T.C.
SELÇUK ÜNİVERSİTESİ FEN BİLİMLERİ ENSTİTÜSÜ
SINIFLANDIRMA PROBLEMLERİNDE META-SEZGİSEL OPTİMİZASYON YÖNTEMLERİNİN ÖZELLİK SEÇİMİ VE AYRIKLAŞTIRMA AMACIYLA KULLANIMI
İsmail KOÇ
YÜKSEK LİSANS TEZİ
Bilgisayar Mühendisliği Anabilim Dalı
Ocak - 2016 KONYA Her Hakkı Saklıdır
iv ÖZET
YÜKSEK LİSANS TEZİ
SINIFLANDIRMA PROBLEMLERİNDE META-SEZGİSEL OPTİMİZASYON YÖNTEMLERİNİN ÖZELLİK SEÇİMİ VE
AYRIKLAŞTIRMA AMACIYLA KULLANIMI
İsmail KOÇ
Selçuk Üniversitesi Fen Bilimleri Enstitüsü Bilgisayar Mühendisliği Anabilim Dalı
Danışman: Yrd. Doç. Dr. İsmail BABAOĞLU
2016, 181 Sayfa Jüri
Yrd. Doç. Dr. İsmail BABAOĞLU Doç. Dr. Erkan ÜLKER Yrd. Doç. Dr. Onur İNAN
Sınıf etiketleri yardımıyla belli bir veri kümesi üzerinden oluşturulan modeller kullanılarak yeni örneklerin hangi sınıfa ait olacağının tahmin edilmesi genel olarak sınıflandırma problemi olarak adlandırılmaktadır. Birçok alanda karşılaşılan bu problemlerin çözümü için farklı disiplinlerde yeni yöntemler üzerine çalışmalar yapılmaktadır. Dolayısıyla her geçen gün yeni yaklaşımlar sunulmakta ve çözüm yöntemleri geliştirilmektedir. Bununla birlikte sınıflandırma başarısının artırılması amacıyla da literatürde farklı teknikler yer almaktadır. Bu tezde veri madenciliğinde kullanılan ve önemli yöntemlerden biri olan özellik seçimi kullanılmıştır. Alt küme seçimi olarak bilinen özellik seçimi makine öğrenmesinde yaygın olarak kullanılan bir yöntemdir. Bu yöntem, veriyi işleme ve analiz etmek için yönetilebilir boyuttaki veriyi azaltan teknikleri ve araçları tanımlayan bir terimdir. Özellik seçimi işleminde, veri kümesinden elde edilen özellik alt kümesi öğrenme algoritması uygulaması için seçilir. En iyi alt küme, çözüm uzayı için en yüksek doğruluk oranına sahip olan en küçük boyutlu veri kümesinden oluşur. Veri kümesindeki geriye kalan önemsiz nitelikler ise yok sayılır. Bu işlem, önemli bir veri ön işleme aşamasıdır.
Problemlerde karşılaşılan veriler sürekli veya kesikli (ayrık) veri şeklinde olabilmektedir. Özellikle tahmin modelleri oluşturma çalışmalarında kesikli veri tercih edilmektedir. Bu tercihin sebebi ise ayrık verilerin bilgi düzeyli gösterilebilir olması, bazı işlemler sonrası sadeleştirilmiş olması, anlaşılır ve açıklanabilir olmasıdır. Sürekli verinin kesikli veriye dönüştürülmesi işlemleri genel olarak “veri ayrıklaştırma” olarak tanımlanmaktadır. Ayrıklaştırmanın başarısı hangi algoritmanın kullanıldığına, verinin dağılımına ve sonuç çıkarma modeli gibi parametrelere bağlıdır.
Bu tezde optimizasyon algoritmalarının özellik seçimi ve ayrıklaştırma amacıyla kullanılması araştırılmıştır. Dört farklı global erişilebilir veri kümesi üzerinde özellik seçimi, eşit genişlik ve eşit frekansa göre ayrıklaştırma amacıyla Yapay Arı Kolonisi, Guguk Kuşu, Yarasa ve Yerçekimsel Arama algoritmaları kullanılmış olup analiz sonuçları karşılaştırmalı olarak sunulmuştur. Süre analizleri, özellik seçimi sonrası elde edilen özellikler ve ayrıklaştırma sonrası belirlenen ayrıklaştırma sınırlarına ait analizler ise tez kapsamı dışında tutulmuştur. Özellik seçimi işlemlerinde optimizasyon algoritmalarının ikili versiyonu kullanılmış olup ayrıklaştırma işlemlerinde ise algoritmaların sürekli versiyonları kullanılmıştır.
Anahtar Kelimeler: Ayrıklaştırma, Destek Vektör Makinaları , Eşit Genişlik, Eşit Frekans, Guguk Kuşu Arama Algoritması, İkili Optimizasyon Algoritmaları, Optimizasyon Algoritmaları, Özellik Seçimi, Yapay Arı Kolonisi Algoritması, Yarasa Algoritması, Yerçekimi Arama Algoritması
v ABSTRACT
MS THESIS
UTILIZATION OF METAHEURISTIC OPTIMIZATION METHODS FOR FEATURE SELECTION AND DISCRETIZATION ON
CLASSIFICATION PROBLEMS
Ismail KOC
THE GRADUATE SCHOOL OF NATURAL AND APPLIED SCIENCE OF SELÇUK UNIVERSITY
THE DEGREE OF MASTER OF SCIENCE IN COMPUTER ENGINEERING
Advisor: Asst. Prof. Dr. Ismail BABAOGLU
2016, 181 Pages
Jury
Asst. Prof. Dr. Ismail BABAOGLU Assoc. Prof. Dr. Erkan ULKER
Asst. Prof. Dr. Onur INAN
Prediction of the samples classes using models which are formed through a given data set by means of the class labels is generally named as classification problem. In order to solve these kinds of problems encountered in several areas, many researches on novel methods are studied in different disciplines. Therefore, novel approaches have been presented, and solution methods have been developed day by day. Besides, there are different techniques which are used for increasing the classification accuracy in literature. In the thesis, feature selection which is one of the important techniques used in data mining has been utilized. Feature selection known as subset selection is a method which is commonly used in machine learning. This method is a term which defines resources and techniques of decreasing data with manageable dimension for operation and analysis of data. The subset of the features which are obtained from the dataset is selected for the application of the learning algorithm in the feature selection process. The best subset consists of data set with the least dimensions that has the maximum accuracy. The remaining redundant attributes are disregarded. This process is one of the important data preprocessing stages.
The data encountered in problems can be in discrete or continuous data form. The discrete data is preferred in the studies in forming prediction models, especially. The reason of this preference can be said that discrete values can be shown as in information level, they are summarized in the end of some processes and they are understandable and explicable. The processes transforming continuous data into discrete data are generally described as data discretization. Discretization is a data preprocessing approach used frequently in methods of data mining and machine learning. The success of discretization process is related to the parameters such as the result attainment model, data distribution and which algorithm is utilized.
In the thesis, the usage of optimization algorithms in the purpose of feature selection and discretization has been studied. Artificial Bee Colony, Bat, Gravitational Search and Cuckoo Search Algorithms have been used with the intention of feature selection, equal width discretization, equal frequency discretization using four different global available data set and their analysis results have been presented comparatively. However, time analysis and the analysis of both the features obtained by feature
vi
selection process and the boundaries obtained by the discretization process are excluded from this thesis. While the binary versions of these algorithms have been used in the processes of feature selection, the continuous versions of them have been utilized in the discretization processes.
Keywords: Artificial Bee Colony Algorithm, Bat Algorithm, Binary Optimization Algorithms, Cuckoo Search Algorithm, Discretization, Equal Frequency, Equal Width, Feature Selection, Gravitational Search Algorithm, Optimization Algorithms, Support Vector Machines
vii ÖNSÖZ
Bu çalışmamda beni destekleyip, yönlendiren danışman hocam Yrd. Doç. Dr. İsmail Babaoğlu’na ve Selçuk Üniversitesi Mühendislik Fakültesi Bilgisayar Mühendisliği Bölümü Öğretim Eleman’larına teşekkürlerimi sunarım.
Çalışmalarım sırasında benden maddi ve manevi desteklerini asla esirgemeyen aileme en içten teşekkürlerimi sunarım.
İsmail KOÇ KONYA-2016
viii İÇİNDEKİLER ÖZET ... iv ABSTRACT ... v ÖNSÖZ ... vii İÇİNDEKİLER ... viii SİMGELER VE KISALTMALAR ... x 1. GİRİŞ ... 1
1.1. Tez Çalışmasının Amacı ... 2
1.2. Tez Çalışmasının Önemi ... 4
2. KAYNAK ARAŞTIRMASI ... 5
2.1. Optimizasyon Algoritmaları Yardımıyla Sınıflandırma ve Destek Vektör Makinaları ile İle İlgili Literatür Çalışmaları ... 5
2.2. Özellik Seçimi ile İle İlgili Literatür Çalışmaları ... 11
2.3. Ayrıklaştırma ile İle İlgili Literatür Çalışmaları ... 18
3. OPTİMİZASYON ALGORİTMALARI ... 21
3.1. Yapay Arı Koloni Algoritması ... 21
3.1.1. Arıların yem bulma davranışları ... 21
3.1.3. Yiyecek kaynakları ... 22
3.1.3. Görevi belirli işçi arılar ... 22
3.1.4. Görevi belirli olmayan işçi arılar ... 22
3.1.5. Yapay arı kolonisi algoritması ve temel adımları ... 24
3.1.6. İkili (Binary) yapay arı koloni algoritması ... 25
3.2. Yerçekimsel Arama Algoritması ... 28
3.2.1. İkili (binary) yerçekimsel arama algoritması ... 31
3.3. Guguk Kuşu Arama Algoritması ... 32
3.3.1. Başlangıç popülasyonu oluşum evresi ... 35
3.3.2. Guguk kuşunun yumurtlama evresi ... 36
3.3.4. En kötü habitattaki guguk kuşlarını yok etme evresi ... 38
3.3.5. Yakınsama evresi ... 39
3.3.6. İkili guguk kuşu arama algoritması ... 39
3.4. Yarasa Algoritması ... 40
3.4.1. İkili Yarasa Algoritması ... 43
4. DESTEK VEKTÖR MAKİNALARI ... 44
4.1. Çekirdek (Kernel) Fonksiyonları ... 45
ix
5.1. Özellik Seçimi ... 47
5.1.1. Özellik Seçimi Tanımları ... 47
5.2. Özellik Seçiminin Avantajları ve Dezavantajları ... 48
5.3.1. Arama organizasyonu ... 49
5.3.2 Sonraki jenerasyon ... 50
5.4. Özellik Seçimi İçin Önerilen Sistem ... 50
6. VERİ AYRIKLAŞTIRMA TEKNİKLERİ VE ÖNERİLEN YÖNTEM ... 53
6.1. Veri Ayrıklaştırma İşlemi ... 53
6.2. Karakteristik Bir Ayrıklaştırma İşlemi ... 53
6.2.1. Kesim noktası seçme ... 54
6.2.3. Bölme (split) ve birleştirme (merge) ... 55
6.2.4. Durdurma kriteri ... 55
6.3. Veri Ayrıklaştırma Yöntemlerinin Sınıflandırılması ... 55
6.4. Veri Ayrıklaştırmada Kullanılan Bazı Yöntemler ... 57
6.4.1. Eşit genişlikli ayrıklaştırma ... 57
6.4.2. Eşit frekanslı ayrıklaştırma ... 58
6.5. Ayrıklaştırma İçin Önerilen Sistem ... 59
7. TEST VE DEĞERLENDİRME ... 63
7.1. Deneysel Çalışmalar ... 63
7.2. Tanı Testlerinde Kullanılan Ölçütler ... 64
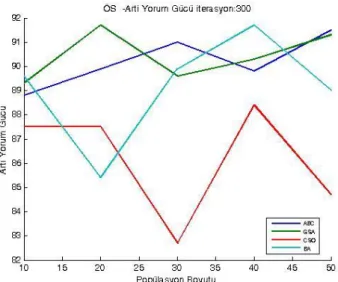
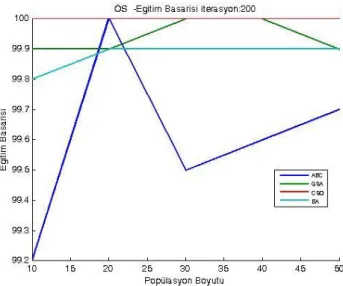
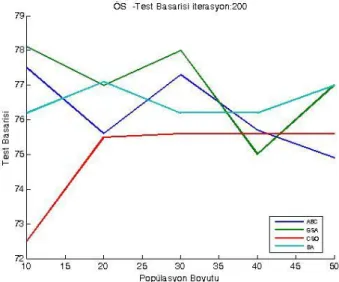
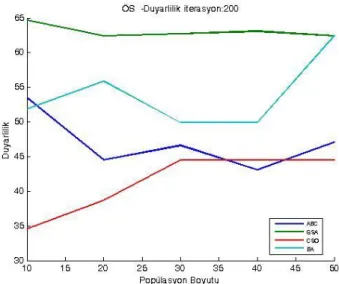
7.3. Özellik Seçimi İçin Test Sonuçları ... 65
7.3.1. WPBC veri kümesi kullanılarak ÖS’ye ait deneysel sonuçlar ... 65
7.3.2. BCW veri kümesi kullanılarak ÖS’ye ait deneysel sonuçlar ... 68
7.3.3. QSAR veri kümesi kullanılarak ÖS’ye ait deneysel sonuçlar ... 69
7.3.4. DRD veri kümesi kullanılarak ÖS’ye ait deneysel sonuçlar ... 71
7.4. Eşit Genişlikli Ayrıklaştırma Yöntemi İçin Test Sonuçları ... 74
7.4.1. WPBC verisi kullanılarak EWD yöntemine ait deneysel sonuçlar... 74
7.4.2. BCW veri kümesi kullanılarak EWD yöntemine ait deneysel sonuçlar ... 75
7.4.3. QSAR veri kümesi kullanılarak EWD yöntemine ait deneysel sonuçlar ... 78
7.4.4. DRD veri kümesi kullanılarak EWD yöntemine ait deneysel sonuçlar... 79
7.5. Eşit Frekanslı Ayrıklaştırma Yöntemi İçin Test Sonuçları ... 82
7.5.1. WPBC verisi kullanılarak EFD yöntemine ait deneysel sonuçlar ... 82
7.5.2. BCW verisi kullanılarak EFD yöntemine ait deneysel sonuçlar ... 84
7.5.3. QSAR veri kümesi kullanılarak EFD yöntemine ait deneysel sonuçlar ... 86
7.5.4. DRD veri kümesi kullanılarak EFD yöntemine ait deneysel sonuçlar ... 88
7.6. Uygulama Sonuçlarının Değerlendirilmesi ... 89
8. SONUÇLAR VE ÖNERiLER ... 97 8.1. Sonuçlar ... 97 8.2. Öneriler ... 97 KAYNAKLAR ... 99 EKLER ... 108 ÖZGEÇMİŞ ... 181
x SİMGELER VE KISALTMALAR Simgeler v : hız faktörü x : konum değeri f : frekans 𝛾 : Çekirdek Boyutu Kısaltmalar
ABC : Yapay Arı Kolonisi Algoritması
GSA : Yerçekimsel Arama Algoritması
CSO : Guguk Kuşu Arama Algoritması
BA : Yarasa Algoritması
DVM : Destek Vektör Makinaları
ÖS : Özellik Seçimi
EWD : Eşit Genişlikli Ayrıklaştırma
EFD : Eşit Frekanslı Ayrıklaştırma
BCW : Breast Cancer Wisconsin
DRD : Diabetic Retinopathy Debrecen
QSAR : QSAR biodegradation
WPBC : Breast Cancer Wisconsin (Prognostic)
KKA : Karınca Koloni Algoritması
YBS : Yapay Bağışıklık Sistemi
ÖAS : Özellik Alt Küme Seçimi
DVR : Destek Vektör Regresyonu
KNN : K-En Yakın Komşuluk
IİÇAO : Isıl İşlem Tabanlı Çok Amaçlı Optimizasyonu
PSO : Parçacık Sürü Optimizasyonu
GBYSA : Geri Beslemeli Yapay Sinir Ağları
GA : Genetik Algoritma
YSA : Yapay Sinir Ağları
1. GİRİŞ
Özellik seçimi (ÖS), sınıflandırma problemlerinde ve birçok öğrenme algoritmalarında önemli bir yer teşkil etmektedir. ÖS, sonuç değeriyle ilgili olan, en faydalı ve en önemli özelliklerin seçilerek veri kümesine ait özellik sayısının azaltılması için kullanılan bir yöntemdir. Amaç; hesaplama yükünü azaltıp başarı oranını yükseltmektir. Literatürde ÖS yöntemleri ile ilgili çok fazla araştırma bulunmaktadır ve birçok alanda çeşitli uygulamaları ile karşılaşılmaktadır. (Zongker ve Jain 1996, Onnia ve ark 2001);
1) Özellik sayısının çok olduğu durumda veri kümesindeki gizli ilişkileri elde etmek amacıyla,
2) Çok fazla sayıda algılayıcıdan veri elde edilen uygulamalar,
3) Sınıflandırma amacıyla bir araya getirilen çoklu modellere ait parametre sayısının çok olduğu durumlar,
4) Giriş uzay boyutunun azaltılması gereken uygulamalardır.
ÖS yöntemleri başlıca iki ana sınıfta incelenebilir. Bunlardan ilki istatistiğe dayalı yöntemlerdir. Diğeri ise sınıflandırmaya dayalı yöntemler olarak bilinmektedir (Onnia ve ark 2001). İstatistiğe dayalı yöntemler sınıflandırma problemine bağlı kalmadan istatistiksel yöntemleri kullanarak en uygun özellik alt kümesini tespit etmeyi amaçlamaktadır. Sınıflandırmaya dayalı yöntemler ise sınıflandırma probleminde kullanılmayacak olan özellik alt kümelerinin tespit edilip veri kümesinden atılmasına veya sınıflandırma için en önemli özelliklerin bulunmasına dayalı yöntemler olarak bilinir.
ÖS makine öğrenmesinde yaygın olarak kullanılan bir yöntem olup literatürde alt küme seçimi olarak bilinmektedir. ÖS işleminde, veri kümesinden elde edilen özellik alt kümesi, öğrenme algoritması için seçilir. Çözüm uzayı için en yüksek doğruluk oranına sahip olan en küçük boyutlu veri kümesinden oluşan küme en iyi alt küme olarak kabul edilir. Veri kümesindeki geriye kalan önemsiz özellikler yok sayılır. Bu aşama, önemli bir veri ön işleme aşamasıdır. ÖS’nin temel hedefi, orijinal özelliklerin hepsini kullanmadan en yüksek oranda veri bütünlüğünü sağlamaktır. Bununla birlikte minimum özellik alt kümesini bulmaktır. Birçok gerçek dünya probleminde, gereksiz, yanıltıcı veya gürültülü verinin çokluğundan dolayı ÖS bir
zorunluluk olarak kabul edilmektedir. ÖS sonuçlarında en ideal çözümü bulmak için, tüm özellik alt kümelerinin test edilmesi gerekmektedir.
Veri ön işleme adımlarından birisi de veri ayrıklaştırma yöntemidir. Kısaca sürekli verinin kesikli veriye dönüştürülmesi olarak ifade edilmektedir. Buna ek olarak veri ayrıklaştırma için aynı anlamı taşıyan literatürde farklı tanımlar yer almaktadır; Jin ve ark (2007), veri ayrıklaştırma işlemini en az veri kaybı ile sürekli verinin sonlu komşu aralıklar şekline dönüştürülme evresi olarak tanımlarken, Das ve Vyas (2010) aynı veya yakın özelliklere sahip sürekli verinin gruplara veya aralıklara dönüştürülmesi süreci olarak ifade etmektedir. Veri ayrıklaştırma işlemine verilebilecek en basit örneklerden birisi ise, yaş niteliğine ait değerlerin veri ayrıklaştırma sonrası elde edilecek değer aralıklarına göre dağıtılıp bu aralıkların “genç”, “orta yaş” ve “yaşlı” gibi farklı üç grup olarak ifade edilmesidir.
Veri ayrıklaştırma aşaması sonrasında sürekli veri azaltılıp veri kümesi en iyi temsil edilecek şekilde özetlenirken, veri madenciliği sonrası elde edilen bilgilerin kullanımı ve sunumu kolaylaşmış, bununla birlikte bu bilgilerin daha anlamlı hale gelmesi de sağlanmış olur (Chakrabarti ve ark 2008). Veri ayrıklaştırma yöntemi için birçok yöntem kullanılmakla beraber mevcut yöntemlerin yanı sıra yöntemler üzerine yeni özellikler de eklenerek farklı ayrıklaştırma yöntemleri geliştirilmiştir.
Bu çalışmanın ilk bölümünde tezin amacı ve önemi belirtilmiştir. Sonraki bölümlerde ise sırasıyla kaynak araştırması, optimizasyon algoritmaları, DVM, ÖS ve uygulanan yöntem, ayrıklaştırma ve önerilen yöntem, test ve değerlendirme ve sonuçlar ve öneriler anlatılmıştır. Geliştirilen ÖS ve eşit frekans ve eşit genişlik tabanlı ayrıklaştırma yöntemleri MATLAB2014 ortamında kodlanmıştır. Uygulamalar algoritmalara ait farklı parametre değerlerinde test edilecek şekilde tasarlanmıştır. Çalışmanın son bölümünde ise geliştirilen yöntemlerin uygulama sonuçları analiz edilmiştir.
1.1. Tez Çalışmasının Amacı
ÖS makine öğrenmesi ve istatistikte değişken seçimi, nitelik seçimi veya değişken alt küme seçimi olarak bilinmektedir. ÖS; veri modeli oluşturmada kullanılmak üzere veri kümesine ait özelliklerin bir alt kümesini seçme aşaması olarak tanımlanır. ÖS; örüntü tanımada, istatistikte ve veri madenciliği alanında yaygın olarak
tercih edilen bir yöntemdir. ÖS, sistemin çıktı olarak belirlediği konu ile bağlantılı olan, sınıflandırma sürecinde en faydalı ve en önemli özelliklerin seçilerek veri kümesine ait özellik sayısının indirgenmesi için kullanılmaktadır. Bu işlem sayesinde, hesaplama yükü azalırken, daha yüksek sınıflandırma başarısı hedeflenmektedir. Özellik seçim metotları üç ana sınıfta toplanmaktadır. Bunlar sırasıyla; filtreleme metodu, Wrapper metodu ve Embedded metodudur.
Uygulamalarda genellikle karşılaşılan veri tipleri sürekli veya kesikli (ayrık) veri biçiminde olmaktadır. Özellikle tahmin modelleri geliştirme çalışmalarında sürekli veriden daha çok kesikli veri tercih edilmektedir. Bu tercih sebepleri ise, ayrık verilerin bilgi düzeyli şekilde gösterilebilir olması, bazı işlemler sonucu sadeleştirilmiş olması, anlaşılır ve açıklanabilir olması şeklinde sayılabilir (Olson ve Delen 2008). Sürekli verilerin kesikli verilere dönüştürülmesi için uygulanan işlemler “veri ayrıklaştırma” olarak tanımlanmaktadır (Koçoğlu 2012). Ayrıklaştırma, veri madenciliği ve makine öğrenmesi yöntemlerinde çok sık kullanılan/karşılaşan bir veri önişleme yöntemidir (Xi ve Ouyang 2000, Hsu ve ark 2003). Sürekli verileri ayrıklaştırmak için herhangi bir ön bilgiye gerek duymadan ayrıklaştırma yöntemleri sürekli verileri birçok alana gruplamaktadır. Her bir bölge farklı isimlerle adlandırılmakta ve her bir veri kendi bölgesine ilişkin isimlere atanmaktadır. Ayrıklaştırmanın başarısını etkileyen farklı parametreler bulunmaktadır. Bu parametreler; kullanılan algoritma, verinin dağılımı ve sonuç çıkarma modeli şeklinde ifade edilebilir. Verilerin ayrık hale getirilmesinde kullanılan birçok teknik bulunmaktadır. Bu çalışmada, EWD (Hsu ve ark 2003), EFD (Jiang ve ark 2009) yöntemleri kullanılmıştır.
Bu tezde optimizasyon algoritmalarının ÖS amacıyla kullanılması araştırılmıştır. Bu algoritmalar; Yapay Arı Kolonisi Algoritması, Yer çekimi Arama Algoritması, Yarasa Algoritması ve Guguk Kuşu Arama Algoritmalarıdır. Bunun yanı sıra veri kümelerindeki sürekli veriler literatürde yer alan farklı ayrıklaştırma işlemlerine tabi tutularak veriler ayrık hale getirilmiş ve elde edilen ayrık veri kümesi orijinal veri kümesi ile başarısı kıyaslanmıştır. Farklı global erişilebilir veri kümesi üzerinde ÖS ve ayrıklaştırma amacıyla farklı optimizasyon algoritmaları kullanılmış ve analiz sonuçları karşılaştırmalı olarak sunulmuştur.
1.2. Tez Çalışmasının Önemi
Özellikle son birkaç yılda yüksek boyutlu verilerin büyük ölçüde arttığı gözlemlenmiştir. Veri boyutunun yüksek olmasından dolayı hesaplama maliyeti ve hesaplama süresi benzeri değerlerde yüksek artış görülmektedir. Bu durumlardan dolayı ÖS, veri madenciliğinde önemli bir yere sahiptir. Bu çalışma, ÖS yöntemi ile dört farklı global erişilebilir veri kümelerinde, veri kümesini temsil edecek en iyi özellik alt kümesinin bulunmasına katkı sağlayacaktır.
Gerçek dünya problemlerinde problemin veri uzayı genellikle sürekli verilerden
oluşmaktadır. Sürekli verilerin anlaşılırlık ve açıklanma düzeyi daha karmaşık olduğundan ayrıklaştırma yöntemlerine ihtiyaç duyulmaktadır. Bu sebeplerden ötürü, ayrıklaştırma yöntemleri ile de sürekli veriler ayrık hale getirilerek bilgi düzeyli ve sade bir formata getirilecektir. Ayrık hale getirilen veri kümeleri üzerinde sınıflandırma işlemi sonucu elde edilen eğitim ve test başarıları, orijinal veri setleri ile kıyaslanarak ayrıklaştırmanın başarısı ve ne kadar önemli olduğu görülecektir.
2. KAYNAK ARAŞTIRMASI
2.1. Optimizasyon Algoritmaları Yardımıyla Sınıflandırma ve Destek Vektör Makinaları ile İle İlgili Literatür Çalışmaları
García Nieto ve ark (2016), Spirulina platensis’in başarılı bir büyüme evresini tahmin etmek amacıyla DVM’yi PSO ile birlikte kullanarak hibrit bir model önermiştir. Bu optimizasyon mekanizması DVM’nin eğitim aşamasındaki çekirdek parametre ayarlamasını içermektedir. Bu çalışmada DVM’nin doğrusal, kuadratik ve RBF olmak üzere üç farklı regresyonu yapılmıştır. Deneysel veriler PSO-DVM modelinin iyi bir model olduğunu doğrulamıştır.
Aydin ve ark (2011), DVM’nin parametre optimizasyonu için çok amaçlı yapay bağışıklık Algoritmasını kullanmışlardır. Önerilen sistemde DVM’nin çekirdek ve ceza parametrelerini optimize etmek hedeflenmiştir. Önerilen algoritma, anomali tespit problemleri ve indüksiyon motorlarının hata tespitine başarılı bir şekilde uygulanmış ve başarılı sonuçlar elde edilmiştir.
Cheng ve Juang (2011), TS tipli bulanık sınıflandırıcı ile eğitilmiş artımsal bir DVM sunmuşlardır (ISVM-FC). Önerilen bu yöntem Gaussian çekirdekli DVM ile kıyaslanmış ve test süresinin ve eğitim başarısının daha iyi olduğu tespit edilmiştir. Buna ek olarak önerilen yöntemin genelleştirme özelliğini kaybetmeden sınıflandırıcı depolaması için hafıza kullanımını da azalttığı görülmüştür.
Choi ve ark (2011), ret seçenekli DVM’yi kullanarak kanser sınıflandırması için gen tahmini ve seçimi yapmışlardır. Sonuçlar standart DVM ile kıyaslandığında önerilen DVM’nin tahminsel hataları ciddi oranda azalttığı görülmüştür.
Gang ve Zhuping (2011), DVM ile PSO’yu birlikte kullanarak trafik güvenliği tahmin modeline uygulamışlardır. GBYSA’nın dezavantajlarını çözmek için bu yaklaşımı önermişlerdir. 1970-2006 yılları arasında Çin’deki trafik verileri alınarak yapılan çalışmada PSO-DVM’nin GBYSA’dan daha iyi tahminler ürettiği görülmüştür.
Liu ve ark (2011), ÖS için iyileştirilmiş PSO’yu önermişlerdir. Çalışmada ayrık problemlerin çözümü için çoklu sürü PSO (ÇSPSO)’yu önermişler. Önerilen bu algoritma ile DVM birleştirilerek önerilen iyileştirilmiş ÖS’nin (İÖS) standart PSO ve GA’ya göre tahmin kesinliği açısından çok daha iyi sonuçlar ortaya koyduğu belirtilmiştir.
Rubio ve ark (2011), zaman serisi tahmini uygulamasını gerçekleştirmek için LS-DVM’de parametre seçimi için sezgisel bir yöntemi literatüre kazandırmışlardır.
Wang ve Meng (2011), DVM’nin parametre seçimi algoritması olarak PSO’yu kullanmışlar ve önerilen modelin YSA’dan hızlı yakınsama, yüksek genelleştirme yeteneği ve basit yapısı gibi özelliklerinden dolayı daha avantajlı olduğunu ifade etmişlerdir.
Yu ve ark (2011), görüntü bölütlemeye uygulamak için destek vektörlerinin özelliklerine ve budama stratejisine dayalı bir modifiye DVM önermişlerdir. Önerilen yaklaşım gerçek görüntüler üzerinde test edilmiş ve hesaplama maliyetinde önemli bir düşüş sağlanmıştır. Bununla birlikte önerilen DVM’nin görüntü bölütleme işleminde de oldukça iyi çalıştığı gözlemlenmiştir.
Bhadra ve ark (2012), meta sınıflandırıcı tasarımı için DEA tabanlı DVM parametrelerinin optimizasyonu üzerinde çalışmışlardır. Önerilen meta sınıflandırıcının klasik sınıflandırıcılardan daha iyi olduğu tespit edilmiştir.
Boubezoul ve Paris (2012) Cross-Entropy isimli metodun kullanımına dayalı global bir optimizasyon yaklaşımı ile eş zamanlı hem hiper parametre hem de özellik alt kümesinin optimizasyonunu gerektiren problemlerin çözümünü hedeflemişlerdir.
Dehuai ve ark (2012), Isıl İşlem Algoritması kullanarak DVM tabanlı bir sıcaklık tahmini yapmışlardır. Önerilen yöntemi PSO-DVM ile kıyasladıklarında yeni yöntemin daha iyi sonuç elde ettiği tespit edilmiştir.
Guo ve ark (2012), GA kullanarak iyileştirilmiş DVM tabanlı petrol fiyat tahmin modelini geliştirmişlerdir. Önerilen sistemde, DVM’nin ceza parametresi ve çekirdek parametresi GA ile optimize edilmiş olup gerçek dünya verileri kullanılarak elde edilen sonuçlar kıyaslandığında önerilen sistemin standart DVM’den daha iyi sonuç verdiği görülmektedir.
Hsieh ve ark (2012), PSO ve ABC Algoritması ile melezleştirilmiş sisteme dayanan ceza güdümlü DVM kullanılarak mali sıkıntı eğilim verileri üzerinde veri madenciliği çalışması yapmışlardır.
Huang (2012), DVM’yi GA ile birlikte kullanarak hibrit bir stok seçim modelini literatüre kazandırmıştır. Bu çalışmada, GA model parametrelerinin optimizasyonu için kullanılmıştır.
Nikitidis ve ark (2012), çok destekli DVM’lerin artımsal eğitimi için çarpımsal güncelleme kurallarını önermişlerdir. Önerilen çarpımsal kuralları herhangi bir öğrenme oranı parametresinden bağımsız olarak gerçekleştirmişlerdir.
Sahu ve Mishra (2012), kanser mikro dizi verileri için PSO kullanarak yeni bir özellik seçim algoritmasını (ÖSA) önermişlerdir. Önerilen yöntemi iki aşamalı olarak
gerçekleştirmişlerdir. İlk aşamada, k-means kümeleme kullanarak verileri kümele işlemini yapmışlar; ikinci evrede ise, yeni özellik alt kümelerini PSO’ya giriş değeri olarak vermişlerdir. Sonuçlar incelendiğinde, önerilen sistemin literatürdekilere göre daha iyi olduğu gözlemlenmiştir.
Sartakhti ve ark (2012), Isıl İşlem Algoritması ile birlikte DVM’ye dayanan yeni bir hibrit sistem kullanarak hepatit hastalıklarının teşhisi üzerinde çalışma yapmışlardır. UCI makine öğrenmesi veri tabanından alınan veri setleri üzerinde yapılan testlerde önerilen hibrit sistemin literatürdeki diğer sınıflandırma metotlarına göre çok daha iyi olduğu görülmüştür.
Zhou ve ark (2012), Karınca Koloni Algoritması (KKA) ile birlikte DVM
regresyonu kullanarak kömür yakıtlı kazanlardan ortaya çıkan NOx emisyonu
modellemesi üzerinde bir çalışma yapmışlardır. Çalışmada kullanılan KKA’nın yüksek oranında DVM’nin optimal parametrelerini otomatik olarak elde ettiği görülmüştür.
Zhou ve ark (2012), sezgisel yöntemlerle DVM’yi birlikte kullanarak yer altındaki kaya patlamalarına uzun vadeli tahmin modeli geliştirmeyi önermişlerdir. Sezgisel yöntem olarak PSO ve GA’yı çalışmalarında kullanmış olan Zhou ve ark (2012) bu yöntemleri DVM ile hibrit olarak kullanmışlardır. PSO-DVM ve GA-DVM
isimli geliştirdikleri hibrit modelleri DVM’nin grid arama yöntemiyle
karşılaştırmışlardır. Ortaya çıkan sonuçlar yeni yöntemin ikisinin de grid arama yönteminden daha hızlı olduğunu göstermekle beraber kararlı bir yapıya sahip olduğunu da göstermiştir.
Bao ve ark (2013), DVM’lerin parametre optimizasyonu için PSO ve örüntü arama tabanlı memetik bir algoritma geliştirmişlerdir. Önerilen memetik algoritmasının kararlı ve etkili olduğu görülmüştür.
Che (2013), adaptif PSO (APSO) ve optimal eğitim alt kümesine dayanan DVM regresyonu üzerinde bir çalışma yapmıştır. Önerilen yöntemde DVM’nin parametre seçimi için APSO kullanılmıştır. UCI veri seti ve elektrik yük tahmin verileri kullanılarak elde edilen deneysel sonuçlar incelendiğinde önerilen yöntemin başarılı olduğu ve daha iyi genelleştirme performansı ürettiği tespit edilmiştir.
Chen ve ark (2013), DVM’leri hızlandırmak için hızlı ÖS yöntemini önermişlerdir. Bu çalışmada özellikle çok sınıflı problemler için ÖS yöntemini önermişlerdir. Çeşitli veri kümeleri üzerinde deneyler yapılmış ve önerilen yöntemin en rekabetçi algoritmalara göre çoğu veri kümesinde daha yüksek sınıflandırma doğruluğu verdiği görülmüştür.
Ilhan ve Tezel (2013), tek nükleotid polimorfizmlerinin (TNP) seçimi için parametre optimizasyonlu DVM’yi kullanmışlardır. Çalışmada, TNP’lerin tahmini DVM ile TNP taglarının seçimi ise GA tarafından yapılmıştır. DVM’nin parametreleri olan c ve γ’nin optimizasyonu için PSO kullanılmışlardır. Diğer metotlarla kıyaslandığında çalışmanın TNP tag belirlemede daha yüksek tahmin yüzdesine sahip olduğu gözlemlenmiştir.
Kuo ve ark (2013), radyo frekans tanımlama tabanlı konumlandırma için yapay bağışıklık sistemi (YBS) ve PSO ile elde edilen hibrit sistem tabanlı DVM (HBP-DVM)’yi literatüre kazandırmışlardır. Altı farklı benchmark fonksiyonu ile UCI makine öğrenmesi kütüphanesinden farklı veri setleri üzerinde testler yapılmış olup HBP-DVM isimli hibrit sistem, PSO-DVM ve YBS-DVM ile kıyaslanmıştır. Sonuçlara bakıldığında HBP-DVM’nin PSO-DVM ve YBS-DVM’den doğruluk oranı açısından daha yüksek başarı kaydettiği tespit edilmiştir.
Liu ve ark (2013), aqua-kültürü su kalite tahmini konusunda GA optimizasyonu ile DVM regresyonunun (GA-DVR) hibrit bir yaklaşımını önermişlerdir. Bu çalışmada gerçek değerli GA kullanılarak optimal destek vektör regresyon parametreleri araştırılmıştır. Çalışmanın sonuçlarına bakıldığında önerilen GA-DVR’nin, standart GA-DVR’den ve GBYSA’dan daha iyi performans sağladığı görülmüştür.
Peng ve ark (2013), ikili sınıflandırma problemleri için yapısal ikiz parametrik-margin destek vektör makinesini literatüre kazandırmışlardır. Önerilen bu yöntemin genelleştirme performansı açısından diğer öğrenme algoritmalarından daha başarılı olduğu görülmüştür.
Vieira ve ark (2013), septik hastalarının hayatta kalma tahmin çalışmasını yapmak için DVM’yi kullanarak ÖS’yi gerçekleştirmek amacıyla yeni bir ikili PSO (MİPSO)’yu önermişlerdir. MİPSO çeşitli benchmark veri setleri üzerinde test edilmiş olup, önerilen bu yöntem PSO tabanlı diğer algoritmalarla ve GA ile de karşılaştırılmıştır. Sonuçlar incelendiğinde MİPSO’nun sınıflandırma başarısının diğer yöntemlerden daha başarılı sonuç verdiği görülmüştür. Bununla birlikte alt küme çözümlerinin daha az özelliğe sahip olması da MİPSO’nun bir avantajı olarak tespit edilmiştir.
Carrizosa ve ark (2014), DVM için parametre ayarlamasında sezgisel bir nested yöntem önermişlerdir. Çalışmalarında, grid arama yönteminin uygun olmadığı Multiple Kernel Learning ayarlama problemleri üzerine odaklanmışlardır.
Chou ve ark (2014), sınıflandırma problemleri için hızlı bir dağınık GA
kullanarak (hdGA) DVM’nin çekirdek parametrelerini optimize etmeyi
hedeflemişlerdir. Bu çalışmada, hdGA parametre optimizasyonu yaparken, DVM ise eğri uydurma ve öğrenmeyi sağlamaktadır. Önerilen hdGA tabanlı DVM’nin cross-fold tahmin başarısı açısından CART, CHAID, QUEST, ve C5.0 gibi modellerden daha yüksek olduğu tespit edilmiştir.
Devos ve ark (2014), spektroskopik zeytinyağı verilerine uygulanan paralel GA’ya dayalı eş zamanlı veri ön-işlemeyi ve DVM sınıflandırma modeli seçimini literatüre kazandırmışlardır. Bu yöntem İtalyan zeytinyağının coğrafi kökeninin tespiti/ayrımı amaçlı yakın kızılötesi (NIR) ya da orta kızılötesi (FTIR) spektrumlar yardımıyla test edilmiştir.
Feng ve ark (2014), karınca koloni ağı ile DVM’yi birlikte kullanarak (KKO-DVM) izinsiz ağa girişlerin tespiti amacıyla network verileri üzerinde çalışma yapmışlardır. Önerilen yöntemi standard benchmark KDD99 veri kümesine uygulamışlar ve sonuçları salt DVM ve KKO ile karşılaştırmışlardır. Her iki yöntemden de gerek sınıflandırma gerekse çalışma zamanı bakımından önerilen KKO-DVM’nin daha iyi olduğu görülmüştür.
Güraksın ve ark (2014), kemik yaşı belirlenmesinde PSO’ya dayanan DVM sınıflandırma yöntemini önermişlerdir. Bu işlemi gerçekleştirirken öncelikle görüntü işleme tekniğini kullanarak özellik çıkarımı yapmışlardır. Elde edilen bu özellikleri daha sonra sınıflandırıcıya giriş verisi olarak vermişlerdir. Yeni eğitim örneğini oluşturmak için de PSO Algoritmasını kullanmışlardır. Önerilen yöntem, naive Bayes, en yakın komşuluk (k-NN), DVM ve C4.5 algoritmalarıyla kıyaslandığında önerilen yöntemin diğer algoritmalardan daha iyi olduğu tespit edilmiştir.
Han ve ark (2014), GSA kullanılarak özellik alt küme seçimi (ÖAS) üzerinde çalışmışlardır. Önerilen algoritmanın, iyi bilinen benzer sınıflandırma sistemlerinden ayırt edici giriş özelliklerini seçme ve yüksek sınıflandırma doğruluğu açısından daha iyi olduğu görülmüştür.
Hsieh ve Hu (2014), DVM ile çok amaçlı PSO (ÇAPSO)’yu birlikte kullanarak geliştirilen hibrit bir sistemle parmak tanıma üzerine bir çalışma gerçekleştirmişlerdir. Önerilen sistemin uygunluğu NIST-4 isimli veri tabanı üzerinde test edilmiştir. Sonuçların beklenildiği gibi iyi değerlere sahip olduğu gözlemlenmiştir.
Hu ve ark (2014), DVR kullanarak kısa vadede yük tahmininde model seçimi için PSO tabanlı memetik bir algoritmayı önermişlerdir. Model seçimi için kullanılan
önerilen yöntemin yararları iki gerçek dünya elektrik yük problemi üzerinde doğrulanmıştır.
Maldonado ve ark (2014), melez tamsayı programlama ile DVM için ÖS üzerine çalışma gerçekleştirmişlerdir. Önerilen yöntemde optimizasyon modeli kullanarak sınıflandırıcıyı oluşturmakla beraber eş zamanlı olarak değişken seçimini de önermişlerdir.
Miranda ve ark (2014), DVM parametre seçim problemi için ÇAPSO ile meta öğrenmeyi kombine bir şekilde kullanarak çok amaçlı hibrit bir mimari önermişlerdir. Çalışmada DVM’nin konfigürasyonuna ilişkin başlangıç Pareto yüzeyini önermek için meta öğrenmeyi kullanmışlardır. Önerilen yöntem yüz sınıflandırma problemleri olan bir veri kümesi içinde yüksek kaliteye sahip Pareto yüzeyleri elde edilerek geleneksel çok amaçlı optimizasyon algoritmalarıyla kıyaslanmıştır.
Shokri ve ark (2014), hibrit meta-sezgisel algoritmalar ile DVR’yi birlikte kullanarak üretim kalitesine ilişkin yüksek güvenilirlik tahmini üzerinde çalışmışlardır. DVR kullanılarak işlenmiş gaz yağındaki sülfürün kalitesinin tahmini için meta-sezgisel yöntemlerle önerilen yöntem karşılaştırılmıştır. Meta-sezgisel yöntemler kullanılarak optimize edilen hiper parametreler yardımıyla sülfür kalitesinin tahmini için önerilen yöntemin hem doğruluk oranında hem de hesaplama zamanında daha iyi performans sağladığı görülmüştür.
Sun ve ark (2014), DVR yaklaşımı ile belirlenen çekirdek merkezleriyle yeni bir çevrim içi adaptif çekirdek metodunu önermişlerdir. Benchmark veri kümeleri kullanılarak yapılan nümerik deneyler önerilen algoritmanın etkinliğini ve geçerliliğini doğrulamaktadır. Önerilen yöntemde merkezlerin hesaplanması k-ortalama küme yaklaşımı ile yapılmıştır.
Wang ve Du (2014), Tayvan’daki üreticilerin ana kart sevkiyat tahmininin gerçekleştirmek amacıyla DEA ile DVR’yi birlikte kullanmışlardır. Önerilen yöntem, Bass difüzyon ve genelleştirilmiş Bass difüzyon modeli ile karşılaştırıldığında, önerilen yöntemin model uyumu ve tahmin netliği açısından daha yüksek performans sergilediği tespit edilmiştir.
Zhai ve Jiang (2014), ağaç hedef tanıma sistemi yoluyla otomatik duyuların tespiti için yeni geliştirilmiş adaptif kaotik PSO ile eğitilmiş DVM kullanmışlardır.
Önerilen PSO Algoritması DVM’nin parametrelerinin optimizasyonunu
gerçekleştirmiştir. Çalışmada, hedeflere ait özelliklerin çıkartılması için temel bileşen analizi (TBA) kullanılmıştır. Ardından, özelliklere ait gereksiz ve ilgisiz bilgilerin
kaldırılması için hibrit bir ÖS metodu kullanılmıştır. Farklı gerçek ölçüm veri setleri önerilen yöntemin etkinliğini doğrulamıştır.
Zhou ve Dickerson (2014), biyo-işaretçilerin tespiti için yeni bir sınıf bağımlı ÖS metodunu kullanmışlardır. Önerilen yöntemi gerçekleştirmek için F-istatistik, maksimum ilgili İkili PSO ve sınıf bağımlı çoklu kategori sınıflandırma sistemini bir arada kullanmışlardır. Önerilen yöntemin performansını analiz etmek için sekiz gerçek kanser veri kümesi kullanılmıştır. Sonuçlar sınıf bağımlı yaklaşımların her bir kanser tipi için biyo-işaretçileri etkili bir şekilde belirleyebildiğini göstermiştir.
Chen ve ark (2015), elektrik yük tahmini yapmak için yapay zekâ ve DVM’ye dayalı yeni bir hibrit uygulama algoritması gerçekleştirmişlerdir. Deneysel mod analizi, mevsimsel düzeltme, PSO ve en küçük kareler DVM’ye dayalı yeni bir kombine tahmin modeli önermişlerdir.
García Nieto ve ark (2015), uçak motorlarının kalan yararlı ömürlerinin tahmini için hibrit bir DVM-PSO tabanlı bir model geliştirmişlerdir. Kullanılan PSO algoritması DVM eğitim aşamasında regresyon doğruluğunu önemli ölçüde etkileyen çekirdek parametresinin ayarlamasını gerçekleştirmiştir. Tahmin modelinin en temel avantajı ise makinanın önceki operasyon durumları hakkında bilgiye gerek duymamasıdır.
Harish ve ark (2015), tekrar şekil almayan dalgakıranların zarar seviye tahmini yapmak için PSO tabanlı DVM’yi literatüre kazandırmışlardır. Çalışmada, PSO-DVM’nin optimal çekirdek parametreleri PSO tarafından belirlenmiştir. Her iki model de Uygulamalı Mekanik ve Hidrolik Anabilim Dalı Deniz Yapıları Laboratuvarında yapılan deneylerden elde edilen veri setinde test edilmiştir. Sonuçlar korelasyon katsayısı, quadratik hata ve dağılım indeksi gibi istatiksel ölçümlere göre değerlendirilmiştir. Polinomal çekirdek fonksiyonuna sahip PSO-DVM’nin diğer DVM modellerinden yüksek başarı gösterdiği tespit edilmiştir.
2.2. Özellik Seçimi ile İle İlgili Literatür Çalışmaları
Chen ve ark (2011), karınca koloni optimizasyonuna (KKO) dayalı görüntü ÖS üzerinde çalışmışlardır. KKO Algoritması sınıflandırma performansı ve özellik alt küme boyutu açısından sezgisel bilgi yoluyla özellik alt kümesini seçmektedir. Çeşitli görüntüler kullanılarak elde edilen sonuçlarda daha az özellikli alt kümelerle daha iyi sınıflandırma doğruluğu elde edilmiştir.
Chuang ve ark (2011), ÖS için yayın balığı etkisi kullanılarak iyileştirilmiş ikili PSO (İPSO) üzerinde çalışmışlardır. Çalışmada, İPSO’nun performansını artırmak için yayın balığı etkisi kullanılmıştır. Bu işlem global en iyi değerin belli bir ardışık iterasyonda iyileşmeme sonucunda en kötü bireyin yerine yeni bireyin popülasyona dahil edilmesi ile gerçekleştirilmiştir. Çözümlerin kalitesinin tespiti için k-en yakın komşuluk (KNN) algoritması kullanılmıştır. Literatürden alınan 10 adet sınıflandırma problemiyle yeni önerilen İPSO karşılaştırılmıştır. Sonuçlar önerilen İPSO’nun etkili bir şekilde ÖS işlemini basitleştirdiğini göstermiştir.
Chuang ve ark (2011), çalışmalarında çadır ve lojistik isimli iki tane kaotik haritayı İPSO’ya dâhil etmişlerdir. Ortaya çıkan kaotik İPSO (KİPSO)’yu ÖS için kullanmışlardır. Önerilen sistemde sınıflandırma kesinliğinin hesabı için bir sınıflandırıcı olarak KNN’i kullanmışlardır.
Garcia ve ark (2011), gen ifade mikro dizilerinde ÖS metotları hesabı için kümelemeyle elde edilen indekslerin çok amaçlı optimizasyonu üzerinde çalışma gerçekleştirmişlerdir.
Han ve ark (2011), parametre optimizasyonuna ve ÖS’ye dayalı transformatör hata tespiti üzerinde çalışmışlardır. Çalışmada parametre optimizasyonu için GA tercih edilmiştir.
Lee ve ark (2011), parametre optimizasyonuna ve ÖS kullanarak maliyete duyarlı spam tespiti yapmak amaçlı bir yöntem geliştirmişlerdir. Saptama oranlarını maksimize etmek için, Random Forests kullanarak tespit modelin iki parametresini optimize etmişlerdir. Her özellik eleme evresinde parametre optimizasyonu ve genel ÖS’de sadece bir parametre optimizasyonu metotlarıyla seçilen özelliklerin optimal sayısına karar verilmiştir.
Manimala ve ark (2011), iki yeni wrapper tabanlı hibrit yumuşak hesaplama tekniğini dokuz farklı enerji arızasını sınıflandırmak amacıyla DVM’nin sınıflandırma doğruluğunu düşürmeden ÖS ve parametre optimizasyonu için önermişlerdir. Geleneksel grid arama yöntemiyle kıyasladığında, gereksiz özelliklerin veri kümesinden çıkartılması ve sınıflandırıcı için hazır parametre seçiminden dolayı GA ve ışıl işlem tabanlı yaklaşımların daha iyi sonuçlar elde etmişlerdir.
Pan ve ark (2011), İPSO ile çok ölçekli ÖS kullanarak yüz tanıma için farklı türdeki özellikleri birleştirme üzerine çalışmışlardır. ÖS yöntemi İPSO algoritmasını kullanarak her bir ölçek seviyesinde tüm arama uzayını araştırır ve en yüksek doğruluk oranına sahip minimum sayıdaki özellik alt kümeyi seçer.
Song ve ark (2011), ayrık PSO’ya ve en küçük kareler DVM (KKDVM)’ye dayalı yeni bir ÖSA önermişlerdir. Önerilen algoritma, KKDVM’yi kolay çözme ve PSO evresinde uygunluk fonksiyonlarının temel parçası olarak sınıflandırma doğruluğunu kullanma avantajlarına sahiptir. Önerilen algoritmanın sınıflandırıcıya çok büyük katkıları olabilecek özellikleri elde edebileceği simülasyon sonuçlarında görülmüştür.
Wu ve ark (2011), kaba kümeleme ve KKO algoritmasını bir arada kullanan ÖS metodunu geliştirmişlerdir. Önerilen yöntemde, özellik alt küme uzunluğu feromen güncelleme stratejisini geliştirmek için kullanılmışlardır.
Zhao ve ark (2011), DVM’nin asimptot özellikleriyle GA birleştirilerek ÖS ve parametre optimizasyonu üzerinde çalışmışlardır. Çalışmada, GA’nın arama uzayını yöneten özellik kromozomlarını üretmişlerdir. Deneysel çalışmaları UCI’den aldıkları gerçek dünya problemleri ve Benchmark veri tabanındaki veri setleri ile gerçekleştirmişlerdir. Grid arama, özellik kromozomlarına sahip olmayan GA ve diğer yaklaşımlarla kıyas edildiğinde, önerilen yöntemin yüksek sınıflandırma doğruluğuna ve daha az özellik alt kümesine sahip olduğu görülmüştür. Buna ek olarak önerilen sistemin daha az işlem süresiyle sonuca vardığı görülmüştür.
Hacıbeyoglu (2012), disjunktif normal formun indirgenmiş fark fonksiyonundan elde edilmesi yöntemini geliştirmiş ve bu yolla karmaşıklık işlemi kendi kareköküne kadar azaltılmıştır. Böylece, iki aşamadan oluşan lojik fonksiyon tabanlı bir ÖS yöntemi geliştirilmiştir. Birinci aşamada veri kümesinin doğruluk tablosu kullanılarak indirgenmiş fark fonksiyonu oluşturulur, ikinci aşamada ise elde edilen indirgenmiş fark fonksiyonu iteratif olarak bölünerek disjunktif normal forma dönüştürülür ve böylece işlenmekte olan veri kümesine ait özelliklerin en küçük alt kümeleri elde edilir. Bu özelliği sayesinde, geliştirilen ÖS yönteminin diğer ÖS yöntemleri ile işlenemeyen veri setlerini de başarıyla işleyebildiği gözlemlenmiştir.
Ahila ve ark (2012), enerji sistemleri arızalarında olasılıksal sinir ağları (OSA) için eş zamanlı model ve ÖS’yi gerçekleştiren PSO algoritmasını geliştirmişlerdir. OSA’da çok dikkat edilmeyen noktalardan birisi genişleme parametresinin seçilmesidir. PSO-OSA yaklaşımıyla yararlı özellikler seçilirken aynı zamanda OSA’nın performansını artırmak için genişleme parametresi belirlenmiştir. Deneysel çalışmalarda OSA için ayırıcı giriş özellikleriyle sınıflandırma doğruluğunun önemli ölçüde arttığı tespit edilmiştir.
Aneesh ve ark (2012), çalışmalarında parçacıkların zeki davranışlarıyla hızlandırılmış İPSO’yu önermişlerdir. Çözünürlük dönüşümü, histogram eşitleme ve kenar bulma gibi görüntü ön işleme teknikleriyle birlikte hızlandırılmış İPSO yöntemini tanıma oranını artırmak ve ÖS için özellik alt kümesini azaltmak amacıyla kullanılmıştır.
Cervante ve ark (2012), İPSO’ya ve bilgi teorisine dayanan sınıflandırma problemleri için iki yeni filtreleme ÖS yöntemi geliştirmişlerdir. İlk algoritma PSO’ya ve seçilen özellik alt kümesinin bağlantısını belirleyen her bir çift özelliğin karşılıklı bilgisine dayanır. İkinci algoritma ise PSO’ya ve her bir grup özelliğin entropisine dayanır. Sonuçlar incelendiğinde, ilk algoritmanın daha az özelliğe sahip alt küme bulurken ikincisinin de daha yüksek başarı kaydettiği görülmüştür.
Adam ve ark (2014) , EEG sinyallerinde zirve tespiti amacıyla PSO algoritması kullanarak ÖS ve sınıflandırıcı parametre tahmini üzerinde çalışmışlardır. Çalışmada standart PSO ve random asenkron PSO olmak üzere iki farklı PSO modeli kullanılmıştır. Random asenkron PSO’nun standart PSO’ya göre daha iyi ve güvenli sınıflandırma oranı verdiği gözlemlenmiştir.
De la Hoz ve ark (2014), çok amaçlı optimizasyon ile ÖS üzerinde yaptıkları çalışmada kendini organize eden hiyerarşik haritalar yardımıyla ağ içindeki kusurların tespiti amaçlı bir uygulama geliştirmişlerdir. Önerilen yöntemin performans analizini görmek için DARPA/NSL-KDD veri kümesi kullanılmıştır.
Erguzel ve ark (2014), teta ve delta frekans bantlarından 6 kanal tedavi öncesi verileri için GBYSA sınıflandırma metodu ile KKO algoritmasını hibrit kullanmışlardır.
Forsati ve ark (2014), çalışmalarında KKO algoritmasının yeni bir versiyonu olan zenginleştirilmiş KKO (ZKKO) algoritmasını geliştirmişler ve uygulamasını da ÖS üzerinde yapmışlardır. Önerilen algoritmanın etkinliğini göstermek için çeşitli standart veri setleri üzerinde kappa testi ve sınıflandırma doğruluğu şeklinde iki farklı ölçüm kullanarak deneysel çalışmalar yapılmıştır.
Ghamisi ve Benediktsson (2014), Salinas hiperspektral veri kümesi üzerinde yaptıkları çalışmada GA ve PSO’nun birlikte kullanımıyla ÖS’yi gerçekleştirmişlerdir. Önerilen yöntemin uygun bir CPU zamanı içerisinde en öğretici özellikleri otomatik olarak seçebildiği doğrulanmıştır.
Han ve ark (2014), modifiye edilmiş GSA (MGSA) ile ÖAS yöntemini geliştirmişlerdir. MGSA’nın başarısındaki temel nokta türlerin çeşitliliğini artırmak için parçalı lineer kaotik bir harita kullanılması ve lokal kullanımı artırmak için sıralı
quadratik programlamanın kullanılmış olmasıdır. MGSA CEC 2015 özel oturumdan elde edilen 10 fonksiyon üzerinde test edilmiştir. Sonuçlar farklı MGSA, PSO ve GA karşılaştırılmıştır. Elde edilen sonuçlar önerilen MGSA’nın optimizasyon alanında çeşitli problemleri çözmede daha yüksek performans sergilediğini göstermiştir.
Olfati ve ark (2014), Wisconsin göğüs kanseri teşhisinde DVM için ÖAS ve parametre optimizasyonu üzerinde yaptıkları çalışmada özellik azaltma için TBA, ÖS için GA ve sınıflandırma için de DVM’yi kullanmışlardır. Bu yaklaşım özellik sayısını minimize etmenin yanında duyarlılık, spesifiklik ve alıcı işlem karakteristik eğrisini maksimuma taşıyacak özelliklere sahip optimal sınıflandırmayı sağlamıştır. Test aşamasında 10 fold çapraz geçerleme yapılmıştır. Geliştirilen TBA+GA+DVM sistemi iki özellik içeren alt küme için %100 başarı elde etmiştir.
Saha ve ark (2014), ısıl işlem tabanlı çok amaçlı optimizasyon (IİÇAO) kullanarak yarı denetimli öğrenme ve ÖS ile ilgili problemleri çözmüşlerdir. Önerilen IİÇAO yöntemi verilen herhangi bir veri setinde uygun bölünmenin yanı sıra uygun sayıda kümeleme ve uygun özellik alt kümelerini belirlemek için kullanılmıştır. Sarac ve Ozel (2014), web sayfalarının sınıflandırma doğruluğunu artırmak ve çalışma süresini iyileştirmek amacıyla özellik sayısını azaltacak KKO algoritması tabanlı bir ÖS yöntemi geliştirmişlerdir. Deneylerde WebKB ve Conference veri setleri tercih edilmiştir. KKO tabanlı ÖS’nin bilgi kazancı ve chi kare ÖS yöntemlerine göre daha iyi sonuçlar verdiği görülmüştür.
Wang ve ark (2014), KİPSO algoritması, korelasyon analizi ve özellik derecelendirme kullanarak sınıflandırma performansının iyileştirilmesi ve gereksiz özelliklerin azaltılmasına odaklanan çok aşamalı bir ÖSA geliştirmişlerdir. İlk aşamada, özellik derecelendirme ile sınıflandırma doğruluğuna göre derecesi en yüksek olan özellikler seçilmiştir. İkinci evrede, gereksiz özelliklerin çıkartılması amacıyla en yüksek başarı derecesine sahip seçilen özellikler arasında korelasyonu ölçmek için korelasyon analizi kullanılmıştır. Son evrede ise KİPSO ile optimal alt küme seçimi yapılmıştır. N-kat çapraz doğrulama yapılarak DVM 6 farklı veri kümesi üzerinde deneysel çalışmaya tabi tutulmuştur.
Wang ve ark (2014), boyut azaltmak amacıyla bakteri kolonisi algoritmasına (BKA) dayalı yeni bir ağırlıklandırılmış ÖS geliştirmişlerdir. Ağırlıklandırma stratejisi aynı bireyde tekrar eden görünümün yanı sıra BKO ile seçilen özelliklerin frekansını dikkate alan bir stratejidir. Bununla birlikte öğrenme stratejisini oluştururken görünmeyen özelliklere ait bilgisizlik tarafını engelleyen rastsallığı dikkate almışlardır.
Önerilen yöntemin etkinliğini görmek için farklı boyutlardaki benchmark fonksiyonları ile testler yapılmıştır. Önerilen ağırlıklandırılmış ÖSA son zamanlarda önerilmiş olan üç farklı popülasyon tabanlı ÖSA ile karşılaştırılmış ve önerilen sistemin başarısı doğrulanmıştır.
Xue ve ark (2014), arama aşamasında elde edilen daha önemli çözümleri depolayacak harici bir arşive sahip yeni bir PSO tabanlı ÖSA’yı geliştirmişlerdir. Önerilen yöntemin iki özel metodu bulunmaktadır. PSOArR arşivden gbest değerini rastsal olarak seçmektedir. PSOArRWS ise hem özellik sayısını hem de sınıflandırma hata oranını düşünerek gbest değerini seçmek için rulet tekerleği seçim yöntemini kullanmaktadır. 12 farklı benchmark fonksiyonu üzerinde yapılan deneysel çalışmalarda PSOArR ve PSOArRWS’nin tüm özellikler kullanılarak elde edilen başarıdan daha yüksek başarı elde ettikleri görülmüştür.
Emary ve ark (2015), optimal özellik alt kümesini bulmak için gri kurt optimizasyon yöntemiyle sınıflandırma doğruluk tabanlı uygunluk fonksiyonunu geliştirmişlerdir. Bir dizi UCI makine öğrenmesi veri kümesi üzerinde yapılan deneylerde, GA ve PSO ile kıyaslandığında hem sınıflandırma doğruluğunda hem de özellik boyut azaltmada önerilen yöntemin daha iyi sonuçlar verdiği tespit edilmiştir. Bunun dışında algoritmanın çok kararlı olduğu yapılan testlerde görülmüştür.
Banka ve Dara (2015), yüksek boyutlu ÖS, sınıflandırma ve validasyon yapmak amacıyla hamming uzaklık tabanlı İPSO algoritmasını geliştirmişlerdir. Önerilen algoritmanın verimliliğini ve üstünlüğünü göstermek için üç farklı benchmark veri kümesi üzerinde deneysel çalışmalar detaylıca yapılmıştır. Çalışma sonucunda, hazır ön işleme metotları seçerek önerilen İPSO yönteminin gen dizilimlerinde önemli özellikleri bulmayı mümkün kılacağı görülmüştür.
Ghamisi ve Benediktsson (2015), PSO ve GA’nın birleştirilmesi ile oluşan hibrit sisteme dayalı yeni bir ÖS yaklaşımı geliştirmişlerdir. Deneylerini Indian Pines Hiperspektral veri kümesi üzerinde gerçekleştirmişlerdir. Ayrıca önerilen yöntem yol tayini için de test edilmiş ve sonuçlar arka plan ve yol arasındaki farkı bulmada önerilen hibrit sistemin yetenekli olduğu tespit edilmiştir.
Lin ve ark (2015), yapay balık koloni algoritması (YBKA)’ın lokal minimuma takılma ve çeşitlilik eksikliği gibi dezavantajlarından dolayı çalışmalarında modifiye edilmiş yapay balık koloni algoritmasını (MYBKA) kullanmışlardır. MYBKA’ya dayalı DVM için ÖS ve parametre optimizasyonu üzerinde çalışmışlardır. Bilinen UCI veri
setleri üzerinde yapılan deneysel sonuçlarda daha az özellikli alt kümeler kullanarak sınıflandırma doğruluğu bakımından MYBKA’nın üstünlüğü görülmüştür.
Lin ve ark (2015), standart kedi sürüsü optimizasyonu algoritmasını (KSOA) DVM’nin parametre optimizasyonunu ve ÖS’yi lokal bir arama prosedürü ile bütünleştirmişlerdir. MKSOA ile KSOA kıyaslandığında daha az özellikle oluşturulan alt küme kullanılarak elde edilen sınıflandırma doğruluğunda MKSOA’nın daha üstün olduğu gözlemlenmiştir.
Liu ve ark (2015), moleküler imzada ÖS için ayrık biyojeografi tabanlı optimizasyon (ABTO) yöntemini geliştirmişlerdir. Çalışmada ilk olarak, Fisher-Markov seçim modelini sabit sayıdaki gen verilerini seçmek için kullanmışlardır. İkinci olarak ise, önerilen yöntemi ÖS için uygun formata getirmede algoritmanın araştırma ve kullanma yeteneğini dengelemek için ayrık mutasyon ve ayrık göç modelini kullanmışlardır. UCI’den alınan dört göğüs kanser veri kümesi ile deneysel çalışmaları yapmışlardır. Önerilen ABTO yöntemi, GA, PSO ve DEA ile kıyaslandığında ABTO’nun literatürdeki önceki yöntemlere göre daha iyi sonuç verdiği görülmüştür.
Liu ve ark (2015), HIV-1 proteazının özgünlüğünü analiz etmek ve oktapeptitlerdeki konumları bulmak amacıyla YSA optimizasyonu ile kombine edilmiş yeni bir ÖS yöntemi geliştirmişlerdir.
Moayedikia ve ark (2015), her bir yemek kaynağı için lokal ve global ağırlıkları dikkate alan ağırlıklandırılmış arı koloni optimizasyon (AAKO) algoritmasını geliştirerek ayrık problemlere uygulamışlardır. Ayrıca AAKO’yu kullanarak ÖS için bir uygulama geliştirmişlerdir. AAKO algoritmasının performansını göstermek için standart benchmark fonksiyonları kullanılarak yapılan deneylerde önerilen AAKO yönteminin yüksek performans sergilediği gözlemlenmiştir.
Moradi ve Rostami (2015), sınıflandırma problemlerini çözmek için üç aşamadan oluşan graf kümeleme yaklaşımına ve KKO algoritmasına dayalı yeni bir ÖS yöntemi geliştirmişlerdir. Bu yaklaşımların ilkinde, tüm özellik kümesini bir graf olarak temsil etmişlerdir. İkinci aşamada, bir ağ belirleme algoritması kullanılarak özellikleri belli bazı gruplara bölmüşler ve son olarak da üçüncü evrede, nihai özellik alt kümesini seçmek için KKO algoritmasına dayalı yeni bir arama stratejisi geliştirmişlerdir.
2.3. Ayrıklaştırma ile İle İlgili Literatür Çalışmaları
Jiang ve ark (2009), tahmini EFD modeli üzerinde çalışmışlardır. Önerilen bu modeli UCI veri tabanındaki veri setleri üzerinde diğer ayrıklaştırma yöntemleri ile kıyasladıklarında önerilen yöntemin etkili ve kullanışlı olduğunu görmüşlerdir.
Orhan ve ark (2012), EEG verilerinden epilepsi krizinin tespiti amacıyla EFD’ye dayalı olasılık dağılım adı verilen yeni bir özellik çıkarım yaklaşımını önermişlerdir. İki farklı olasılıksal yoğunluk fonksiyonu için ortalama karesel hata kriteri kullanıldığında epilepsi kriz tespiti üzerinde % 96.72 oranında bir başarı sergilemişlerdir. Buna ek olarak, EEG segmentinin olasılıksal yoğunluğu çok katmanlı YSA modelinin girişi olarak kullanıldığında epilepsi krizi saptama başarısının % 99.23’e çıktığı gözlemlenmiştir.
Koçoğlu (2012), veri kümelerine farklı ayrıklaştırma yöntemlerinin uygulanmasını ve hangi yöntemin daha etkin olduğu konusunun incelenmesini amaçlamıştır. Çalışma kapsamında Wisconsin veri kümesi kullanılmıştır. Bu veri kümesi üzerine KEEL veri madenciliği yazılım aracı yardımı ile 1RD, CADD, CAIM, Chi2, ChiMerge, ID3, Eşit Genişlikli, Eşit Frekanslı olmak üzere toplamda sekiz farklı ayrıklaştırma yöntemi uygulamıştır. Deneysel sonuçlar incelendiğinde; Chi2, ChiMerge, CAIM algoritmalarının önemli oranda tutarlı çalıştıkları, 1RD algoritmasının genelde bir, ID3 algoritmasının da çok sayıda kategorik değişken elde ettiği gözlemlenmiştir.
Doğan (2012), doktora tez çalışmasında ayrıklaştırma yöntemleri ve YSA kullanarak asenkron motorlarda arıza teşhisi üzerinde çalışmıştır. Çalışmasında, asenkron motorların rulman, eksenden kaçıklık, rotor çubuk kırığı ve stator sargı kısa devresi arızalarının tespitine odaklanmıştır. Bir asenkron motorun arızalarına ilişkin bu karakteristik özellikleri, motora ait akım sinyallerinin analizini kullanarak çıkarmıştır. Sinyal analiz yöntemi olarak önceki çalışmalarda yaygın olarak kullanılan frekans ve zaman-frekans yöntemleri yerine, zaman boyutunda ayrıklaştırmaya dayalı bir yöntem kullanmıştır. Gerçekleştirilen deneysel çalışmalarda farklı yük koşullarında sağlam ve arızalı durumlar için motor akım sinyalleri ölçülmüştür. Bu akım verisi zaman boyutunda EWD ve EFD yöntemleri ile ayrıklaştırılarak özellikler çıkarılmıştır. Bu özellikler ile eğitilen çok katmanlı algılayıcı YSA kullanılarak bu arızaların tespiti ve sınıflandırması gerçekleştirilmiştir. Sonuç olarak önerilen yöntemin asenkron motor arızalarının tespitinde oldukça başarılı sonuçlar verdiği görülmüştür.
Chaves ve ark (2013), emisyon bilgisayarlı tomografi görüntülerine dayalı Alzheimer hastalarının erken teşhisi için sürekli özellikleri ayrıklaştırma ve ilişkili kural çıkarma yöntemlerini bir arada kullanarak bilgisayar destekli bir teşhis sistemi geliştirmişlerdir.
Sayın (2013), veri madenciliğinin etkisini kullanarak, ÖS ve ayrıklaştırma yöntemleriyle beraber sınıflandırma algoritmalarının kullanılmasıyla koroner arterlerde kalsifikasyon olup olmadığının incelenmesinin önemini göstermiştir. Veri setinde yer alan yaş, nakil süresi, diabetik ve fosfor gibi özelliklere bakarak doktorların bir hastada kalsifikasyon olup olmadığına yaklaşık olarak %70 doğrulukta karar verebileceği bir sistem geliştirmiştir. Veri ayrıklaştırma işleminden sonra ise bu oranın %75 civarına yükseldiği gözlemlenmiştir.
Ozdemir (2014), tespit sistemlerinde kullanılan bir çok makine öğrenmesi tekniğini detaylıca incelemiştir. Başarılı bir hizmet engelleme saldırısı tespit oranına ulaşmak amacıyla, yerine geri koyarak örnekleme, ayrıklaştırma, öznitelik seçimi ve sınıflandırma yöntemlerinin birleşimini temel alan bir saldırı tespit sistemi önermiştir. Tez çalışmasında ayrıca hizmet engelleme saldırılarının tespiti üzerinde çalışmakla beraber çeşitli ağ saldırılarını ve normal ağ trafiğini doğru olarak tespit etmekle de çalışmıştır. Ayrıklaştırma yöntemi olarak; düzensiz temelli ayrıklaştırma, eşit genişlikli gruplama, eşit frekanslı gruplama ve orantısal k aralıklı yöntemlerini kullanmıştır. Karmaşıklığı azaltmak için ise, korelasyon temelli ÖS, tutarlılık temelli ÖS, bilgi kazancı temelli ÖS ve simetrik belirsizlik temelli ÖS yöntemlerini kullanmıştır. Deneysel çalışmalar için de KDD90 eğitme ve test etme verileri kullanılmıştır.
Jedrzejowicz ve Skakovski (2014), ayrık-sürekli değerlere sahip çizelgeleme problemlerini çözmek için ada tabanlı DEA’yı geliştirmişlerdir. Önerilen algoritmanın orijinal DEA’dan daha iyi çözümler bulduğu tespit edilmiştir.
Bruni ve Bianchi (2015), ayrıklaştırma ve istatistiksel analizlere dayalı küçük bir eğitim seti kullanarak etkili bir sınıflandırma yöntemi geliştirmişlerdir. Önerilen yaklaşım veri kümesi üzerinde istatistiksel faktörlerden elde edilen bilgilerle zenginleştirilerek mantıksal analiz verisi (LAD) çatısı üzerine inşa edilmiştir. Önerilen yöntem UCI veri kümesinden alınan veri setleri üzerinde standart LAD, DVM ve etiket yayılım algoritmaları ile kıyaslanmış ve sonuçların gözle görülür oranda iyi olduğu tespitine varılmıştır.
Akar ve ark (2015), çok katmanlı algılayıcı YSA modeli ve EWD’ye dayalı olasılıksal dağılımları kullanarak kalıcı mıknatıs senkron motorlarının kusurlarını
çözmeye ve statik dışmerkezliliği tespit etmeye odanlanmışlardır. Veriler EGA sayesinde birkaç belli aralığa bölünmüştür. Olasılıksal dağılım elde edilen bu ayrıklaştırılmış değerlere ait her bir aralıktaki veri sayısına göre hesaplanmıştır ve bu dağılımlar çok katmanlı YSA modeline giriş verisi olarak kullanılmıştır. Önerilen yöntem kusur saptama performansının ölçülmesi için 18 farklı şekilde deney yapılmıştır. Önerilen yöntemin bazı deneylerde yüksek hız ve tam yüklemede çok başarılı olduğu gözlemlenmiştir.
3. OPTİMİZASYON ALGORİTMALARI
Optimizasyon, bir problemde belirli kısıtlar altında mevcut olan alternatif çözümler içinden en iyisini bulma işlemi olarak tanımlanmaktadır. Literatürde optimizasyon problemleri için birçok algoritma önerilmiştir. Sezgisel algoritmalar, büyük boyutlu optimizasyon problemleri için, belli bir süre içerisinde en uygun çözüme yakın sonuçlar üretebilen algoritmalardır. Genel amaçlı sezgisel optimizasyon algoritmaları, biyoloji tabanlı, fizik tabanlı, sürü tabanlı, sosyal tabanlı, müzik tabanlı ve kimya tabanlı olmak üzere altı farklı gruba ayrılmaktadır (Akyol ve Alataş 2012). Bu tez çalışmasında sürü tabanlı algoritma grubundan olan ABC, BA, CSO algoritmaları kullanılırken, fizik tabanlı algoritma grubundan ise GSA tercih edilmiştir.
3.1. Yapay Arı Koloni Algoritması
Doğada bulunan bal arıların besin ararken kullandıkları yöntemlerden esinlenerek geliştirilmiş olan ABC algoritması, sürü zekâsına dayalı bir optimizasyon algoritmasıdır (Karaboga 2005). Doğada sürü şeklinde hareket eden arıların besin bulmada ortaya koymuş oldukları davranışlardan esinlenilen bu algoritma sayesinde genellikle optimizasyon problemlerini çözmek hedeflenmektedir.
3.1.1. Arıların yem bulma davranışları
Arı kolonisinin yaşamının devamı için en önemli işlemden birisi besin arama işlemidir. Bu süreçteki önemli parametreler ise; arılar tarafından kovanda biriktirilen kaynaklar, ortamdaki yemek kaynakları ve arıların birbirleriyle kurdukları haberleşme ağı olarak bilinir.
Arama işlemi arının kovandan ayrılmasıyla başlar ve bu süreci rastgele yapılan yiyecek aramaları takip eder. Yiyecek aramaya çıkmış olan arılar, buldukları kaynaklarda yiyecek miktarının azaldığını fark ettiklerinde, diğer arılardan aldığı bilgiye göre başka kaynaklara hareket ederler. Bu aşamada bulunan kaynaklara ait bilgilerin arılar arasında iletilmesi ve ortamdaki polen, su gibi kaynakların kovana getirilmesi işlemleri yapılır.
Tereshko’nun öngördüğü yiyecek arama modelinde üç temel öğe bulunmaktadır. Bunlar: yiyecek kaynakları, görevli arayıcılar, görevi belli olmayan arayıcılardır (Tereshko ve Loengarov 2005).
Akay, çalışmasında yiyecek kaynakları, görevli arayıcılar, görevi belli olmayan arayıcıları aşağıdaki gibi açıklamıştır (Akay 2009):
3.1.3. Yiyecek kaynakları
Arıların yiyecek bulmak için gittiği kaynaklar yiyecek kaynakları olarak isimlendirilir. Doğada bulunan bir yiyecek kaynağının değerini, kaynağın çeşidi, kaynağın yuvaya olan uzaklığı ve kaynaktaki nektar miktarı gibi birçok etken belirlemesine rağmen daha basit modellenmesi için sadece kaynağın zenginliği parametre olarak kabul edilebilir.
3.1.3. Görevi belirli işçi arılar
Daha önceden belirlenmiş kaynaklardan toplanan yiyeceğin kovana getirilmesi işini işçi arılar yerine getirmektedir. İşçi arıların bir diğer önemli görevi de gittikleri kaynağın konumu ve kaynağın kalitesi hakkında diğer arılara bilgilendirme yapmaktır. 3.1.4. Görevi belirli olmayan işçi arılar
Bu arıların yiyecek olma ihtimâli olan kaynakları arama görevleri vardır. Görevi belli olmayan iki tip işçi arı vardır. Bunlar; kâşif ve gözcü arılardır. Kâşif arılar arama bölgesinde rastgele kaynak arayan arılardır. Gözcü arılar ise kovanda bekleyen ve görevli arıları izleyen arılardır. Bunun sonucunda görevli arılar tarafından gelen bilgiyi dikkate alarak yeni kaynaklara hareket ederler.
Birliktelik yapısının ve ortak bilginin oluşmasını sağlayan en önemli konu arıların birbirleri arasındaki bilgi paylaşımı konusudur. Arılar için yaşam alanı olarak tanımlanan kovan bazı bölümlere ayrılabilir. Bilgi paylaşımının yapıldığı dans alanı bu bölümlerden bir tanesidir. Arılar yapmış olduğu dansla kendi aralarında bilgi paylaşımını sağlarlar. Paylaşılan bu bilgi sayesinde kaliteli yeni besin kaynakları bulunmuş olur (Gruter ve Farina 2009).
Kaynaklardan yiyecek getirmiş olan arıların, diğer arıların bu kaynaklara yönlendirilmesi için kaynağın konum bilgisini diğer arılara vermesi gerekir. Konum hakkında bilgiyi alan arı güneş ışığını kullanarak hedefine ulaşmış olur. Arılar sahip oldukları özellikleri gereği kendi yörüngeleri ile güneş arasındaki açıyı hesaplayabilmektedirler. Uzaklıklarını tükettikleri enerjiye göre ayarlayan arılar,
taşıdıkları yüklere göre farklı yükseklikte uçarak enerjilerini ayarlamaktadırlar. (Akay 2009).
Arıların besin arama davranışları Şekil 3.1’de gösterilmiştir. Bu davranışların şekil üzerinde incelenmesini ve açıklamalarını Akay şu şekilde gerçekleştirmiştir: Şekildeki A ve B bulunmuş kaynaklar olarak kabul edilmiştir. Başlangıçta görevi belli olmayan ve yiyecek kaynağı bilgisine sahip olmayan arı yiyecek aramaya başlayacaktır. Bu arı için iki durumdan bahsedilebilir: Birincisi; Şekil 3.1’de S ile gösterilen bu arı kâşif arı olduğu varsayılırsa bu durumda bu arı besin aramaya başlayabilir. İkincisi ise şekilde R ile gösterilen ve dans eden arıları izleyerek yönlendirilen kaynaklara giden bir gözcü arı olabilir.
Şekil 3.1. Arıların yem arama davranışları (Akay 2009)
Yiyecek için kaynaklara giden arılar kaynaklardan nektar getirmeye başlarlar. Bu durumda bu arılar görevli arıya dönüşmüş olurlar. Bu arılar için bundan sonra üç seçenek vardır:
i) Diğer arılarla herhangi bir bilgi paylaşımı yapmadan kaynaktan nektar getirme işlemine devam edebilir. Bu arı şekilde EF2 ile gösterilmiştir.