Makine öğrenme yöntemleri yardımıyla tüketim istatistiklerine göre talep tahmini
Tam metin
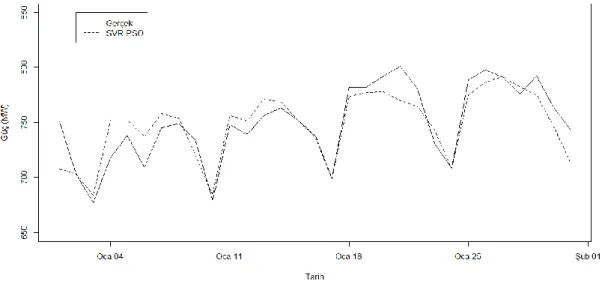
Şekil
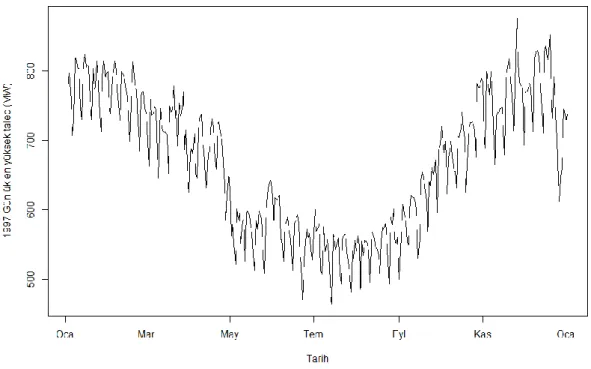
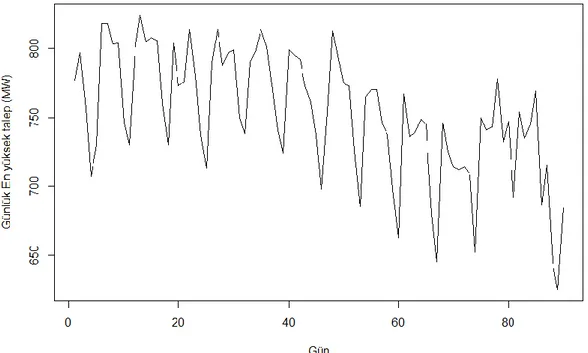
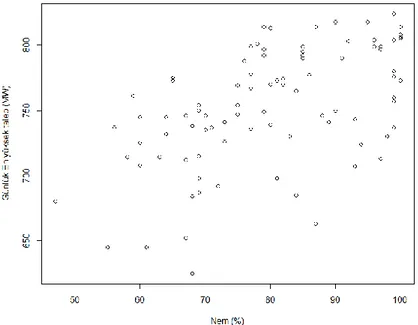
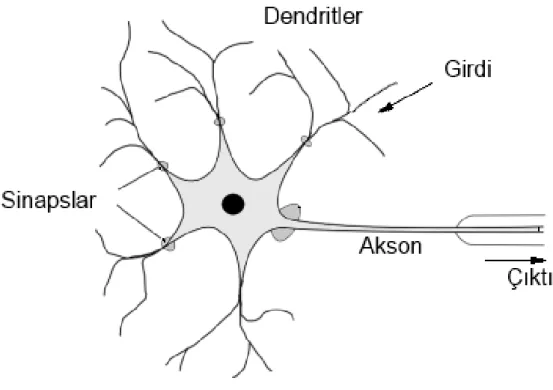

Benzer Belgeler
Bu çalışmada, tahmin edilen toplam belediye atık miktarı ile uygulamada belirtilen göstergeler arasındaki ilişkinin varlığını ve doğruluğunu göstermek,
Deniz Türkali'nin kızı Zeynep Casalini, Sezen Aksu konserinde bir gecede şöhret oldu?. “Annem çok az
[r]
Kolaylık olması bakımından bu örneği k=1 (Basit Doğrusal Regresyon) modeli için çözelim.. Aşağıdaki teoremlerde X matrisinin sabitlerden oluşan ve tam ranklı olduğu
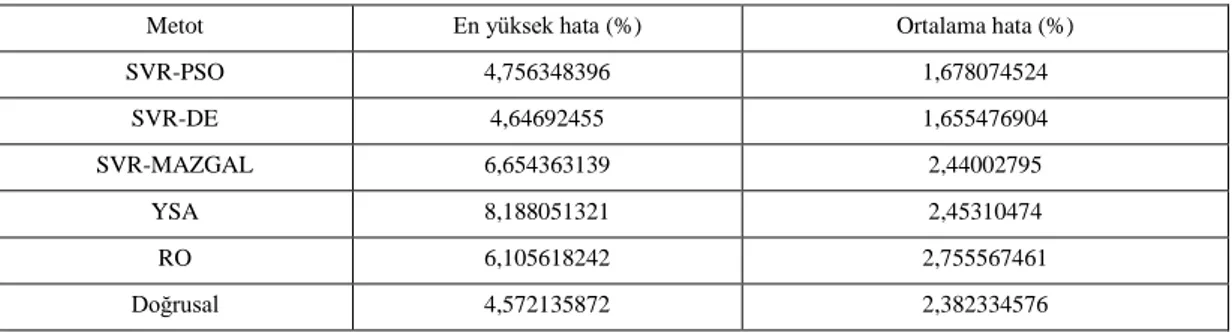
Test veri kümesi ile tahmin veri kümesi arasındaki hata oranı Kaplama Alanı çıktı değeri için Tablo 6.2.’deki gibi elde edilmiştir.. Kaplama alanı değerlerinin
Bu tez çalışmasında; yeni ürün geliştirme sürecinin hızlandırılması, maliyetin azaltılması, müşteri ihtiyaçlarına en iyi şekilde karşılanması için
Özet: Bu çalışmada Burdur gölü su seviyesi değişimlerinin tahmin edilmesi amacıyla bulanık mantık yöntemiyle bir model geliştirilmiştir.. Ayrıca bağımsız
Bu sonuçlara göre bağımsız değişken sayısı fazla olduğu ve özellikle bağımsız değişkenler arasında ilişki olduğu durumda çoklu doğrusal regresyon analizi,
![[Beyoğlu Güzelleştirme ve Koruma Derneğinin Tarih Araştırma Komitesinin raporu]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACH5BAEAAAAALAAAAAABAAEAAAICRAEAOw==)