HASTANE BİLGİ YÖNETİM SİSTEMLERİNDE
VERİ MADENCİLİĞİ: HASTA PROFİL TAHMİNİ
Duygu KARABULUT
2021
YÜKSEK LİSANS TEZİ
ENDÜSTRİ MÜHENDİSLİĞİ
Tez Danışmanı
Prof. Dr. Filiz ERSÖZ
HASTANE BİLGİ YÖNETİM SİSTEMLERİNDE VERİ MADENCİLİĞİ: HASTA PROFİL TAHMİNİ
Duygu KARABULUT
T.C.
Karabük Üniversitesi Lisansüstü Eğitim Enstitüsü Endüstri Mühendisliği Anabilim Dalında
Yüksek Lisans Tezi Olarak Hazırlanmıştır
Tez Danışmanı Prof. Dr. Filiz ERSÖZ
KARABÜK Ocak 2021
ii
Duygu KARABULUT tarafından hazırlanan “HASTANE BİLGİ YÖNETİM SİSTEMLERİNDE VERİ MADENCİLİĞİ: HASTA PROFİL TAHMİNİ” başlıklı bu tezin Yüksek Lisans Tezi olarak uygun olduğunu onaylarım.
Prof. Dr. Filiz ERSÖZ ...
Tez Danışmanı, Endüstri Mühendisliği Anabilim Dalı
KABUL
Bu çalışma, jürimiz tarafından oy birliği ile Endüstri Mühendisliği Anabilim Dalında Yüksek Lisans tezi olarak kabul edilmiştir. 21/01/2021
Ünvanı, Adı SOYADI (Kurumu) İmzası
Başkan : Prof. Dr. Emel KIZILKAYA AYDOĞAN ( ERÜ) ...
Üye : Prof. Dr. Filiz ERSÖZ ( KBÜ) ...
Üye : Doç. Dr. Taner ERSÖZ ( KBÜ) ...
KBÜ Lisansüstü Eğitim Enstitüsü Yönetim Kurulu, bu tez ile, Yüksek Lisans derecesini onamıştır.
Prof. Dr. Hasan SOLMAZ ...
iii
“Bu tezdeki tüm bilgilerin akademik kurallara ve etik ilkelere uygun olarak elde edildiğini ve sunulduğunu; ayrıca bu kuralların ve ilkelerin gerektirdiği şekilde, bu çalışmadan kaynaklanmayan bütün atıfları yaptığımı beyan ederim.”
iv ÖZET
Yüksek Lisans Tezi
HASTANE BİLGİ YÖNETİM SİSTEMLERİNDE VERİ MADENCİLİĞİ: HASTA PROFİL TAHMİNİ
Duygu KARABULUT
Karabük Üniversitesi Lisansüstü Eğitim Enstitüsü Endüstri Mühendisliği Anabilim Dalı
Tez Danışmanı: Prof. Dr. Filiz ERSÖZ
Ocak 2021, 124 sayfa
Günümüzde teknolojik gelişmelerin hızla ilerlemesi sonucunda karmaşık ve büyük veri tabanları oluşmaktadır. Oluşan karmaşık verilerin işlenmesi oldukça zor olabileceğinden dolayı yazılım programlarına ihtiyaç duyulmaktadır. Çalışmanın amacı, veri madenciliğinin sağlık sektöründe uygulanmasında altyapı oluşturmak, istenilen verilere ulaşarak karar verme konusunda daha hızlı ve farklı bakış açısı kazandırmaktır. Bu hedefle, özel bir sağlık kurumundan hizmet alan hastaların verileri kullanılarak, verilerin analizi ve sonuca yönelik iyileştirme önerileri sunulmuştur. Hizmet alan bireylerin ve hizmet aldığı şubelerin özellikleri kategorize edilerek, hasta profili belirlenmeye çalışılmıştır. Hasta profilinin belirlenmesi, hasta taleplerini karşılama aşamasında hastanenin daha doğru yol izlenmesine yardımcı olacağı düşünülmüştür.
v
Anahtar Sözcükler: Sağlık sektörü, veri analizi, kestirimsel çözümleme
vi ABSTRACT
M. Sc. Thesis
DATA MINING IN HOSPITAL INFORMATION MANAGEMENT SYSTEMS: PATIENT PROFILE ESTIMATION
Duygu KARABULUT
Karabük University Institute of Graduate Programs Department of Industrial Engineering
Thesis Advisor: Prof. Dr. Filiz ERSÖZ January 2021, 124 pages
Nowadays, the rapid advancement of technological developments consists of complex and large databases. Software programs are needed because it can be very difficult to process the complex data. The aim of the study is to create an infrastructure in the application of the data mining in the health sector, to gain a faster and different perspective on decision making by reaching the desired data. With this aim, continuing to roam with service from a private health institution, cell analysis and result-oriented improvement recommendations are presented. The patient groups were tried to be determined by categorizing the characteristics of individuals receiving service and service reviews. It is thought that determining patient profile will help to follow a more accurate path in the stage of meeting their demands.
vii
Key Word : Health sector, data analytics, predictive analysis Science Code : 90618
viii TEŞEKKÜR
Bu tez çalışmasının planlanmasında, araştırılmasında, yürütülmesinde ve oluşumunda ilgi ve desteğini esirgemeyen, engin bilgi ve tecrübelerinden yararlandığım, yönlendirme ve bilgilendirmeleriyle çalışmamı bilimsel temeller ışığında şekillendiren sayın hocam Prof. Dr. Filiz ERSÖZ’e sonsuz teşekkürlerimi sunarım.
Sevgili aileme manevi hiçbir yardımı esirgemeden yanımda oldukları için tüm kalbimle teşekkür ederim.
ix İÇİNDEKİLER Sayfa KABUL ... ii ÖZET... iv ABSTRACT ... vi TEŞEKKÜR ... viii İÇİNDEKİLER ... ix ŞEKİLLER DİZİNİ ... xii ÇİZELGELER DİZİNİ ... xv BÖLÜM 1 ... 1 GİRİŞ ... 1 BÖLÜM 2 ... 3 VERİ MADENCİLİĞİ ... 3
2.1. SAĞLIK SEKTÖRÜ KAVRAMI VE ÖNEMİ ... 3
2.1.1. Sağlık ve Sağlık Hizmetleri Kavramı ... 5
2.1.2. Sağlık Hizmetlerinde Hasta Memnuniyeti ve Kalite Kavramı ... 6
2.2. VERİ MADENCİLİĞİ KAVRAMI VE SAĞLIK SEKTÖRÜNDE VERİ MADENCİLİĞİ ... 14
2.2.1. Veri Madenciliğini Etkileyen Faktörler ... 16
2.2.2. Veri Madenciliği Sürecinde Karşılaşılan Sorunlar ... 17
2.2.3. Veri Madenciliği Uygulama Alanları ... 18
BÖLÜM 3 ... 22
VERİ MADENCİLİĞİ AŞAMALARI ... 22
3.1. PROBLEMİN VEYA ÇALIŞMANIN TANIMLANMASI ... 24
3.2. VERİLERİN TOPLANMASI VE HAZIRLANMASI ... 25
3.3. MODELİN KURULMASI ... 26
x
Sayfa
BÖLÜM 4 ... 28
VERİ MADENCİLİĞİ MODELLERİ ... 28
4.1. TANIMLAYICI MODELLER... 29
4.1.1. Kümeleyici Modeller ... 29
4.1.2. Birliktelik Kuralları ... 32
4.2. TAHMİN EDİCİ MODELLER... 33
4.2.1. Sınıflayıcı Modeller ... 33
4.2.1.1. Karar Ağaçları ... 34
4.2.1.2. Yapay Sinir Ağları ... 36
4.2.1.3. Bayes Sınıflandırma Algoritması ... 38
4.2.1.4. Çoklu Doğrusal Regresyon ... 39
4.2.1.5. Lojistik Regresyon ... 39
4.2.1.6. Genetik Algoritma ... 39
4.2.1.7. Random Forest Algoritması ... 40
4.2.1.8. IB1 Algoritması ... 40 BÖLÜM 5 ... 42 LİTERATÜR İNCELEMESİ ... 42 BÖLÜM 6 ... 54 UYGULAMA ... 54 6.1. PROBLEMİN TANIMLANMASI... 54 6.2. MATERYAL VE METOT ... 55
6.3. VERİNİN VE DEĞİŞKENLERİN TANIMLANMASI ... 55
6.4. VERİLERİNİN MODELE HAZIRLANMASI ... 56
6.4.1. Verinin Temizlenmesi ve Birleştirilmesi ... 57
6.4.2. Verinin Dönüştürülmesi ve Boyut İndirgeme... 58
BÖLÜM 7 ... 60
BULGULAR ... 60
xi
Sayfa
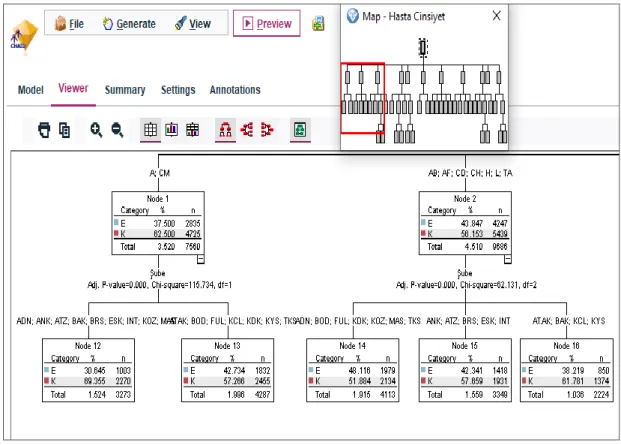
7.1.1. Chaid ve Quest Karar Ağacı Algoritmaları ile Hasta Cinsiyet
Değişkeninin Analizi ... 65
7.1.1.1. Chaid Algoritması ile Hasta Cinsiyet Değişkenine Etki Eden Alt Değişkenlerin Analizi ... 66
7.1.1.2. Quest Algoritması ile Hasta Cinsiyet Değişkenine Etki Eden Alt Değişkenlerin Analizi ... 74
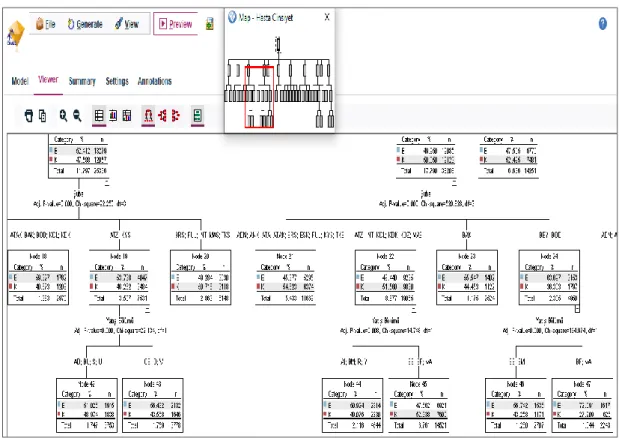
7.1.2. C5.0, Chaid ve Quest Karar Ağacı Algoritmaları ile Hasta Şube Seçimi Değişkeninin Analizi ... 80
7.1.2.1. C5.0 Algoritması ile Hasta Şube Seçimi Değişkenine Etki Eden Alt Değişkenlerin Analizi ... 81
7.1.2.2. Chaid Algoritması ile Hasta Şube Seçimi Değişkenine Etki Eden Alt Değişkenlerin Analizi ... 93
7.1.2.3. Quest Algoritması ile Hasta Şube Seçimi Değişkenine Etki Eden Alt Değişkenlerin Analizi ... 100
BÖLÜM 8 ... 111
SONUÇ VE ÖNERİLER ... 111
xii
ŞEKİLLER DİZİNİ
Sayfa
Şekil 2.1. Yıllara göre hastane sayıları ... 4
Şekil 2.2. Yıllara göre hastanelerdeki hasta yatak sayısı ... 4
Şekil 2.3. 2017-2018 yılları sağlık hizmetlerinde hasta memnuniyet oranının uluslararası karşılaştırılması ... 7
Şekil 2.4. Sağlık hizmetlerinde memnuniyet oranı, kişi başı kamu cari sağlık harcaması ... 8
Şekil 2.5. Sağlık hizmetlerinde memnuniyet oranı, kişi başı toplam cari sağlık harcaması ... 9
Şekil 2.6. Türkiye 2010- 2019 yılları arası sağlık harcamaları ... 11
Şekil 2.7. 2002- 2016 yılları arasında yatan hasta, yatak devir hızı, ortalama kalış gün süresi ... 11
Şekil 2.8. 2015- 2019 yılları arası 1.000 kişi başına düşen hasta yatak sayısı ... 12
Şekil 2.9. 2015- 2019 yılları arası hastaların hastanede ortalama kalış süresi ... 13
Şekil 3.1. Farklı kaynaklardan gelen verilerin ilişkilendirilmesi ... 23
Şekil 3.2. Veri madenciliği aşamaları ... 24
Şekil 4.1. Kümeleme yöntemleri ... 30
Şekil 4.2. Yapay sinir ağı örneği ... 36
Şekil 4.3. Yapar sinir ağı yapısındaki katmanlar... 37
Şekil 4.4. Yapay sinir ağı yapısı ... 38
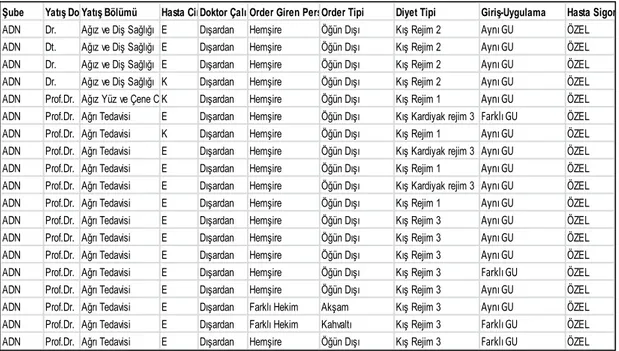
Şekil 6.1. İşlenmemi veriden ekran görüntüsü ... 54
Şekil 6.2. Karar ağacı analizine hazır veri setinin ekran görüntüsü ... 57
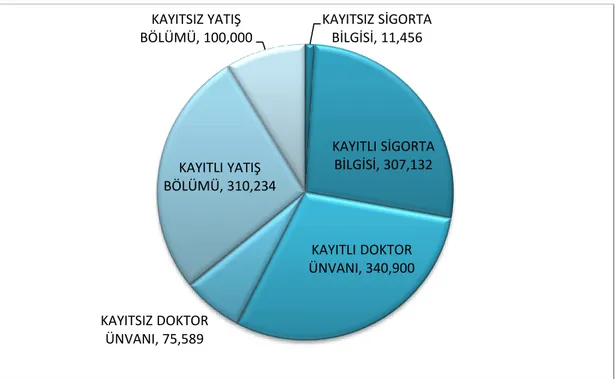
Şekil 6.3. Veri setinde bulunan kayıtlı ve kayıtsız veri sayıları ... 58
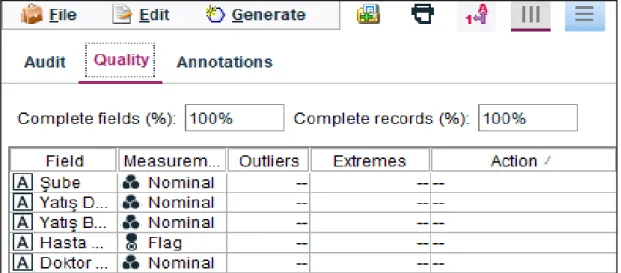
Şekil 6.4. Modelde aykırı uç değerin olmadığına dair ekran görüntüsü ... 59
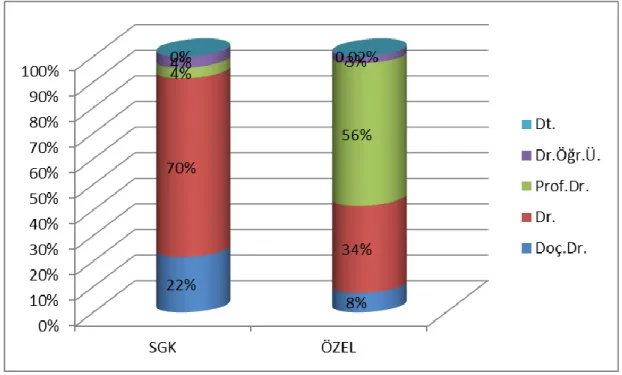
Şekil 7.1. Hasta sigorta giriş bilgisinin cinsiyete göre dağılımı ... 61
Şekil 7.2. Hasta sigorta giriş bilgisinin yatış yapan doktor ünvanına göre dağılımı 62 Şekil 7.3. Hasta sigorta yatış bilgisinin şubelere göre dağılımı ... 63
Şekil 7.4. Hasta yoğunluklarını gösteren grafik ... 64
Şekil 7.5. IBM SPSS Modeler veri madenciliği ekran görüntüsü ... 65
xiii
Sayfa
Şekil 7.7. Hasta cinsiyeti değişkeni ile Chaid algoritmasında oluşan ilk dal ... 67
Şekil 7.8. Hasta cinsiyetinin şube ve yatış bölümlerine göre dağılımı ... 68
Şekil 7.9. Şube değişkeninin hasta cinsiyet değişkenine etkisinin dağılımı ... 69
Şekil 7.10. Hasta cinsiyetinin şube ve yatış bölümlerine göre dağılımı ... 70
Şekil 7.11. Karar ağacı modelinde hasta cinsiyet değişkenine etki eden alt değişkenlerin dağılımı ... 71
Şekil 7.12. Hasta cinsiyeti bilgisi değişkenine etki eden değişkenlerin oluşturduğu karar ağacındaki dallanma ... 72
Şekil 7.13. Hasta cinsiyeti değişkenine etki eden değişkenler ... 73
Şekil 7.14. Hasta cinsiyeti değişkeni için Quest algoritmasında oluşan ilk dal ... 74
Şekil 7.15. Hasta cinsiyetinin yatış bölümlerine göre dağılımı ... 75
Şekil 7.16. Hasta cinsiyet değişkeni için Quest algoritmasında oluşan dallanma ... 76
Şekil 7.17. Hasta cinsiyeti bilgisi değişkenine etki eden değişkenlerin oluşturduğu karar ağacındaki dallanma ... 77
Şekil 7.18. Hasta cinsiyet değişkenine etki eden değişkenler ... 78
Şekil 7.19. Chaid ve Quest algoritmalarının sonucunu karşılaştıran grafik ... 79
Şekil 7.20.Sınıflayıcı algoritmaların karşılaştırılmasında modelin doğruluk oranları80 Şekil 7.21. C5.0 algoritması sonucu oluşan modelin ekran görüntüsü ... 82
Şekil 7.22. Şube değişkenine etki eden alt değişkenlerin C5.0 algoritmasında oluşturduğu dallanma ... 82
Şekil 7.23. C5.0 algoritması ilk dallanmanın ekran görüntüsü ... 83
Şekil 7.24. C5.0 algoritmasında şube değişkeninin yatış bölümlerine göre dağılımı 84 Şekil 7.25. Şube değişkeni için C5.0 algoritmasında oluşan dallanma ... 85
Şekil 7.26. Şube değişkeninin yatış bölümü ve yatış doktor ünvanına göre dağılımı 85 Şekil 7.27. Şube değişkeninin yatış bölümü ve hasta sigorta bilgisine göre dağılımı 86 Şekil 7.28. C5.0 algoritmasında şube değişkeninin yatış bölümü ve yatış doktor ünvanına göre dağılımı ... 87
Şekil 7.29. Şube değişkeninin yatış bölümü ve yatış doktor ünvanına göre dağılımı 88 Şekil 7.30. Şube değişkeninin yatış bölümü ve hasta cinsiyetine göre dağılımı ... 88
Şekil 7.31. Şube değişkeninin yatış bölümü, yatış doktor ünvanı ve hasta sigorta bilgisine göre dağılımı ... 89
Şekil 7.32. Şube değişkeninin yatış bölümü, hasta sigorta bilgisi ve yatış doktor ünvanına göre dağılımı ... 90
Şekil 7.33. Şube değişkenine etki eden alt değişkenlerin dağılımı ... 91 Şekil 7.34. Şube değişkeninin yatış bölümü ve yatış doktor ünvanına göre dağılımı 92
xiv
Sayfa
Şekil 7.35. IBM SPSS Modeler ekran görüntüsü ... 93
Şekil 7.36. Matris metodu ekran görüntüsü ... 94
Şekil 7.37. Şube değişkeni ile Chaid algoritmasında oluşan ilk dal ... 95
Şekil 7.38. Şube değişkeninin yatış bölümlerine göre dağılımı ... 96
Şekil 7.39. Şube değişkeni için Chaid algoritmasında oluşan dallanma ... 96
Şekil 7.40. Şube değişkeni için Chaid algoritmasında oluşan dallanma ... 97
Şekil 7.41. Şube değişkeninin hasta cinsiyetine göre dağılımı ... 98
Şekil 7.42. Şube bilgisi değişkenine etki eden alt değişkenlerin oluşturduğu karar ağacındaki dallanma ... 99
Şekil 7.43. Şube değişkenine etki eden alt değişkenler ... 100
Şekil 7.44. Şube değişkeni ile Quest algoritmasında oluşan ilk dal ... 101
Şekil 7.45. Şube değişkeninin Quest algoritmasında yatış bölümlerine göre dağılımı ... 102
Şekil 7.46 Şube değişkenine Quest algoritmasında alt değişkenlerin dağılımı ... 103
Şekil 7.47. Quest algoritmasında şube değişkenine etki eden hasta sigorta bilgisinin dağılımı ... 104
Şekil 7.48. Şube değişkenine etki eden yatış bölümü ve hasta sigorta bilgisinin dağılımı ... 105
Şekil 7.49. Şube değişkenin yatış bölümüne göre dağılımı ... 106
Şekil 7.50. Şube değişkenin yatış bölümü ve hasta sigorta bilgisine göre dağılımı . 107 Şekil 7.51. Şube değişkenine etki eden alt değişkenlerin karar ağacı dallanması .... 108
Şekil 7.52. Şube değişkenine etki eden alt değişkenler ... 109
xv
ÇİZELGELER DİZİNİ
Sayfa
Çizelge 2.1. Sağlık sektöründe iç ve dış müşteriler ... 10
Çizelge 2.2. Veri madenciliği hakkında doğru ve yanlış bilinenler ... 16
Çizelge 2.3. Veri madenciliği uygulama alanları ... 20
Çizelge 3.1. Veri madenciliği yöntemlerini oluşturan algoritmalar ... 26
Çizelge 4.1. Veri madenciliği modelleri ... 28
Çizelge 7.1. Cinsiyet değişkenine göre veri setinin dağılımı ... 60
1 BÖLÜM 1
GİRİŞ
Sağlık sektörü, sağlığa etkileri olan ürünleri arz - talep etmek, tüketmek üzere farklı üretim sahalarında kurulmuş bütünleşik sistemler ile bunların içerdiği kişi, kurum, ürün ve benzerlerini belirtmek amacı ile kullanılan kavramlar bütünüdür.
Türkiye’de sağlık hizmetleri Cumhuriyet’in kuruluşu 1923 yılından itibaren 1982 yılına kadar devletin sunması esas alınan bir hizmet olmuştur. Türkiye’de kamu dışında hizmet sunan sağlık kuruluşlarının yüksek oranda artış göstermesi ve özel sağlık sigortası için sağlık alanının gelişmesinin yaşandığı yıllar 1900’lerdir. Türkiye’de sağlık sektörü, 1980’lerden sonra 20 yılda ortalama üç kat büyüme göstermiş ve kamu sektörünün payı gün geçtikçe daha da belirleyici olmuştur [1]. Türkiye Sigorta Birliği’nin (TSB), 2020 yılını kapsayan verilerine göre yılın dokuz ayında sektörün %22,4 oranında büyüdüğü açıklanmıştır.
Sağlık sektöründe günümüz teknolojisi ile verilerin kayıt altına alınması süreci gelişmiş olmasına karşın, eldeki verilerden faydalı sonuç çıkarma aşaması yetersiz kalmaktadır. Büyük verilere sahip kurumlarda istatistiki yöntemler aracılığı ile ulaşılması amaçlanan çalışmalarda ihtiyacı karşılayacak değerli verilere ulaşılamamaktadır. Bu doğrultuda, hizmet sektöründe büyük ölçekli olarak tanımlanan verilerin analizi ile anlam kazandırılması aşamasında yazılım programlarına ihtiyaç duyulmaktadır. Veri madenciliği, sunduğu yazılım altyapısı ile birlikte bu süreçte önemli bir boşluğu doldurmaktadır.
Veri madenciliği, büyük ve karmaşık verilerin analizi sonucunda ihtiyacı karşılayarak ilgili tahminde bulunulmasını sağlayan değerli verilerin elde edilmesidir. Verileri çözümlemede istatistik çoğu zaman yeterli olsa da büyük ve karmaşık verilerin çözümlenmesinde veri madenciliğine ihtiyaç duyulmaktadır. Bu nedenle veri
2
madenciliği teknikleri, var olan veriyi çözümleme ve tamamlamada günümüz teknolojisiyle önem kazanmıştır.
Veri madenciliği çalışmaları sürecinde, veri setinin gerçek problemin çözümünü sağlayacak nitelikte olması analiz aşamasında önem taşımaktadır. Problemin çözümünde kullanılacak veri setinin büyüklüğü ve değişkenlerin çokluğu gerçekleştirmek istenilen çalışmanın önemini arttırmaktadır.
Veri madenciliği yöntemleri ile aynı çalışmanın veri setinden farklı sonuçlar elde etmek mümkündür. Veri madenciliğinin yöntemlerinde, veri seti için en uygun olanı belirlemek, analizin ilk aşamasında en çok dikkat edilmesi gereken süreçtir. Birden fazla tekniğin veri seti için uygun olduğu durumlarda, her bir tekniği deneyerek en doğru sonuca varılmaktadır.
Tez çalışmasının ikinci bölümünde, sağlık sektöründe veri madenciliğinin ne gibi problemleri çözmeye odaklanıldığı açıklanmış ve bu doğrultuda kullanılan yöntemler aktarılmıştır. Üçüncü bölümde veri madenciliği aşamaları anlatılarak, problemin belirlenmesinin ardından çalışmada izlenilecek yol belirtilmiştir. Dördüncü bölümde veri madenciliği modelleri anlatılarak, bu doğrultuda çalışmada uygulanacak modeller açıklanmıştır. Beşinci bölümde, literatür araştırması yapılarak, veri madenciliği yöntemi ile çalışılan farklı akademik çalışmalar hakkında bilgi verilmiştir. Altıncı bölümde, mevcut çalışmadaki problem belirtilmiş ve veri seti işlemeye uygun hale getirilmiştir. Yedinci bölümde veriler üç farklı algoritma ile işlenerek sonuçları karşılaştırılmış ve son bölümde de çalışmanın sonuçlanmasının ardından öneriler sunulmuştur.
3 BÖLÜM 2
VERİ MADENCİLİĞİ
2.1. SAĞLIK SEKTÖRÜ KAVRAMI VE ÖNEMİ
“Sağlık sektörü” sağlığa dolaylı ya da doğrudan etkisi olan, hizmet veya mal amaçlı talep edilen ürünü üretmek ve tüketmek üzere birbirinden farklı alanlarda kurulmuş olan sistem ve bunlara bağlı alt sistemler ile, kurumun bünyesinde var olan kişi, kuruluş, ürün ve benzerlerini ifade etmek için kullanılan kavramlar bütünüdür [2].
Sağlık sektöründe yer alan kurumlar, yapısal ve işlevsel olarak sınıflandırıldığında en kompleks yapıya sahip örgütler arasında yer almaktadır. Yönetimden alt kademeye kadar çeşitlilik gösteren her düzeydeki personel, sofistike ve çok pahalı teçhizat, insan sağlığı ile ilgili faaliyetler ve ortaya çıkan stres gibi özellikleriyle sağlık işletmeleri, yapısında pek çok ekibi barındıran organizasyonlardır [3]. Sağlık sektöründe hastaya verilen hizmet, ülkelerin sosyo-ekonomik düzeylerini belirleyen önemli bir göstergedir. Sağlık kuruluşlarında hizmet sunulan toplumun sağlık ihtiyaçlarının doğru analiz edilmesi ve hastaların memnun edilmesi kurumsal başarı ve rekabet gücü açısından kaçınılmazdır [4].
Sağlık sektörü, çözümcül yaklaşım ve gelişim odaklı olma zorunluluğu içerisinde mevcut hizmet sektörlerinin en başında yer almaktadır. Birey sağlığı başlıca odak noktası olmasının yanı sıra devletin katkısı ve özel sağlık kuruluşlarının finansman gücünü korumaya çalışması da kurumların önemli hedefleri arasında yer almaktadır. Bu doğrultuda özel sağlık kurumları, faaliyetlerini ve gelişim çalışmalarını arttırarak sağlık sektöründeki payını her geçen gün büyütmektedir.
Sağlık sektörüne ait son istatistiki veriler 2018 yılı Sağlık Bakanlığı tarafından yayınlanmıştır. Bu veriler incelendiğinde, 2002 yılından 2018 yılına kadar sağlık
4
sektöründe önemli gelişimler gözlendiği görülmektedir. Şekil 2.1.’de 2002- 2018 yılları arasında yıllara hastane sayıları verilmektedir.
Şekil 2.1. Yıllara göre hastane sayıları [5].
Şekil 2.1.’de görüldüğü gibi 16 yıllık periyotta hastane sayılarında her geçen gün artış olduğu sonucuna varılmaktadır. Bu artışa en büyük katkı, özel sağlık kuruluşları tarafından olmuştur. 2014 yılından itibaren özel sağlık hizmetlerinin tüm sağlık kuruluşlarındaki payını önemli derecede arttırdığı görülmektedir. Şekil 2.2.’de yıllara göre hastane yatak sayısı verilmektedir.
5
Hastane sayısındaki artış, aynı oranda hastane yatak kapasitesinde de görülmektedir. Bu artış ile arz- talep dengesinin uyumlu bir çizgide seyrettiği sonucuna varılmaktadır. Müşteri taleplerinin doğrultusunda hastane açılması ile birlikte kapasite arttırımına en çok özel sağlık kurumlarında ihtiyaç duyulduğu görülmektedir.
Türkiye’de sağlık hizmeti sunan kurumların tarihsel sürecine, çeşitli kurumlar tarafından sunulan ve analiz edilen yıllara yaygın göstergelere bakıldığında giderek özel sektörün piyasadaki payını arttırdığı sonucuna varılmaktadır. Özellikle son dönemde “Sağlıkta Dönüşüm Programı” adı altında sunulan yeni politikalar ile özel sektör ve kamu arasındaki iş birliği sistemi ile özel sektörü teşvik edici atılımlar görülmektedir. Türkiye’nin her geçen gün sağlık sektörüne talebi daha da artmaktadır. Bunların sonucunda, özel sektöre doğru aktarılan bu fonun ve teşvik edici girişimlerin iyi planlanması ve etkin bir şekilde kullanımını zorunlu kılmaktadır [6].
2.1.1. Sağlık ve Sağlık Hizmetleri Kavramı
Bireylerin, toplumla uyum içinde yaşamaları için bazı şartların yerine getirilmesi gerekmektedir. Bu şartlar başlıca; tedavi hizmetleri, güvenilir konut, dengeli beslenme, eğitim, sosyal refah, ekonomik kalkınma, gelir düzeyi gibi konular olarak sıralanabilir. Bu sıralamada ilk sırayı sağlık hizmetleri almaktadır. Çünkü beşeri ihtiyaçlarının başında biyolojik ihtiyaçlar, biyolojik ihtiyaçların başında ise “sağlıklı olma” ihtiyacı gelmektedir [7].
Dünya genelinde sağlık hizmetleri, hasta bireyin tedavisi olarak yorumlanmaktadır. Günümüz dünyasında farklı hastalıkların yayılması, bulaş riski yüksek olan hastalıkların tespiti, hijyen ve çevre sağlığı konusundaki gelişmelerin artması nedeni ile sağlık hizmetleri farklı bir boyut kazanmıştır. Birey sağlığının toplum sağlığı ile örüntülü olduğu tanısına varılarak, koruyucu sağlık hizmetlerine de daha fazla önem verilmeye başlanmıştır [8].
Hizmet üretimi ve pazarlaması içerisinde yer alan sağlık hizmetleri, genel olarak bireyin sağlığının korunması, eğer hasta ise tedavisi için gerekli çalışmaların yapılması olarak tanımlanmaktadır [9]. Sağlık hizmetleri; hasta bireyin hastalığının teşhis, tedavi
6
ve rehabilitasyonu yanında, mevcut hastalıkların önlenmesi, toplumun ve bireyin sağlık düzeyinin geliştirilmesine yönelik gerçekleştirilen tüm faaliyetler olarak da tanımlanmaktadır [10].
Sağlık hizmetleri kavramının anlaşılması için öncelikle sağlık ve hastalık kavramının birbirinden ayrılması gerekmektedir. Günümüzde sağlık kavramı, bireyin hasta olmama durumu olarak tanımlandığından dolayı, hastalık kavramı ön planda olmuş ve toplumun sağlıklı olup olmama durumu da bu sonuca bağlanmıştır. Hastalık ve sağlık kavramındaki farklı görüşler doğrultusunda tıp çevresi konuya ilişkin birbirinden ayırmaya yönelik bir tanım yapmayarak, sağlık kavramını hastalık tanımı ile neticelendirmek zorunda kalmışlardır [8].
Sağlık kavramı ile ilgi yapılan ve en kabul gören tanım, Dünya Sağlık Örgütü tarafından yapılmıştır. Dünya Sağlık Örgütü’nün sağlık tanımı, sağlık sadece hastalığın bulunmaması değil bedensel, ruhsal ve sosyal yönden tam bir iyilik halidir.” Bu tanımdan yola çıkarak, sağlık hizmetlerindeki amacın sadece bedenen hasta bireylere hizmet vermek olmadığı anlaşılmaktadır.
2.1.2. Sağlık Hizmetlerinde Hasta Memnuniyeti ve Kalite Kavramı
Kalite, hizmet ve hizmet kalitesi kavramlarını bir bütün olarak kabul görecek şekilde tanımlamak oldukça zordur. Kalitenin Uluslararası Standartlar Teşkilatı (ISO) tarafından yapılan tanımı, bir mal veya hizmetin belirli ihtiyaçları karşılayabilme yeteneklerini ortaya koyan karakteristiklerin tümüdür” şeklindedir.
Hizmet kalitesinin en önemli ölçütü, tüketici veya müşteri olarak adlandırılabilir. Müşteri beklentisi karşılandığı durumlarda yüksek kalite, tüketicinin beklentisinin altında kalması durumunda ise düşük kalite olarak kategorize edilmektedir [11]. Bu kalite kavramının verimli ölçüde sağlanması için müşterinin beklentisi doğru analiz edilerek, beklentiye yönelik çalışmalar yapılması gerekmektedir.
Sağlık sektöründe kaliteyi belirleyen en önemli kriter hastanın gelmeden önce ve geldikten sonraki beklentilerinin doğru analiz edilmesidir. Bu hususta sağlık
7
hizmetlerinde kalite kavramı, tedavi ve hizmet kalitesi olarak iki farklı açıdan değerlendirilmesi gerekmektedir [11].
Sağlık sektöründe verilen hizmet kalitesi %100 güvenilirliğe sahip olması gerekmektedir. Sağlık sektöründe hizmet vermekte olan kurum veya bireyin yapmış olduğu hata ölümcül sonuçlara neden olabilmektedir. Bu doğrultuda düşünüldüğünde sıfır hata hedef gösterilmelidir [12].
Sağlık sektöründeki bir işletmenin varlığını devam ettirebilmesi, hasta memnuniyeti ile doğrudan ilişkilidir. Hizmet kalitesi ne kadar yüksek olursa, bireyin aynı oranda sağlık ekibine karşı güveni artarak, verilen önerilere uyma olasılığı yükselmektedir. Beklentilerinin karşılandığı kurumu tekrar tercih etmesi bu hususta önemlidir. Şekil 2.3.’te OECD Türkiye 2018, AB ülkeleri 2017 verilerine göre sağlık hizmetlerinde hasta memnuniyet oranının uluslararası karşılaştırması verilmektedir.
Şekil 2.3. 2017-2018 yılları sağlık hizmetlerinde hasta memnuniyet oranının uluslararası karşılaştırılması [13].
OECD 2018 verilerine göre hasta memnuniyetinin değerlendirildiği araştırmanın sonucunda Türkiye 36 ülke arasında 27. sırada yer almaktadır. Hizmet sektöründe her geçen gün müşteri memnuniyetini hedef göstererek yapılan çalışmalarda OECD
8
ortalamasının altında kalmayarak, yükselişte olduğu görülmektedir. Şekil 2.4.’te OECD verilerine göre AB ve Türkiye açısından hasta memnuniyeti ile kişi başı kamu cari ve toplam cari sağlık harcamaları grafiği verilmektedir. OECD verilerine göre Türkiye harcama verisi 2018 yılına aittir, ülkelere ait harcama verileri 2017 yılına veya en yakın yıla aittir.
Şekil 2.4. Sağlık hizmetlerinde memnuniyet oranı, kişi başı kamu cari sağlık harcaması [13].
OECD hasta memnuniyet istatistiklerine göre Türkiye %70 memnuniyet oranına sahip olduğu ve kişi başına kamu cari sağlık harcamasının 914 ABD doları olduğu görülmüştür. En yüksek %90 oran ile hasta memnuniyetine sahip olan Hollanda, kişi başı kamu cari sağlık harcaması 4.204 ABD dolarıdır.
9
Şekil 2.5. Sağlık hizmetlerinde memnuniyet oranı, kişi başı toplam cari sağlık harcaması [13].
OECD verilerine göre, kişi başı toplam cari sağlık harcamasında Türkiye 1.181 ABD doları ile OECD ortalamasının altında kalmaktadır. En fazla kişi başı toplam cari sağlık harcamasına sahip olan ülke 10.207 ABD doları ile Birleşik Devletler’dir.
Hasta memnuniyetindeki olumlu artışta yönetim kadrosundan hizmet veren personellere dek ekip çalışması etkili olmaktadır. Dikkat edilmesi gereken husus müşteri profilinin doğru analiz edilmesidir. Hizmet sektörünün çoğunluğunda olduğu gibi sağlık sektöründe de müşteri kavramı iç ve dış müşteri olmak üzere ikiye ayrılmaktadır. İç müşteriler, kurumda çalışan ve sağlık ile ilişkisi olan bireyler, dış müşteriler kuruma hizmet almak için gelen bireyler olarak sınıflandırılmaktadır.
Çizelge 2.1.’de sağlık hizmet sektöründe iç ve dış müşteriler iki başlıkta kategorize edilmiştir.
10
Çizelge 2.1. Sağlık sektöründe iç ve dış müşteriler [14].
Dış Müşteriler İç Müşteriler
Hastalar, hasta ailesi ve çevresi Teknik personel ve destek personeli Refakatçiler, ziyaretçiler Sağlık profesyonelleri
Devlet Kurum personelleri (Hemşire, hekim vb.)
Diğer sağlık kurumları Üst ve orta kademe yöneticileri
Anlaşmalı kuruluşlar Pay sahipleri
Eczaneler Danışmanlar
Dernekler
Medya
Sigorta şirketleri
Tıbbi malzeme ve ilaç firmaları
İnşaat şirketleri
Çamaşırhane işletmeleri
Çiçek satıcıları
Müteahhitler
Kalite odaklı hastane yönetimi, hasta memnuniyeti ve sağlık sektöründe iç müşterinin pazar payını arttırmasında büyük role sahiptir. Sağlık sektöründe hastanelerin sayısındaki yükseliş rekabet ortamına yol açarak, kaliteye verilmesi gereken önemin arttırılmasına öncülük etmiştir.
Sağlık sektörü, toplum için hayati önem taşıyan bir sektör olmasından dolayı, sürekli gelişen teknoloji ile birlikte mevcut durumun değerlendirilmesi, iyileştirilmesi ve çözüme kavuşturulması oldukça önemlidir.
Dünya ekonomisine bakıldığında, günümüzde sağlık sektörü ilk sıralarda yer almaktadır Sağlık sektörü için 1990’lı yıllarda yapılan toplam harcama yaklaşık 2985 milyar dolar olduğu bilinmektedir. Bu harcama dünya brüt milli hasılasının ortalama %8’ine denk geldiği görülmektedir [1]. Toplam sağlık harcamaları 2019 TÜİK (Türkiye İstatistik Kurumu) son verilerine göre, 201 milyar 31 milyon TL olarak açıklanmıştır. Özel sağlık sektöründeki bu oran, 44 milyar 212 TL olarak belirtilmektedir.
11
Şekil.2.6. Türkiye 2010- 2019 yılları arası sağlık harcamaları [15].
Sağlık sektöründe performans kısıtlarını belirlemeden önce yapılması gereken, sağlık sisteminin tanımının açıklayıcı bir şekilde vurgulanması ve bu doğrultuda istenilen ölçütlerin sınırlarının belirlenmesidir.
Türkiye’de kişi başına düşen sağlık kuruluşuna başvuru sayısı giderek artış göstermektedir. Hastalık anında ilk tercih edilen sağlık kuruluşları talebin yönünü belirleyici etkendir. Talep doğrultusunda kamu hastanelerinde yaşanan yoğunluk, yatak sayısının artışını aynı doğrultuda yönlendirmektedir. Kamu Hastaneleri Genel Müdürlüğü tarafından genel istatistik bilgileri raporlanmış olup, yatak devir hızının ortalama kalış süresi ve yatak sayısı ile ilişkisi şekil 2.7.’de belirtilmiştir.
12
Şekil 2.7. 2002- 2016 yılları arasında yatan hasta, yatak devir hızı, ortalama kalış gün süresi [16].
Yatan hasta sayısında yıl bazında artış olduğu tespit edilmiştir. Hasta yoğunluğunun fazla olması ile ters orantılı olarak hastaların ortalama kalış sürelerinde aynı oranda azalma görülmektedir.
Dünya geneline bakıldığında sağlık sektöründe, memnuniyet derecesini arttırmak ve daha kaliteli, hızlı hizmet vermek adına birçok adım atılmaktadır. Sağlık sektöründe büyük verilerin işlenip kullanımı, analiz edilmesi ilk ön planda olan uygulamalardandır. 2015 yılından 2019 yılına kadar 1.000 kişi başına düşen toplam hasta yatak sayısını analiz eden OECD (Ekonomik İş birliği ve Kalkınma Örgütü) verileri Şekil 2.8.’de belirtilmiştir.
Şekil 2.8. 2015- 2019 yılları arası 1.000 kişi başına düşen hasta yatak sayısı [17].
Şekil 2.8.’de de görüldüğü gibi Türkiye kişi başına düşen hasta yatak sayısında 42 ülke arasında 30. sırada yer almaktadır. Japonya yatak sayısı oranında birinci sırada, son sırada ise Hindistan olduğu görülmektedir.
13
Şekil 2.9.’da OECD (Ekonomik İş Birliği ve Kalkınma Örgütü) tarafından belirtilen hastanın hastanede ortalama kalış süreleri ülke bazından verilmektedir.
Şekil 2.9. 2015- 2019 yılları arası hastaların hastanede ortalama kalış süresi [17].
2015- 2019 yılları arasını baz alan verilerde, Türkiye’nin 34 ülke arasında oran bakımında 4.1 gün olduğu belirtilmektedir. En fazla gün oranına sahip ülke 16.1 gün ile Japonya’dır.
Hastanede yatış süresi sağlık sektöründe verimlilik göstergesi olarak kullanılmaktadır. Diğer tüm değişkenler eşit kabul edildiğinde, daha kısa yatış süresi, taburculuk başına maliyeti azaltacaktır. Hastanede ortalama kalış süresi, genelde bir yıl boyunca tüm yatan hastaların kaldıkları toplam gün sayısına bölünmesiyle ölçülmektedir. Günlük vakalar bu ortalamadan hariç tutulmaktadır.
OECD ve benzeri birçok kuruluşlarda sağlık sektörünün gelişimine katkı sağlayacak veri setleri mevcuttur. Dünya genelinde yapılan bu gibi çalışmalarda analiz aşamasının oldukça karmaşık ve büyük olacağı muhtemeldir. Veri seti analizinde güvenilir sonuca ulaşmada ilk aşama verilerin doğru tanınması ve yorumlanmasıdır. Analiz aşamasında verimli bilgiye ulaşılması, verinin büyüklüğü ve yeterliliği ile ilişkilidir. Büyük ve
14
karmaşık yapıdaki veri setlerinde istatistik yöntemlerinin kullanımı sınırlıdır. Karşılaşılan bu gibi durumlarda veri madenciliği yöntemlerine ihtiyaç duyulmaktadır.
2.2. VERİ MADENCİLİĞİ KAVRAMI VE SAĞLIK SEKTÖRÜNDE VERİ MADENCİLİĞİ
Dijital ortamda işlenmemiş ham bilgiye veri denilmektedir. Bilgilerin dijital programlar aracılığı ile işlenerek formülize edilmiş şekli de veri olarak adlandırılmaktadır. Verilere ulaşmak, ölçüm ya da gözlem sonucunda bilgilerin kayıt altına alınması yolu ile mümkündür. Elde edilen büyük ölçekli verilerin anlam kazanması ve analiz edilmesi veri madenciliği ile sağlanmaktadır [18].
Dijitalleşmede bilginin sayısallaştırılarak formülize edilmesi söz konusudur. Bu nedenle, kayıt sistemleri ve gittikçe artan etkileşim sistemleri ile ilgilidir. Dijitalleştirme, formülize edilmiş veri ve akış halindeki prosesten yararlanarak, müşterileri ve müşterilerin tercihlerini belirlemek amacıyla, kayıt sistemlerinin ortak kaynaklarından elde edilen verilerin tüketimini, toplanmasını ve bu verilerin analizini yaparak müşteri deneyimini desteklemeyi ve tercihleri doğrultusunda yenilikler sunmayı amaçlayan teknolojiyi ifade eden içgörü sistemleri oluşturmakla ilgilidir [19].
Dijital ortamda tutulan büyük veri yığınlarının birbirleri ile ilişkilendirerek, gelecekle ilgili tahminde bulunulması doğrultusunda gerekli algoritmalara başvurulması aşamasına veri madenciliği denir. Veri madenciliği, mevcut verinin daha öncesinde keşfedilmemiş bilgilerinin belirli istatistiki yöntemler aracılığı ile ortaya çıkarılmasıdır. Veri madenciliği genel anlamıyla, veriler arasında olan örüntülerin farklı algoritmalar aracılığı ile tespit edilmesidir [20].
Veri, doğru bir şekilde analiz edildiğinde kuruma verimli bilgi sağlama gücüne sahiptir. Bilgi, her şeyin dijitaleştiği teknoloji dünyasında, ancak makineler tarafından işlenebilen dijital verilerin varlığı nedeniyle mümkün olan güç olarak düşünülebilir. Sektörler, pazar araştırması ve farklı anketleri yapmaları için ihtiyaç duydukları maksimum geliri, olumlu ve olumsuz yönlerini bulmak için analiz etmek istemektedir. Veri madenciliği, müşterilerini anlamalarına ve kullanıcıların ihtiyaçlarını karşılamak
15
için hizmetlerini geliştirmelerine yardımcı olacak büyüme ve eğilimlerini anlamalarını sağlar.
Sumathi ve Sivanandam’ın veri madenciliği ile ilgili tanımları aşağıdaki gibidir [21]:
• Veri madenciliği: Değerli iş verilerindeki ilişkileri ve yeni durumları otomatik araştırmasıdır.
• Veri madenciliği: Geniş veri tabanlarında önceden bilinemeyen değerli ve kullanışlı bilginin ortaya çıkarılması ve kritik iş kararlarında kullanılması sürecidir.
• Veri madenciliği: Veri tabanlarında anlaşılır model ve örüntüleri ortaya çıkaran tümevarımdır.
Veri madenciliği, öncesinde keşfedilmemiş büyük boyutlu verilerden faydalı bilgilere ulaşmayı amaçlayan operasyonlar anlamı taşımaktadır. Birbiriyle ilişkili olmayan verilerin entegrasyonunu sağlayarak ilişkilendirmek veri madenciliği algoritmaları ile mümkündür. Bu yönüyle birçok kamu ve özel sektörde tercih edilmesinin yanı sıra müşteri analizinde de önemli yere sahiptir. İşletmelerde veri madenciliği oluşum adımları doğru takip edilip kurulduğu takdirde, verimli sonuçlar alınarak çeşitli projelerin oluşumunda etkili olmaktadır [18].
Büyük veri setlerinden anlamlı bilgileri gruplamaya yönelik istatistiki veriler çıkaran veri madenciliği yöntemleri, mevcut verileri sorgulama ve raporlama olarak değerlendirilmemelidir.
Veri madenciliği ile ulaşılmak istenen sonuç, karmaşık veri setinden faydalı analizler çıkarmaktır. Veri setini sorgularken amacın, mevcut veriden ayrıntılı bilgi araştırmak olduğu düşünülmemelidir. Aynı doğrultuda sadece regresyon analizi yaparak gelir ve cinsiyet arasındaki bağlantıyı analiz etmek veri madenciliği olarak değerlendirilmemelidir [26].
Çizelge 2.2.’de veri madenciliği hakkında doğru ve yanlış bilinenler maddeler halinde aktarılmıştır.
16
Çizelge 2.2. Veri madenciliği hakkında doğru ve yanlış bilinenler [23].
Veri Madenciliği Hakkında Doğru
Bilinenler Veri Madenciliği Hakkında Yanlış Bilinenler
İnternetten ayrıntılı bilgi araştırmak
İnternette aynı içerikteki benzer bilgileri gruplamak Aynı hastalığa sahip hasta sayılarını
sorgulamak Benzer semptonlar görülen aynı hastalığa sahip hastaları gruplamak Yer listesinden termal otellerin yerini
sorgulamak Termal otelleri, hangi hastalığın tedavisi ile ilgili olduğuna göre gruplamak Şirketlerin finansal raporlarından tabloları
analiz etmek Şirketlerin satış ile ilgili veri tabanlarından müşteri profillerini ortaya çıkarmak
Veri madenciliğinde amaç, mevcut veriyi düzenlemek değil, var olan veri setinden anlamlı analizler çıkararak farklı bir bakış açısı ve çözüm yolu sağlamaya çalışmaktır.
Veri madenciliğinin amacını doğru kavramak, çalışmada izlenmesi gereken yolun seçiminde ve verimli sonuca varılması konusunda oldukça fazla önem taşımaktadır. Birçok farklı algoritma içeren veri madenciliği yöntemlerinde, uygun algoritmayı belirlemenin ve sonrasında karşılaşılacak problemleri minimuma indirmenin en önemli aşaması veri madenciliğini doğru tanımak ve neticesinde mevcut veriye uygun algoritma belirlemek ile mümkündür.
2.2.1. Veri Madenciliğini Etkileyen Faktörler
Veri Madenciliğini etkileyen temel faktörler beş ana başlıkta aşağıda belirtilmektedir.
Veri: Veri madenciliği uygulamalarında mümkün olduğunca verinin büyük olması istenmektedir. Veriler arasındaki ilişki bağı karmaşıklık gösterdikçe, veri madenciliğine daha fazla ihtiyaç duyulmaktadır [24].
Donanım: Günümüz teknolojisinde bilgisayar belleğinin büyümesi ve işlemci hızındaki artışlar sayesinde işlenmesi mümkün olmayan verilerle çalışma yapılabilir boyut kazanmaktadır [25].
17
Bilgisayar ağları: Veri madenciliği yöntemleri uygulama alanı olan bilgisayar ağları ile doğru orantılı olarak gelişim göstermektedir. Bu doğrultuda dağınık ve büyük veri yığınlarını algoritmalar ile analiz etmek kolaylık sağlamaktadır [25].
Bilimsel hesaplamalar: Karmaşık verileri analiz etme sürecinde mühendislik alanında simülasyon büyük rol almaktadır. Bilim insanları tarafından oldukça önemli olan teorik bilgi ve deney faktörlerini, simülasyon ile üçüncü bir bilim yolu haline getiren veri madenciliği bu bağlamda önem taşımaktadır [25].
Ticari eğilimler: Günümüz teknolojisi ile birlikte hız kazanan rekabette, şirketlerin piyasadaki varlıklarını koruyarak minimum insan gücü ve maliyet ile maksimum verim oluşturma çabaları, veri madenciliği ve benzeri yöntemlere eğilmelerini zorunlu kılmıştır [25].
Veri madenciliğini etkileyen faktörlerde yaşanan aksaklık tüm analizin güvenilirliğini olumsuz yönde etkilemektedir. Bu doğrultuda yapılması gereken, veri setine uygun algoritmanın seçilmesinin ardından, istenilen bilgiye ulaşılacak yol haritasının belirlenmesidir.
2.2.2. Veri Madenciliği Sürecinde Karşılaşılan Sorunlar
Veri madenciliği yöntemlerinde işlenmemiş verinin güncel olmaması ya da istenilen sonuca hitap etmemesi analiz sürecinde büyük problemlerin açığa çıkmasına neden olmaktadır. Bu doğrultuda belirtilen veri madenciliği aşamalarındaki problemlerin bazıları aşağıdaki gibidir:
Boş veri: Büyük verilerin işlenmesi aşamasında faydalı bilgiye ulaştırmayacak veri yığınları boş değer olarak nitelendirilmektedir [27].
Gürültü ve kayıp değerler: Gürültü olarak adlandırılan ve veri analizi aşamasında yaşanılan sistemden kaynaklı hatalar verinin yanlış toplanmasına neden olabilmektedir. Bunun sonucunda veri setinin istenilen sonuca ulaşmasında problemler yaşanmaktadır [28].
18
Ebat, güncellemeler ve konu dışı sahalar: Analizi yapılan veri setine zamanla yeni bilgiler eklendikçe ya da silindikçe veri tabanındaki sonuçlarda değişiklikler meydana gelmektedir. Bu değişiklikler, çalışmanın sonucundaki kuralların aynı kalıp kalmadığı ve sürekliliği konusunda problemler ortaya çıkarmaktadır. Bu sorunların açığa çıkmaması için kurulan model zamana ve değişen veri setine duyarlı olması gerekmektedir [28].
Eksik veri: Veri madenciliği analiz aşamasında istenilen değişkenlerin girilememesi durumunda uygulanan algoritmadan sonuç alınamamaktadır. Analiz aşamasında eksik veri varlığından dolayı problemler açığa çıkmaktadır. Bu gibi durumlarda alternatif olarak değişken değişikliği ya da eksik verinin değişkenden çıkarılması gibi süreç değişikliği yapılmaktadır [27].
Veri tabanı boyutu: Veri madenciliğinde kullanılan verilerin boyutları her geçen gün hızla artmaktadır. Verilerin işlendiği algoritmalar daha küçük veri yığınlarına hitap etmektedir. Veri boyutlarının büyüklüğü ile analiz aşamasındaki sonucun verimliliği ne kadar doğru orantılı olsa da algoritmaların kullanımında hataların oluşmaması için dikkatli olunması gerekmektedir [27].
2.2.3. Veri Madenciliği Uygulama Alanları
Veri madenciliğinin kullanım alanları sektör bazında değerlendirildiğinde, büyük verilerin saklı olduğu tüm alanlarda ihtiyaç duyulduğu sonucuna varılmaktadır. Bu sektörlerin yanı sıra, verinin olduğu her alanda veri madenciliği çalışmaları yapmak mümkündür.
Veri madenciliğinin farklı sektörler tarafından tercih edilmesinin en önemli nedeni, çok büyük miktardaki verilerin istenildiği gibi işlenebilmesine imkan sağlamasıdır. Bu ihtiyacın temel nedeni, sektörlerin günümüz teknolojisinde veritabanında saklı olan verileri ile rekabet gücünü arttırmak ve pazardaki yerini koruyarak güçlü tutmayı amaçlamalarıdır.
19 Pazarlama
• Müşterilerin taleplerinin belirlenmesi,
• Müşteri talepleri doğrultusunda yenilikler getirerek müşteri ağının genişletilmesi,
• Satış stratejisinin belirlenmesi,
• Mevcut pazarda süreç aşamalarının tahmini, • Müşteri ilişkilerinin yönetimi.
Bankacılık
• Müşterilerin kredi kartı limitlerinin harcama ve ödemelerine göre değerlendirilmesi,
• Müşteri kredi başvuru sonuçlarının müşteri bilgileri ile sonuçlandırılması, • Kredi ve hesap kartı dolandırıcılıklarının önüne geçilmesi.
Sigortacılık
• Müşteri profilini analiz ederek poliçe talep edecek müşterilerin belirlenmesi, • Risk taşıyan müşteri profilinin belirlenmesi,
• Dolandırıcılıkların tespit edilmesi.
Diğer çalışılabilecek veri madenciliği konuları; hisse senetlerinde zaman analizi yapılarak gelecek değerler ile ilgili tahminde bulunulması, emniyet birimlerinde suç işleyen insanların profilini analiz ederek suç engelleme politikalarının oluşturulması, karayollarında kaza yapma oranı yüksek olan yerlerin tespiti ile kaza oranlarının düşürülmesinin sağlanması gibi farklı sektör ve alanlarda etkinleştirilmektedir [24].
Çizelge 2.3. ‘te veri madenciliği yöntemlerinin farklı sektörlerde kullanım oranı verilmektedir.
20
Çizelge 2.3. Veri madenciliği uygulama alanları [23].
Kullanım Alanı Kullanım Oranı (%)
CRM/ Müşteri Analitiği 32,80 Bankacılık 24,40 Direk Pazarlama 16,10 Kredi Puanlama 15,60 Telekominikasyon 14,40 Dolandırıcılık Tespiti 13,90 Satış 11,70 Sağlık 11,70 Finans 11,10 Bilim 10,60 Reklamcılık 10,60 E- Ticaret 10,00 Sigortacılık 10,00 Web Madenciliği 8,30 Sosyal Ağlar 7,80 İlaç 7,80 Bioteknoloji 7,80
Veri madenciliği yöntemlerinin tabloya göre en çok tercih edildiği sektör, % 31,80 oranı ile CRM / Müşteri Analitiği alanı olduğu sonucuna varılmaktadır. Sağlık sektöründe veri madenciliği kullanım oranı %11,70 ile yedinci sırada yer almaktadır. Sağlık sektöründe veri madenciliğine duyulan ihtiyacın da çok fazla olduğu görülmektedir. Bunun en önemli nedenlerinden biri de verilerin karmaşık ve büyük boyutta olmasının yanı sıra yapılan analizin sonucunda, insan sağlığını etkileyebileceğinden dolayı hata payına yer verilmemesidir.
Sağlık sektöründe veri madenciliğinin kullanım alanları aşağıda verilmektedir.
• Hastanede hizmet alan hastanın yatış süresinin azaltılmasıyla, hastane maliyetlerinin düşürülmesi,
• Hasta akış planlarının yapılması, • İlaç birim maliyetlerinin hesaplanması,
21
• Kronik hastalıklarda veri madenciliğine dayalı olarak ilaç kullanım alışkanlıkları ve risk tespitinin yapılması,
• Tıbbi tedavi süreçlerinin optimizasyonu,
• İlaç kullanımında hata veya ilacın yan etkileri için erken uyarı sinyallerinin verilmesidir.
Sağlık sektöründe veri madenciliği kullanım alanlarında sağlık personellerinin performanslarının izlenmesi müşteri memnuniyeti ve verimlilik açısından değerlendirildiğinde büyük bir etken olarak görülmektedir. Sağlık sektöründe müşteri memnuniyetini karşılamada, yönetimin en altındaki personelden en sorumlu yöneticiye kadar süreç tüm ekibi kapsamaktadır. Bunun neticesinde personellerin değerlendirilmesi ve bu doğrultuda eğitilmesi, sektörde istenilen başarıya ulaşma ve müşteri potansiyelini arttırma konusunda oldukça öneme sahiptir.
Sağlık sektöründe veri madenciliği, kurumun maliyetlerinin düşürülmesi çalışmalarında da verimlilik sağlamaktadır. Hastanede hizmet alan hastanın yatış süresinin azaltılmasıyla hastane maliyetlerinin düşürülmesi, kurumun gider yönetimine fayda sağlayarak, sektördeki payını büyütmesine olanak tanımaktadır. Bu açıdan sağlık sektörünün birçok alanında iyileştirme çalışmalarına ihtiyaç duyularak, hizmet kalitesinin arttırılması gerekmektedir.
22 BÖLÜM 3
VERİ MADENCİLİĞİ AŞAMALARI
Sektörler, veri madenciliği yöntemlerini kendi iç yönetim yapılarına göre oluştururken öncelik olarak fayda sağlayacak alanı belirlemektedir. Her bir sektör için uygulama ve yönetimi birbirinden bağımsız olduğundan dolayı, kendi sürecini ilk aşamada belirleyerek veri madenciliği sürecini izlemesi gerekmektedir. Veri madenciliği sürecinden verim alınmasının en önemli ve ilk aşaması amacın ve faydalanılacak kaynağın net olarak belirtilmesidir.
Analizi yapılacak veri seti farklı kaynaklardan alınarak ilişkilendirilmektedir. İlişkilendirilen verilerin birleştirilmesi aşamasında kaynakların değişkenlerinin aynı amaca yönelik net veriler olduğuna dikkat edilmelidir.
Şekil 3.1.’de farklı kaynaklardan alınan verinin model oluşturma aşamasına kadar izlenilen yol gösterilmektedir.
23
Şekil 3.1. Farklı kaynaklardan gelen verilerin ilişkilendirilmesi [24].
Farklı kurumlarda veriler, her bir kurumun kendi veritabanında birikmektedir. Kurumlar için önemli olan, elde ettikleri verilerin fayda sağlayacak ve verimliliği arttıracak şekilde projelere katkı sağlamasıdır. Veritabanında tutulan büyük verilerden faydalı ve anlamlı veri setleri çıkarmak veri madenciliği yöntemleri ile mümkün görülmektedir. Şekil 3.2. ‘de veri madenciliği aşamaları verilmektedir.
Modelin Değerlendirilmesi Toplama Diğer Veri Hareketleri Dış Kaynaklı Veriler Modelin Kurulması Birliktelik- Ardınlık Kümeleme Sınıflama- Regresyon Problemin Tanımlanması Verilerin Hazırlanması Dönüştürme Seçim Birleştirme Değer Biçme Fonksiyonel Departman Verileri ERP Sistem Verileri VERİ KAYNAKLARI Eski Saklama Ortamlarından Toplanan Veriler Veri Ambarları
24
Şekil 3.2. Veri madenciliği aşamaları [29].
Veri madenciliğinin ilk aşaması analizi yapılacak veri setinin seçilmesidir. Doğru verinin seçilmesi, doğru sonuca varılmasının ilk adımı olarak değerlendirilmektedir. Verinin seçilmesinin ardından veriler temizlenerek, varsa farklı kaynaktaki veri setleri ile birleştirilir. Son olarak, veriler arasındaki ilişkiler kategorize edilerek faydalı bilgilere ulaşmak amaçlanmaktadır.
3.1. PROBLEMİN VEYA ÇALIŞMANIN TANIMLANMASI
Problemin belirlenmesi, verimli ve doğru çözüme ulaşmanın ilk aşaması olarak belirtilmektedir. Bu aşamada konuya hakim, uzman kişiler tarafından gerekli bilgilerin eksiksiz olarak alınması gerekmektedir.
Analiz aşamasında doğru ve faydalı sonuca varmanın en önemli adımı problemin tanımlanmasıdır. Çalışma yapılacak alandaki verilerin doğru tespit edilmesi ve nasıl kullanılacağının belirlenmesi çalışmayı başarıya ulaştıracak ilk süreçtir.
25
Projede veya problemde verimli ve güvenilir sonuca ulaşılamamasının en büyük nedeni, problemin uzun ya da kısa zaman dilimindeki hedeflerinin net olarak belirtilmemesidir. Bu aşamada dikkat edilmesi gereken husus, veriden istenilen sonucun ilk aşamada belirtilmesi gerektiğidir.
3.2. VERİLERİN TOPLANMASI VE HAZIRLANMASI
Veri madenciliği yöntemlerine gerek duyulmasının en önemli nedenlerinden biri karmaşık ve büyük veri yığınları olduğundan dolayı, en çok vakit ayrılması gereken aşama veri hazırlama ve temizleme sürecidir. Verilerin doğru hazırlanmaması model kurma aşamasında problemler doğurarak ilk aşamaya geri dönmeyi gerektirmektedir.
Veri setinin modele hazır hale gelmesi aşamasında öncelik olarak, mevcut verinin anlaşılması ve amaca yönelik değişkenlerin temizlenmesi oldukça önemlidir. Veritabanındaki verinin hazırlama aşamasının birçok kez tekrar edilmesi verimi arttırmaya yönelik faydalı olacaktır.
Veri temizlenmesi, veritabanında eksik veya kayıt dışı bulunan değerlerin çıkarılması sonucunda hata oranın düzeltilme işlemidir. Bu aşama, verinin kalitesini arttırmak ve eksik verilerin belirli algoritmalar sonucu doldurulması yönünde önemli analizler içermektedir.
Birden fazla veri setinin birleştirilmesi ve zaman içerisinde verilerin düzeltilmesi, daha verimli sonuçlar doğuracağı gibi aynı zamanda da bazı problemlerin ortaya çıkmasına neden olacaktır. Bu problemler ile karşılaşmamak için “büyük veri” kullanılması gerekmektedir. Büyük veri, her bir verinin özelliklerini saklı tutmaktadır. Büyük veri her değişkenin anlamını, değişkenler arasındaki ilişkinin güçlü olduğunu ve kaynağı ile erişilecek veri gibi bilgileri içerir [25].
Verilerin boyutlarının olması gerektiğinden fazla olması ya da gereksiz verilerin veri setinde yer alması modelin yanlış ya da verimsiz sonuç vermesine neden olmaktadır. Bu nedenle, verilerin boyutlarının indirgenmesi ve değişkenlerin amaca yönelik sıralanması, modelin verimli sonuç vermesi açısından oldukça önemlidir.
26 3.3. MODELİN KURULMASI
Hazırlanan veriler ile problemin amacına yönelik birçok veri kurularak, en iyi sonucu verene kadar denenmesi gerekmektedir. Amaç, problemin çözümüne en uygun sonucu bulmak olduğundan dolayı, diğerine göre daha verimli sonucu bulmak hedef gösterilmektedir.
Model kurum aşamasındaki yöntemler üç ana başlıkta incelenmektedir. Aşağıdaki Çizelge 3.1.’de yöntemlere karşılık gelen metotlar ve algoritmalar belirtilmektedir.
Çizelge 3.1. Veri madenciliği yöntemlerini oluşturan algoritmalar [24].
Yöntem Metot Algoritma
Sınıflandırma/ Tahmin Edici
Yapay Sinir Ağları
Karar Ağaçları C5, ID3, C&R Tree Lineer & Lojistik Chaid, Quest Regresyon Bayes Sınıflandırıcılar
Regresyon Analizi
Kümeleme
Kohonen Ağları
K- Means Kümeleme
Two- Step Kümeleme
Birliktelik Kuralları
Appriori
GRI
Carma
Modelin kurulmasında güvenilir sonuca ulaşmak için dikkat edilmesi gereken en önemli husus, problemin çözümüne yönelik modelin kurulmasıdır. Doğru model seçimi yapılmadığı takdirde, amaca yönelik çalışma gerçekleşmesi mümkün olmayacaktır.
Farklı problem tipleri için çözüme yönelik birden fazla model olabilmektedir. Kurulan modelde birbiri ile ilişkili değişkenler olması gerekenden fazla olduğu durumlarda, en anlamlı değişkenler seçilmelidir.
27
3.4. MODELİN DEĞERLENDİRİLMESİ VE İZLENMESİ
Model kurma aşaması, kurulan birden fazla modeller karşılaştırılarak en anlamlı modelin seçildiği süreçtir. Seçilen modelin uygulamaya alınmasının ardından yaşanan problemler kontrol edilerek, varsa modeldeki eksik yönler tespit edilmeli ve giderilmelidir.
Modelin değerlendirilmesinin ardından uygulamaya alınmadan önce güvenilirliği test edilmelidir. Modelin doğruluk derecesinin değerlendirilmesi aşamasında belirli tekniklerden yararlanılmaktadır.
Kurulan modelin doğruluğunun test edilmesinin ardından, projeye uygun belirli periyotlarla izlenmesi gerekmektedir. Zaman içerisinde değişikliğe uğrayan sistemlerin değişkenlerinde ve veri boyutlarında farklılıklar gözlenebilir. Bu durumda uygulamaya alınan model, bir süre sonra verimli olamayacağı gibi farklı problemler de ortaya çıkarabilir. Modelin mevcut prosese zarar vermemesi ve daha verimli kullanılabilmesi için uygulandığı süre zarfında izlenmesi gerekmektedir.
28 BÖLÜM 4
VERİ MADENCİLİĞİ MODELLERİ
Veri madenciliği modelleri, tahmin edici ve tanımlayıcı olmak üzere iki ana başlık altında incelenmektedir. Veri madenciliği modeline ilişkin görsel aşağıdaki çizelge 4.1.’de belirtilmiştir.
Çizelge 4.1. Veri madenciliği modelleri.
Sınıflandırma
Satış tahminleri
Sipariş tahminleri
Üretim hata maliyetlerinin tahmini ve nedenleri
Dolandırıcılık tespiti
Kümeleme Analizi
Müşteri profili çıkarma
Ürün satış profili çıkarma
Hata yer ve zamanlarının kümelemesi
Birliktelik Analizi
Pazar sepeti analizi
Müşteri satış eğilimi
Zamana bağlı ardışık satış
Tanımlayıcı modeller, veride gizli kalmış örüntüleri açığa çıkararak, analizin sonucunu etki edecek veri setindeki değişkenler arasında ilişki olup olmadığını tanımlamayı amaçlamaktadır. Tanımlayıcı modellerden kümeleme (Clustering) ve birliktelik kuralları (Association Rules) en çok tercih edilen veri madenciliği modelleri arasında yer almaktadır.
Tahmin edici modeler, sonucu bilinen veri setindeki örnekle, sonucu bilinmeyen veri setinin analizinde tahminleme oluşturmaktadır. Tahmin edici modeller sınıflandırmasında yer alan sınıflandırma (Classification) ve regresyon (Regression) analizi en sık kullanılan modellerdir.
29 4.1. TANIMLAYICI MODELLER
Tanımlayıcı modeller, analiz sonucuna etki edecek veri setindeki değişkenler arasında ilişki olup olmadığını tanımlamayı amaçlamaktadır.
4.1.1. Kümeleyici Modeller
Kümeleme analizinde amaç, büyük verilerde birbirleri ile ilişkili olan verileri aynı kümeye dahil etmektir. Kümeleme analizi ile tahmin edici modeller arasında yer alan sınıflandırma yöntemi arasındaki fark, kümeleme analizinde verilerin hangi kriterlere göre gruplanacağının öncesinde tahmin edilememesidir.
Kümeleme analizi algoritmalarının veri madenciliğinde kullanılabilmesi için girdi değişkenlerinin minimum düzeyde olması gerekmektedir. Kümeleme analizinde güvenilir sonuca ulaşmak için kayıp veri oranlarından etkilenmemesi, verilerin düzeninin değişmesi durumuna duyarlı olmaması ve büyük boyutlu verilerde rahat çalışabilir olması gerekmektedir [30].
Şekil 4.1. ‘de kümeleme yöntemleri ve grupların alt bağlantıları gösterilmektedir. Hiyerarşik olan ve hiyerarşik olmayan olarak iki ana gruba ayrılan kümeleme yöntemlerinde analizin aşamalı olup olmadığı belirlenmektedir.
30
Şekil 4.1. Kümeleme yöntemleri [24].
Hiyerarşik olan ve hiyerarşik olmayan olarak ikiye ayrılan kümeleme algoritmalarının oldukça yaygın kullanılanları aşağıda açıklanmıştır.
K- Ortalama Yöntemi (K-Means): Veri madenciliği kümeleme algoritmaları arasında en çok kullanılan yöntemdir. Belirtilen “k” simgesi algoritmadaki küme sayısını belirtmektedir. Kümeleme sayısının belirlenmesinin ardından küme ortalaması belirlenerek, kümelerin birbirlerine uzaklıkları esas alınıp en uygun kümeye gözlemin ataması yapılmaktadır. Kümeye her yeni gözlemin atamasının yapılmasıyla tekrar ortalama alınarak süreç tekrarlanmaktadır. K- Ortalama yönteminde sayısal verilerde başarılı sonuçlar elde edilmesi avantaj olarak gösterilirken, kategorik verilerde sorunlar yaratması dezavantaj olarak belirtilmektedir [30].
PAM Algoritması: Açılımı “Partitioning Around Medoids” olan bu algoritma K- Means algoritması gibi rastgele seçtiği k sayıda elemanı alarak küme merkezini oluşturmaktadır. Kümeye her yeni gözlem eklendiğinde kümenin verimine katlı sağlayacak gözlemi belirleyerek, kümenin merkezini tekrar seçmektedir.
31
K- Medoids: Rastgele temsilci nesnelerin seçilmesinin ardından kalan nesneler en yakındaki temsilci nesnenin kümesine atanmaktadır. Temsilci nesneye atanmayan bir nesne seçilir ve temsilci nesne ile değişimi için toplam maliyet hesaplanır. Toplam maliyetin sıfırdan küçük olması durumunda rastgele seçilen nesne ile temsilci nesne değiştirilerek küme yenilenir. Bu işlem hiçbir değişim olmayana kadar temsilci nesneye, kalan nesnelerin ataması devam ederek süreç yenilenmektedir.
Clara Algoritması: Büyük veri setlerinde K- Medoids algoritmasının olumlu sonuçlar vermemesi ile geliştirilen bir algoritmadır. Büyük bir veri setinden alınan örnek bir veri setine PAM algoritmasının uygulanması ile geliştirilmiş bir yöntemdir.
Two Step: Büyük veri tabanlarının analizi aşamasında kullanılması amaçlı tasarlanmıştır. Bu yöntem, küme sayısını kendisi optimum sayıya göre belirlemektedir. Kullanıcının küme sayısı aralıklarını girmesinin ardından, kayıtlar ön kümelere ayrılarak hiyerarşik kümeleme yöntemi uygulanır. Verilerin birbirine uzaklığı dikkate alnırak kümeler oluşturulur [24].
Kohonen Ağları: Bu yöntem, bağımsız değişken kümesindeki örüntülerin çıkarılması amacıyla kullanılmaktadır. Kümeleme amacıyla kullanılmasının yanında, verinin görselleştirilmesi amacıyla da tercih edilmektedir. Kohonen ağları, az sayıda birimin çok sayıda gözlemi özetlediğinde son bulmaktadır [24].
Kümeleme analizinin temelinde uzaklıkların v benzerliklerin ölçülmesi vardır. Bu uzaklık ölçüleri aşağıda verilmiştir;
Öklid uzaklığı aşağıdaki gibi formülüze edilir.
32
Manhattan uzaklığı aşağıdaki gibi formülüze edilir.
Kümeleme analizinde aynı özelliğe sahip veriler aynı grupta, birbirinden farklı özelliği sahip veriler farklı grupta bulunmaktadır. Analiz aşamasında kurulan matrisler de yöntemin bu özelliğini dikkate alarak oluşturulmaktadır.
4.1.2. Birliktelik Kuralları
Değişkenler arasındaki ilişkinin büyüklüğünün belirlenmesi tekniğidir. Genellikle pazarlama, satış alanlarında tercih edilmekte olup, müşteri ürün talep konusunda öngörüde bulunmaya yardımcı olmaktadır. Örneğin; marketten A ürününü alan bir müşteri B ürününü de yüksek oranla tercih ediyorsa, başka bir müşteri B ürününü alıp A ürünün almazsa, A ürününü almayan müşterinin o ürünü alması yüksek oran olarak tespit edilmektedir.
A ürününü alan bir müşterinin B ürününü de satın alması durumundaki birliktelik kuralları kriterleri aşağıda verilmiştir.
Pazar sepeti analizinde amaçlanan, alıcının talep profilini belirlerken, satıcının da ürün alım sürecinde doğru analizler yapmasına kolaylık sağlamaktır. Bu nedenle büyük ve orta ölçekli marketlerde sıkça kullanılan bir yöntem haline gelmiştir.
33
Birliktelik kurallarında, Apriori ve GRI olmak üzere iki farklı algoritma kullanılmaktadır. Bu algoritmaların amacı, birlikte oluşan iyi ya da daha fazla kaydı bulmaya çalışmaktır. Apriori ve GRI algoritmaları öncelikle basit kayıtlar oluşturarak, daha sonraki aşamalarda karmaşık kurallar kaydetmektedir. Diğer kurallara bağımlı olmayan kurallar üreterek, pozitif ilişkileri analiz ettiği gibi negatif birliktelikleri de ortaya çıkarmaktadır [24].
4.2. TAHMİN EDİCİ MODELLER
Tahmin edici modellerde, öncesinde sonucu belli olan veri seti üzerinden tahmin yapılmaktadır. Mevcut veriler ile model kurulmasının ardından, çıkan sonuçlardan öncesinde çalışma yapılmamış büyük veri kümesine bu modellerin uygulanması ve tahmin edilebilecek analizin yapılması olarak adlandırılmaktadır.
4.2.1. Sınıflayıcı Modeller
Sınıflayıcı modeller, dağınık halde olan veri setini birleştirmesini, veri setindeki değişkenleri baz alarak belirlemektedir. Sınıflama algoritmasında belirlenen değişkenlerin, sınıflandırmadaki diğer değişkenlerle ilişkili olması gerekmektedir.
Sınıflayıcı modeller, tahmin edici modeller arasında yer aldığından dolayı öngörüde bulunma özelliğine sahiptir. Farklı sektörlerde kullanım alanının varlığı, veri madenciliği yöntemleri arasında en çok tercih edilen algoritmalardan olmasına yol açmıştır. Hava durumu tahminleri, sepette bulunan kutuların renk tahmini de sınıflandırma algoritması analizi sonucunda belirlenmektedir.
Sınıflama algoritmalarının başlıca yöntemleri aşağıdaki gibidir:
• Karar Ağaçları • Yapay Sinir Ağları
• Bayes Sınıflandırma Algoritması • Çoklu Doğrusal Regresyon
34 • Lojistik Regresyon
• Genetik Algoritma
• Random Forest Algoritması • IB1 Algoritması
4.2.1.1. Karar Ağaçları
Hem tanımlayıcı hem de tahmin edici algoritma yapısına sahip olduğundan dolayı en çok kullanılan algoritmalar arasında yer almaktadır. Diğer algoritmalar ile karşılaştırıldığında analiz aşamasının kolay olması ve maliyeti düşük olması tercih edilmesindeki diğer en önemli etkendir. Karar ağacı modelinin yorumlanması kolay olup, güvenilirlik seviyesi oldukça yüksektir [24].
Karar ağacı algoritması kök düğüm ile başlayarak niteliklerine göre dallara ayrılmaktadır. Bu nitelikler analiz sonucunda oluşmaktadır fakat mevcut değişkenlerin hepsinin dallanması beklenmez. Dallanmaların sonucunda karar ağacında izlenecek yol belirlenerek ilişki kurulamayan değişkenlerden tekrar dallanma oluşturulmaktadır.
Karar ağacı algoritması sonucunda sunulan görsellik nedeni ile de kullanımı cazip gelmektedir. Bu açıdan sağlık sektöründe, hasta tanı tedavisinde oldukça yaygın kullanılmaktadır. Kalp krizi şikayeti ile başvuran hastaya teşhis konulması aşamasında bir çok test yapılmaktadır. Yapılan testlerin sonucunda kalp krizi geçirme riski olan hasta profili çıkarılmaktadır. Bu çıkarılan istatistiki veri karar ağacı algoritması ile mümkün olmaktadır.
Karar ağacı algoritmalarının oldukça yaygın kullanılanları aşağıda açıklanmıştır.
ID3 Algoritması (Induction of Decision Trees): Sydney Üniversitesi’nde araştırmacı olan J. Ross Quinlan tarafından geliştirilmiştir. Veri setinde verilen örnekler arasında farklı değişkeni makine öğrenmesi ve bilişim teknolojisi aracılığıyla bularak, işlem esnasında entropiden yararlanan bir algoritmadır. Entropi, verileri birbirinden ayıran farklılıklarıdır. Entropi, sistemdeki belirsizliği tespit etmekte ölçüttür ve bir alanın entropi ölçüsü yüksek olması, mevcut olanın belirsizliğini arttırmaktadır. Bu nedenle,
![Şekil 2.3. 2017-2018 yılları sağlık hizmetlerinde hasta memnuniyet oranının uluslararası karşılaştırılması [13]](https://thumb-eu.123doks.com/thumbv2/9libnet/5406452.102214/23.892.175.781.598.920/şekil-yılları-sağlık-hizmetlerinde-memnuniyet-oranının-uluslararası-karşılaştırılması.webp)
![Şekil 2.7. 2002- 2016 yılları arasında yatan hasta, yatak devir hızı, ortalama kalış gün süresi [16]](https://thumb-eu.123doks.com/thumbv2/9libnet/5406452.102214/28.892.171.775.550.868/şekil-yılları-arasında-yatan-hızı-ortalama-kalış-süresi.webp)

![Çizelge 2.2. Veri madenciliği hakkında doğru ve yanlış bilinenler [23].](https://thumb-eu.123doks.com/thumbv2/9libnet/5406452.102214/32.892.174.798.190.430/çizelge-veri-madenciliği-hakkında-doğru-yanlış-bilinenler.webp)