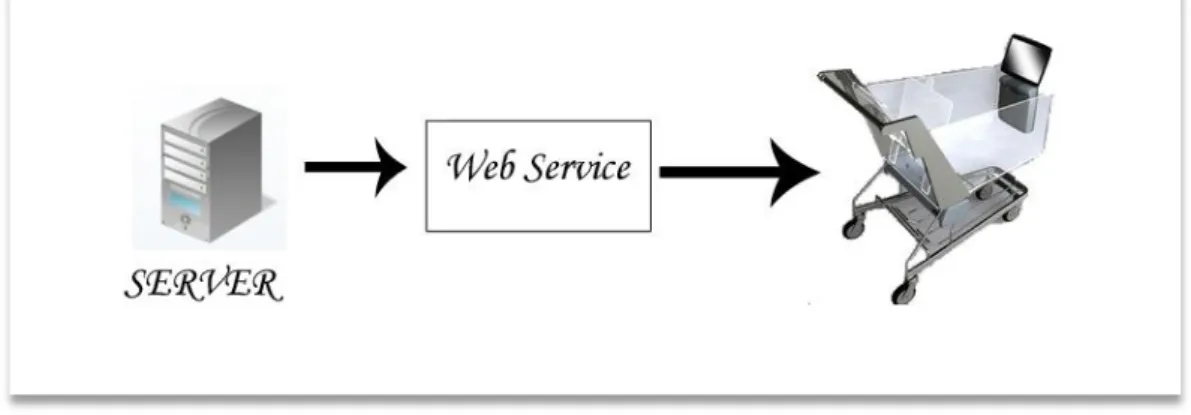
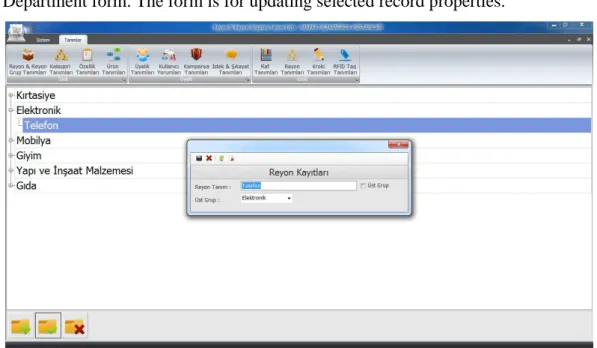
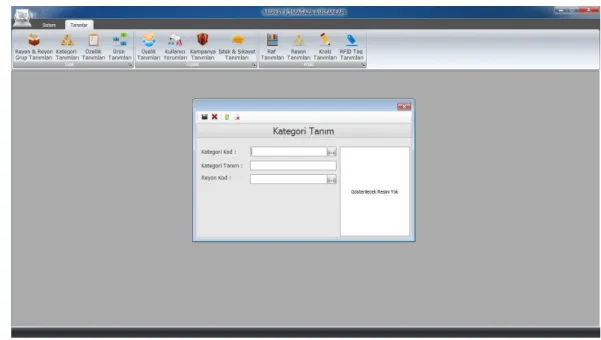
Mima : market içi mağaza asistanları
Tam metin
Şekil


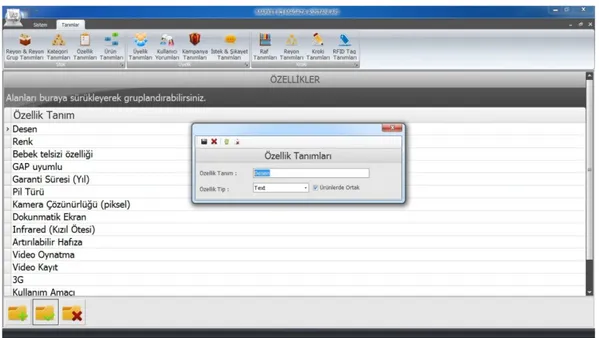
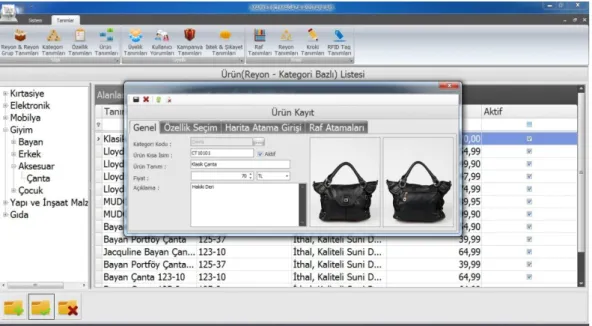
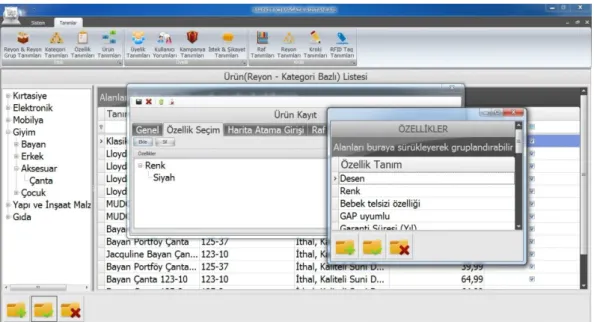
Benzer Belgeler
We found that the total (i.e., direct + indirect) effect of CP on the branch performance metrics (i.e., profitability, sales growth, and customer retention) was higher at low levels
He firmly believed t h a t unless European education is not attached with traditional education, the overall aims and objectives of education will be incomplete.. In Sir
The device consists of a compartment into which a suppository is placed and a thermostated water tank which circulates the water in this compartment.. The
I Solve for the unknown rate, and substitute the given information into the
The ability of coal to diminish the impacts of natural gas is emphasized with respect to production costs, unit costs of power generation and price of imported coal..
This model (ACSI) evaluates the cause and effect relationship, which is based on the level of customer satisfaction (perceived value, perceived service quality, and customer
Acil tıp kliniğimize lokal cilt lezyonları ile başvuran, toksik şok tablosu ile yoğun bakım ünitesinde takip ettiğimiz ikisi çoklu organ yetmezliğinden kaybettiğimiz,
Türkiye Hazır Beton Birliği Yönetim Kurulu Üyesi Cenk Eren, Çimsa Kozan Hazır Beton Tesisi Yöneticisi Volkan İşisağ’a ödülü takdim ederken4. Türkiye Hazır Beton
