writing from the viewpoint of crosslinguistic influence. Therefore, the next section will explain the significance of the present study.
Significance of the Study
In daily life, our speech and writing is full of formulaic sequences or lexical collocations. The increasing interest on corpus linguistics has led to a detailed examination of these lexical bundles for pedagogical reasons. According to many researchers (e.g. Meunier & Granger, 2008; Schmitt, 2004), the reason behind the failure of acquiring formulaic idiomaticity and fluency is the inadequate or ineffective instruction. Nattinger (1980) also argued that the primary focus of language instruction should be on the ready-made units and how they are collocated. To construct larger discourse, lexical bundles can be taught as the ready-made units of the language (Nattinger & DeCarrico, 1992). The founder of the Lexical Approach, Michael Lewis (1993) also argued that “…language is grammaticalised lexis and places the way words combine at the centre of its theoretical perspective” (p. 195), and emphasized concordances, colligations and collocations. After seven years, a new book was published to introduce further developments in the Lexical Approach under the editorship of Lewis. As the author of the part on vocabulary teaching in this book, Hoey (2000) also suggested that one of the best strategies to enhance the learners’ vocabulary is to “learn not just the meanings of the words but the environments they occur in” (p. 242). In short, as the instruction of lexical phrases became a critical issue in language learning, the need for the scrutiny of corpora emerged for the sake of language learners (Wible & Tsao, 2008).
9
In its short history, the corpus-based research has been driven by the idea that learning vocabulary is more than acquiring words separately (Leech, 2011). As the observations of researchers (Ebeling & Hasselgård, 2015; Hasselgren, 1994) confirm, learners use words wrongly when they do not know how the words collocate or combine with each other. Therefore, researchers have aimed at classifying lexical bundles based on their structural and functional categories (e.g. Biber, Conrad, & Cortes, 2004; Cortes, 2004), and specifying their usage in certain registers or genres (e.g. Cortes, 2004; Qin, 2014). Also, discipline and native language background of learners have been the focus of the corpora research. Apparently, each register or genre has some communicative purposes, and the uses of lexical bundles vary harmoniously with these purposes (Biber & Barbieri, 2007). For example, the preferences change dramatically when we talk about written language or academic prose. Each discipline also creates its own typical writing style and jargon, and only the members of the same community can understand each other with this unique language.
The previous studies also indicated that learners, irrespective of their proficiency levels, overuse, underuse or misuse the formulaic sequences (Ädel & Erman, 2012; Chen & Baker, 2010; Salazar, 2010). Although these studies claimed that the reason behind overuse, underuse or misuse might be the L1 interference of pragmatic functions, Paquot (2013) criticizes the methodology of previous studies as they assume L1 interference just based on L2 texts without analyzing the data in L1, and indicates the lack of studies which look up the transfer effects on foreign language learners’ production of formulaic sequences. Still, Paquot (2013, p. 411) argues that “EFL learners bring knowledge of the L1 lexicon to the writing task in the foreign language, including preferred collocations and lexicogrammatical patterns of words, as well as their stylistic or register specificities, discourse functions and frequency of use”. However, there are not many studies which have investigated the influence of the mother tongue thoroughly (Gilquin & Paquot, 2008). Therefore, “transfer remains a largely hypothetical factor” due to the lack of the contrastive studies on lexical bundles in different languages (Granger, 2013, p. 1). Just to give an example for this situation, Allen (2010) considered the misuse of singular/plural forms and the frequent use of some linguistic structures a justification for native language transfer. However, for such a transfer argument, he should have compiled a second corpus in L1 Japanese besides the L2 corpus, and analyzed the corpus based on his assumptions. Based on these criticisms, it is clear that recently there has been a growing interest on lexical bundles and the possible
10
L1 influence on the use of lexical bundles in L2; however, previous literature suffers from some methodological weaknesses.
Some studies have also been carried out on Spanish and French to explore the possible L1 influences. For instance, Paquot (2013) tested out if L1 of French EFL learners have an effect on the 3-word sequences of their L2 (English). After finding the most frequent lexical bundles in International Corpus of Learner English (ICLE), she found the most frequent equivalent bundles in French. To check the possible L1 influence, Paquot (2013) analyzed the L1 influence under four main categories: transfer of collocational and colligational preferences, transfer of syntactic constructions, transfer of functions and discourse conventions, and transfer of L1 frequency. According to the main results, language learners brought the frequent L1 words and bundles and used their translational equivalents in L2 writing. Paquot (2013) categorized these under the term of “transfer of primings” with the saying of Hoey (2005, p. 183). In a follow-up study, Paquot (2014) attempted to determine the overused multiword sequences in L2 English writing of French learners, and compared the multiword sequences in L2 with the most frequent corresponding sequences in French. With some slight differences, she evaluated the L1 influence again under four main categories: transfer of semantic properties, transfer of collocational preferences, transfer of functions and discourse conventions, and transfer of L1 frequency. Again, Paquot (2014) identified some transfer effects regarding collocational and colligational preferences, rhetorical conventions and semantic features. Furthermore, she realized that French learners of English used unmarked lexical bundles which were frequent in their L1. Therefore, she suggested that the function and frequency of the lexical bundles in L1 can be worthwhile to explore and document. Recently, Pérez-Llantada (2014) compared the formulaic language in L1 and L2 expert academic writing through a different methodology. She compiled three corpora consisting of 360 L1 English research articles, 336 L2 English research articles, and 360 L1 Spanish research articles. First, the extracted lexical bundles were classified according to their structures, functions, and the types of words the bundles included. Then, she adopted a frequency-first principle, and analyzed the bundles in two main categories as convergent usage of bundles and divergent usage of bundles. Briefly, she found that the use of lexical bundles by the Spanish writers did not conform to the native norms, and presented the similarities and differences between two languages on the basis of frequency.
11
In case of Turkish, due to the agglutinative characteristic of Turkish language and dearth of studies on Turkish language, the extraction of lexical bundles from a corpus will require some different methodologies and tools. For example, Biber (2009) proposed that the formulaic sequences in Turkish and Finnish which have inflectional morphologies should be examined regarding agglutination morphemes and grammatical functional words as the two basic determining factors of formulaic pattern types. In other words, there are many grammatical function words in English but Turkish makes use of agglutinative morphemes instead of these function words. Similarly, Durrant (2013) argued that it is difficult to understand formulaic sequences at a glance in languages such as Turkish and Finnish because in agglutinating languages such as Turkish, a multiword lexical bundle in English can be expressed with a single word. However, in order to understand how Turkish and English affect each other, or to make any claims about transfer across languages, the formulaic sequences in both languages should be compared. Therefore, instead of adopting “all-or-nothing dichotomy” (Durrant, 2013, p. 3), taking the first step in the comparative analysis of Turkish and English lexical bundles is of importance to scrutinize if Turkish expert writers’ use of lexical bundles can be attributed to the crosslinguistic influence. The results of such a study will substantially contribute to the language teaching field within a global context (Çalışkan, 2014).
In terms of the pedagogical reasons, certainly, the examination of lexical bundles in the scientific writing of Turkish expert writers will give invaluable insights to the beginners in the academy such as master or doctorate students and the novice academic staff in their endeavors to write academic papers. In the language teaching field, there is a need for the production of novel learning materials, especially for lexical bundles (Wible, 2008), and the design of new materials should establish a link between English for academic purposes and writing pedagogy (Gilquin, Granger, & Paquot, 2007). For example, Meunier (2012) expresses significance of formulaic approach as follows:
…adopting a formulaic approach to L2 teaching seems relevant for three main reasons at least: (a) formulaicity is ubiquitous in language; (b) formulaic language use has been shown to be a marker of proficiency in an L2…; and (c) studies have demonstrated that L2 language learners find formulaicity particularly challenging as it is impossible for them to use the innate native intuition usually associated with formulaic language use… (p. 112).
Although Flowerdew (2001) stated that native corpora is worth studying rather than learner corpora for pedagogical reasons, the comparison of learner corpora with native corpora can be investigated to see congruent and incongruent lexical bundles and prepare teaching
12
materials for the target learner population. Granger (2009) also highlights L1-L2 comparisons from a pedagogical point of view:
…the interest of L1-L2 comparisons is even more obvious as they help teachers identify the lexical, grammatical and discourse features that differentiate learners’ production from the targeted norm and are therefore a very rich source of data for pedagogical applications (p. 19). Furthermore, the examination of lexical bundles in academic genres is of importance as they consist of many recurrent and conventionalized structures to be able to develop a common communication tool between authors and readers (Hyland, 2012). What is more frequent, in other words recurrent, in academic language might mean that learners frequently will need those structures which are very beneficial in their writing (Gilquin, 2006). Therefore, the comparison of genres is expected to be a new direction for further research in phraseology (Ebeling & Hasselgård, 2015), and the results of contrastive phraseology research will reveal the needs of learners through frequency analysis, and certainly will have implications for integration of lexical approach to language teaching in terms of the design of new materials. To sum up, knowing common lexical bundles is a key factor to be able to write in a native-like manner (Ellis, Simpson-Vlach, & Maynard, 2008), and the current study is expected to initiate the L1-L2 contrastive studies on the use of lexical bundles by Turkish researchers in the field of educational sciences. As a result, the future materials which can be produced through these studies might help novice writers and learners use lexical bundles appropriately (Cortes, 2015) or in a native-like manner (Ebeling & Hasselgård, 2015).
Purpose and Scope of the Study
The present study aims to identify the most frequent lexical bundles used by native Anglo-Americans in their L1 English and native Turkish researchers in their Turkish (L1) and English (L2) articles in the field of educational sciences. To see a clearer picture, these lexical bundles will be classified based on their structural and functional characteristics. Through this classification, it will be possible to compare native and non-native corpora in terms of frequency, structure and functions of lexical bundles. Finally, the effect of L1 influence on Turkish educational science researchers’ use of English lexical bundles will be scrutinized. To specify the investigation thoroughly, the following research questions will be posed:
13
What are the most frequent lexical bundles in a corpus of published L1 English research articles written by Anglo-American researchers in the field of educational sciences?
What are the most frequent lexical bundles in a corpus of published L2 English research articles written by Turkish researchers in the field of educational sciences?
How can these lexical bundles be classified based on their structural and functional characteristics?
Finally, is there any crosslinguistic influence between the interlanguage (L2 English) and native language (L1 Turkish) use of Turkish authors in terms of lexical bundles? If they do, do these bundles involve some structural or functional patterns?
Limitations of the Study
First, this study focuses on the genre of research article and the field of educational sciences. Based on the guidelines of the journals, the research articles in the corpus might have been revised and edited from the submission of the manuscript to the publication process. In this revision and editing process, some influences of native language or non-native-like lexical bundles might have been removed with the suggestions of editors and reviewers (Allen, 2010). Furthermore, some researchers who were not capable of writing their articles in English might have had the research articles translated. In this case, translated texts can pose a risk to the interpretation of the results in this study but even this limitation might be a comprehensive output for the translators in the business. Furthermore, as the corpora will be compiled from the research articles, the results cannot be generalized to the other genres. Therefore, the results should be approached cautiously.
The other challenging issue for this research is the identification of crosslinguistic influence. Researchers often argue their judgments on crosslinguistic influence based on their individual perception. Therefore, Odlin (2003) indicates the risk of generalizing or predicting crosslinguistic influence without checking the all options, and suggests researchers to be skeptical. Therefore, it should be kept in mind that the presence or absence of L1 influence cannot be generalized without a detailed scrutiny of all the alternatives
14
(Odlin, 2005). In this regard, this study is expected to contribute to the field and give inspiration for further research.
Definitions of Some Key Concepts
The definitions of some key concepts were given below not to confound the mind of the readers. As many similar terms and concepts are available in the field of phraseology, mostly direct quotations from the experts of the field were given to define the key concepts.
Cluster: Cluster can be defined as “any groups of words in sequence” (Baker, Hardie, & McEnery, 2006, p. 34).
Cognates: A word in a language might be similar with a word in another language regarding its orthographic or phonetic form, and these similar words are called cognates.
Colligation: While the relationships between words are at lexical level in collocations, the colligation refers to the relationship at grammatical level. For instance, a noun may colligate with an adjective or a verb might colligate with an adverb.
Collocation: Collocation can be defined as “the phenomenon surrounding the fact that certain words are more likely to occur in combination with other words in certain contexts” (Baker, Hardie & McEnery, 2006, p. 36). Collocations can be searched within a -5 and +5 span of the target word.
Concordance: While studying on a key word, the context of this word was presented in a list in which a few words to the left and right of the keyword can also be seen.
Concordancer: Some software packages called concordancer such as WordSmith, AntConc were used to create a concordance list.
Corpus: The word corpus refers to the body in Latin. The plural version of the corpus is corpora. In applied linguistics, the corpus refers to a collection of texts in the digital format. The systematically organized data in corpus allows researcher to conduct quantitative and qualitative studies. Some of the corpus types include specialized, reference, multilingual, parallel, learner and diachronic.
Corpus linguistics: As an emerging domain in applied linguistics, corpus linguistics has been used for general and specific aims. Mainly, the researchers benefit from corpus linguistics in terms of writing grammar books and dictionaries, exploring different patterns
15
in different genres, registers and disciplines, and shaping language teaching resources based on the results of corpus analyses (Conrad & Biber, 2001). Specifically, some lexical or structural patterns can be studied, or it can be integrated with discourse studies (Berns, 2010). Transfer or crosslinguistic influence: According to Odlin’s (1989) frequently cited definition, “Transfer is the influence resulting from the similarities and differences between the target language and any other language that has been previously (and perhaps imperfectly) acquired” (p. 27). After Selinker (1992) emphasized the importance of statistical comparisons for the identification of transfer, Jarvis (2000) attempted to provide a common definition for crosslinguistic influence: “L1 influence refers to any instance of learner data where a statistically significant correlation (or probability-based relation) is shown to exist between some feature of learners’ IL performance and their L1 background” (p. 252). In this study, I will use the terms of transfer, crosslinguistic influence and L1 influence interchangeably, as suggested by Ellis (2008). By linking Odlin’s and Jarvis’s definition, he suggested the following definition: “Language transfer refers to any instance of learner data where a statistically significant correlation (or probability-based relation) is shown to exist between some feature of the target language and any other language that has been previously acquired” (p. 351).
Lexical bundles: In the literature, lexical bundles were firstly defined by Biber et al. (1999) in Longman Grammar of Spoken and Written English. With the definition of Biber et al. (1999) lexical bundles refer to “recurrent expressions, regardless of their idiomaticity, and regardless of their structural status” (Biber et al., 1999, p. 990).
16
CHAPTER 2
REVIEW OF LITERATURE
This chapter will provide a rationale for the present study by elucidating corpus linguistics, corpus-based studies, and formulaic language and corpora. Then, the pedagogical value of lexical bundles will be discussed with the related literature. Lastly, the conducted studies on the lexical bundles in different registers, genres and disciplines will be presented in line of the current research.
2.1.Corpus Linguistics and Phraseology
Is corpus linguistics a subfield of linguistics or methodology developed for the analysis of language? Indeed, the definition of corpus linguistics has been questioned by many researchers in the field, and it has been viewed as a methodology (Bowker & Pearson, 2002; Gries, 2008; Leech, 1992a; Lindquist, 2009; McEnery & Wilson, 2001), a theory (Halliday, 1993; Sinclair, 1991, 2004, 2008) or an approach (Tognini-Bonelli, 2001). Avoiding a clear-cut definition, Kennedy (1998, p. 1) defined corpus linguistics as “one source of evidence for improving descriptions of the structure and use of languages, and for various applications including the processing of natural language by machine and understanding how to learn or teach a language”. Whatever the definition is, it is clear that 2000s with the development of electronic corpus gave a rise for the trend of corpus linguistics. The advantages of using a corpus was summarized by Svartvik (1992, p. 8-10):
A corpus gives objective results rather than talking on introspections. A corpus helps researchers in the linguistic field verify their research.
17
Issues such as language variation, dialect, register and style can be researched with a good corpus.
The differences in corpus studies can be presented through the frequency of occurrence.
A corpus might provide examples for the rule-based system of a language. A corpus provides well-grounded fundamental information for applied fields
such as language teaching.
Providing that a linguist explains everything in data, corpus provides a full accountability for linguistic features.
Sharing a corpus will increase the other potential studies by giving an access all researchers in the world.
A corpus is a great source for non-native speakers of a language.
In a setting of English as a Foreign Language (EFL), the current study adopted corpus linguistics as a methodology to scrutinize the phraseology in research articles for its pedagogical benefits.
Phraseology might be defined as “the study of word combinations” (Granger & Paquot, 2008, p. 32) humbly. Although there is not a clear-cut consensus on a definition, it was overtly called as the periphery and heart of the language by Ellis (2008). The historical traces of the phraseology date back to the earlier 20th century, and the researchers such as Jespersen (1924), Palmer (1933) and Firth (1951), beginning from those times, established the theoretical ground for the current phraseology research. In those times, their main concern was on collocations and fixed expressions. However, the trend changed its direction toward qualitative studies on formulaic expressions, and many researchers (e.g. Nattinger & DeCarrico, 1992; Pawley & Syder, 1983) studied on formulaic sequences, idioms, and set expressions between 1970s and early 1990s. Although the authors in the former Soviet Union discovered the field of phraseology and conducted some studies in 1940s, the field experienced a steady growth in the USA and Europe after 1990s with the advances in computer technology and electronic corpora. According to Sinclair (2008), phraseology has been neglected until 1990s in the western culture due to the fact that it does not make a distinction between grammar and lexis, and it lays on syntagmatic patterns instead of paradigmatic ones. In other words, Sinclair (2004, p. 176) criticized the theoretical and descriptive linguists and their views on the “priorization of grammar at the expense of lexis”.
18
A few years ago, Hunston and Francis (2000) also argued that there was no need to prefer either lexis or grammar in the sake of the other.
Considering the aforementioned concerns, Sinclair (1991) proposed the removal of the sharp division between form and meaning, and, through his ideas, moved the phraseology field into a 20-year golden era of research. Hunston and Francis (2000, p. 272) explained how the earlier orthodoxies were demolished, and summarized the new ones as follows:
There is a strong association between meaning and pattern. Grammar and lexis are one and the same thing.
Grammar may be interpreted linearly as well as in constituent terms. A multiplicity of grammars, mapping meaning roles on to
lexico-grammatical configurations, might be useful alternative to a general grammar.
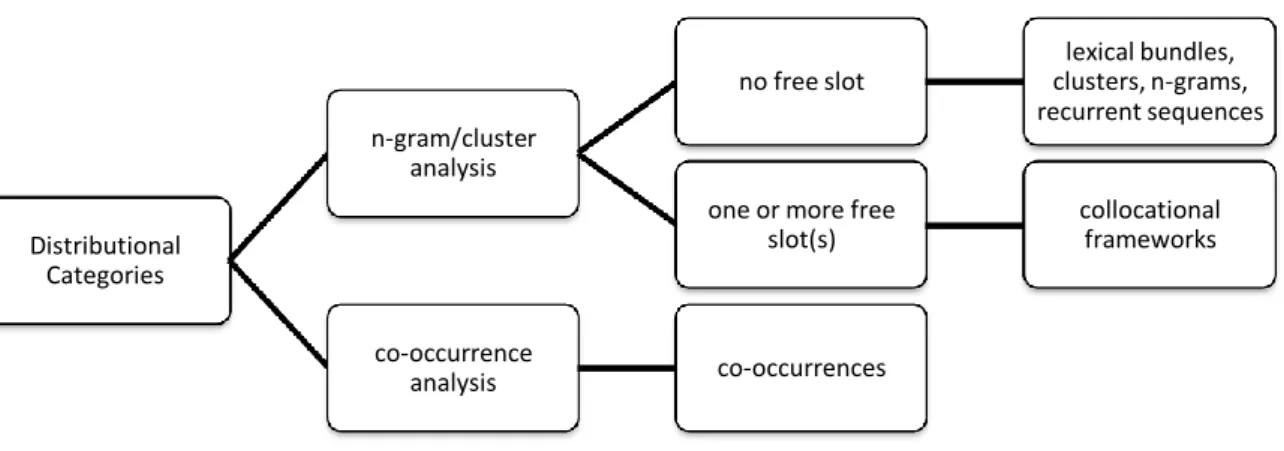
Figure 1. Distributional categories. Adapted from “Disentangling the phraseological web”
(p. 39), by S. Granger & M. Paquot, 2008, in S. Granger & F. Meunier (Eds.), Phraseology:
An interdisciplinary perspective, Amsterdam, John Benjamins Publishing Company.
The inductive corpus-driven approach of Sinclair to identify phraseological units was called as distributional (Evert, 2005) or frequency-based (Nesselhauf, 2004) approach. Due to the fact that this is a corpus-driven approach, there is no predefined linguistic classification in its nature. In the 20-year golden area of research, the distinguished researchers studied on the concepts of collocation (Evert, 2005; Manning & Schutze, 1999; Schmid, 2003; Sinclair,
Distributional Categories n-gram/cluster analysis no free slot lexical bundles, clusters, n-grams, recurrent sequences
one or more free slot(s)
collocational frameworks
co-occurrence
19
1991; Stubbs, 2002), colligation (Francis, 1993; Francis, Hunston, & Manning, 1996; Hoey, 1998; Hunston, 2001; Hunston, Francis, & Manning, 1997; Sinclair, 1991), semantic prosody or preference (Louw, 1993; Partington, 2004; Sinclair, 1991, 2004; Stubbs, 1996, 2002), lexical bundles (Biber, 2006; Biber, Johansson, Leech, Conrad, & Finegan, 1999), lexical priming (Hoey, 2005), concgrams (Cheng, Greaves, & Warren, 2006), and phrase frames (Fletcher, 2006). Such a number of studies in a short time led to confusion and fuzziness on the concepts related to the phraseology, and Granger and Paquot (2008) redefined the divisions of the phraseology regarding the distributional approach (Figure 1). According to this division, n-gram or cluster analysis analyzes the continuous sequences of two or more words while co-occurrence analysis is into discontinuous combinations of two words. In the current study, an analysis will be carried out on lexical bundles in which there is no slot between the words through corpus linguistics which has been “a methodological basis for pursuing linguistic research” (Leech, 1992b, p. 105) and “the single most frequently used method employed in the study of phraseology” (Gries, 2008, p. 15).
Lexical Bundles
The term “lexical bundle” was first used by Biber, Johansson, Leech, Conrad and Finegan (1999, p. 589) in Longman Grammar of Spoken and Written English, and it was regarded as “extended collocations”. Biber et al. (1999, pp. 589-590) defined lexical bundles as “bundles of words that show a statistical tendency to co-occur” and “recurrent expressions, regardless of their idiomaticity, and regardless of their structural status”. The extraction of recurrent continuous sequences of two or more words has been studied under different terminologies: chains (Stubbs, 2002), clusters (Hyland, 2008b; Scott & Tribble, 2006), formulaic sequences (Schmitt, 2004; Wray, 2000a, 2000b, 2008), n-grams (Stubbs, 2007), multi-word formulaic sequences (Biber, 2009), prefabs (Erman & Warren, 2000) and lexical bundles (Ädel & Erman, 2012; Allen, 2010; Biber et al., 1999; Biber & Barbieri, 2007; Biber, Conrad, & Cortes, 2004; Coxhead & Byrd, 2007; Grabowski, 2015; Hyland, 2008a; Paquot, 2013; Salazar, 2014).
Due to the fact that a frequency-based approach is used for identifying lexical bundles (Biber, 2006), some different criteria have been used in several studies (See Table 1). Although Biber (2006, p. 134) argued these criteria “arbitrary”, defining a cut-off criterion is a prerequisite for the identification of lexical bundles. The related studies mostly adopted
20
a cut-off point between 10 and 40 times per million words, and the bundles should spread in three to five texts or %10 of the texts in the corpus. The frequency criteria changed according to the size (small or big) and the characteristics (written or spoken) of the corpus and the dispersion criteria was to avoid idiosyncratic usages of writers. Furthermore, the analyses in some studies give high number of lexical bundles, and this makes the data unmanageable for a systematic classification. Therefore, to make the long list short, some researchers increased their frequency cut-off to more conservative points such as 20 or 40 per million words. One drawback of a corpus compilation, specifically in a corpus of research articles, is the presence of the articles from the same researchers, and, to avoid the idiosyncratic usages of the same authors, the dispersion criteria can be increased to 10% of the texts. Thus, the frequency and dispersion criteria are not arbitrary in fact but depend on the corpus the researchers study on.
Table 1
The Frequency and Dispersion Criteria of the Some Previous Studies
Study Frequency (per million word) Dispersion Biber et al. (1999)
10 times pmw for 4-word bundles 5 times pmw for 5- and 6- word bundles
in at least five texts
Biber (2006) 40 times pmw for 4-word bundles in at least five texts Biber & Barbieri
(2007) 40 times pmw for 4-word bundles in at least five texts
Hyland (2008a, 2008b) 20 times pmw for 4-word bundles in at least 10% of the texts
Chen & Baker (2010) 25 times pmw for 4-word bundles in at least three texts Ädel & Erman (2012) 25 times pmw for 4-word bundles in at least three texts Pan, Reppen, & Biber
(2016) 40 times pmw for 4-word bundles in at least five texts
Another crucial selection criterion was associational measures, especially for the researchers who are interested in the pedagogical aspect of phraseological studies. The frequency criteria produce a long list of lexical bundles, but the psychological salience of the lexical bundles on the top of the frequency lists is a matter of discussion in the language teaching field. Briefly, neither frequency nor mutual information score is alone able to extract noteworthy lexical bundles for teachers and instructors (Simpson-Vlach & Ellis, 2010). The two most frequently used method were log-likelihood statistic and mutual information score. The
21
mutual information metric, which is again a kind of log-likelihood ratio, compares the probability of observing a lexical bundle with the probabilities of observing each of its component words (Church & Hanks, 1990; Manning & Schütze, 1999; Oakes, 1998), and, thus, it shows that “the two words occur together for a reason and not just by random chance” (Salazar, 2014, p. 43). Ellis, Simpson‐Vlach and Maynard (2008) tested the psycholinguistic validity of corpus-derived formulas with skilled English for Academic Purposes (EAP) instructors and found that native speakers are sensitive to mutual information score rather than the frequency of occurrence. They called their measure, which combines frequency and mutual information, as “formula teaching worth” (p. 392). Two years later, Simpson-Vlach and Ellis (2010) carried out to determine the top 200 written and spoken academic formulas list, and their findings confirmed their formula, a combination of frequency and mutual information. However, these measures are good at calculating the association between two words, and this study attempts to identify the four-word lexical bundles in the research articles. Therefore, these association measures were not in the remit of this study.
Table 2
Structural Taxonomy
Structural Category Examples
Noun phrase with of-phrase fragment the results of the, the purpose of the
Noun phrase with other post-modifier fragments
the extent to which, the relationship between the
Prepositional phrase with embedded of-phrase fragment
as a result of, in terms of the
Other prepositional phrase (fragment) between the two groups, in the present study
Anticipatory it + verb phrase/adjective phrase
it is clear that, it has been suggested
Passive verb + prepositional phrase fragment
is related to the, is to be found in
Copula be + noun phrase/adjective phrase is one of the, is due to the
(Verb phrase +) that-clause fragment should be noted that, that there is no
(Verb/adjective +) to-clause fragment are likely to be, to ensure that the
Adverbial clause fragment as we have seen, as shown in figure
Pronoun/noun phrase + be (+ . . .) there has been a, this is not to say
22
As the comparison of the bundles did not seem possible with statistical measures alone, lexical bundles have been examined closely in terms of their structures and functions. Considering the fact that five per cent of the lexical bundles stood for the complete structural units and lexical bundles are not structurally complete units in their nature, Biber et al. (1999) developed the taxonomy for the structural classification of the bundles (See Table 2 for the structural taxonomy of the bundles in academic prose). Another finding of Biber et al. (1999) was that the longer versions of the bundles were the extensions of the shorter bundles. In other words, a four-word bundle holds three-word bundles in their forms.
Table 3
Functional Classification of Lexical Bundles
Stance expressions Epistemic stance Attitudinal/modality stance Desire Obligation/directive Intention/prediction Ability Discourse organizers Topic introduction/focus Topic elaboration/clarification Referential expressions Identification/focus Imprecision Specification of attributes Quantity specification Tangible framing attributes Intangible framing attributes
Time/place/text reference
Place reference Time reference
Text deixis
Multi-functional reference Note: The table was adapted from “If you look at …: Lexical bundles in university teaching and textbooks”, by D. Biber, S. Conrad, & V. Cortes, 2004, Applied Linguistics, 25(3), 371-405.
Although the researchers have been using the structural taxonomy of Biber et al. (1999) with slight adaptations, it is not likely to say the same for the functional taxonomy. The researcher developed the new categories with the new discourse functions they found. One of two latest functional taxonomies was developed by Biber, Conrad and Cortes (2004), and the other was developed by Hyland (2008a). In the study they analyzed the use of lexical bundles in