364
A
COMPARISON OF LOGICAL AND
PHYSICAL
PARALLEL
I/O
PATTERNS
Huseyin
Simitci Daniel A. ReedDEPARTMENT OF COMPUTER
SCIENCE,
UNIVERSITY OF ILLI-NOIS ATURBANA-CHAMPAIGN, URBANA, ILLINOIS,
U.S.A.Address reprint requests to Huseyin Simitci, Department of Com-puter Science, University of Illinois at
Urbana-Champaign,
1304 West Springfield Avenue, Urbana, IL 61801 U.S.A., e-mail [email protected].Summary
Although
there are several extant studies ofparallel
scien-tific
application
request
patterns,
there is littleexperimen-tal data on the correlation of
physical
I/Opatterns
withapplication
I/O stimuli. To understand thesecorrelations,
the authors have instrumented the SCSI device drivers of the Intel
Paragon
OSF/1operating
system
to recordkey
physical
I/Oactivities,
and have correlated this data withthe I/O
patterns
of scientificapplications captured
via the Pabloanalysis
toolkit. Thisanalysis
shows that diskhard-ware features
profoundly
affect the distribution ofrequest
delays
and that currentparallel
filesystems respond
toparallel application
I/Opatterns
in nonscalable ways.1 Introduction
IIO for scalable
parallel
systems
continues to be themajor
performance
bottleneck for manylarge-scale
scientificapplications
(Crandall
etal., 1996;
Purakayastha
etal.,
1995).
Market forces areincreasing
thedisparity
betweenprocessor and disk
system
performance, exacerbating
thealready
difficultproblem
ofachieving high performance
forapplications
withlarge
I/Ocomponents. Moreover,
most currentparallel
filesystems
(PFS)
were constructed as extensions of workstation filesystems
and wereopti-mized for
large
sequential
data transfers.Recent
experimental
studies(Crandall
etal., 1996;
Purakayastha
etal., 1995;
Smirni andReed, 1996, 1997;
Reed, Elford,
Madhyastha,
Scullin,
etal.,
1996)
have shown thatparallel applications
have much morecomplex
accesspatterns,
withgreater
spatial
andtemporal
variabil-ity,
than firstsuspected. Although
there is alarge,
comple-mentary
body
ofexperimental
data on disk behavior(Ruemmler
andWilkes, 1993,
1994)
forsequential
filesystems, there is much less
experimental
data on thecorrelation of
physical
I/Opatterns
withparallel
applica-tion IIO stimuli. Because PFSs mediateapplication
I/O stimuli andphysical
I/O responses,developing
appropri-ate
designs
for scalableparallel
I/Osystems
requires
adetailed characterization of the I/O behavior at
multiple
system
levels(Gibson,
Vitter,
andWilkes,
1996).
To correlate
parallel application
I/O stimuli with disksystem
responses, weaugmented
ourportable application
IIO instrumentation infrastructure
(Reed,
Elford,
Mad-hyastha,
Scullin,
etal.,
1996)
with disk device driverinstrumentation. Built atop the Pablo
performance
analy-sistoolkit,
the former cancapture
both statisticalsumma-ries and
time-stamped
traces ofapplication
I/Opatterns.
In turn, our device driver instrumentation creates
temporal
summaries andactivity histograms
for selected SCSIde-vices,
including
read/writerequest sizes,
device driverdelays,
SCSI device servicetime,
responsetimes,
and queuelengths.
Using
thisexperimental
infrastructure,
wehave studied
logical
andphysical
If0patterns
for three diskconfigurations
of the IntelParagonTll’
XP/S and the IntelPFS,
one of the few extant commercial PFSs nowavailable.
The remainder of this paper is
organized
as follows. InSection
2,
we outline related work inparallel
I/Ocharac-terization and disk
modeling.
We then describe ourlogical
(application)
andphysical
(disk)
I/O characterizationmethodology
in Section 3. As a baseline foranalysis
ofsummarizes
logical
andphysical
I/O characteristics for a set ofsimple
benchmarks. This is followed in Section 5by
adescription
of MESSKIT(High
PerformanceCom-putational
Chemistry
Group,
1995),
alarge, multiphase
quantum
chemistry
code withdemanding
IIOrequire-ments that are
representative
of currentparallel
scientificapplications.
In Sections 6 and7,
weanalyze
thelogical
and
physical
I/Opatterns
for MESSKIT when executedon three different hardware
configurations.
Finally,
Sec-tions 8 and 9 summarize ourfindings
and outlinedirec-tions for future work.
2 Related Work
Although
ourunderstanding
of I/Oparallelism
is stillevolving,
there is along history
of file accesscharac-terization for mainframes and vector
supercomputers.
Notable
examples
includeLawrie, Randal,
and Barton’s(1982)
study
of automatic filemigration algorithms,
Strit-ter’s(1977)
analysis
of file lifetimedistributions,
Smith’s( 1981 ) study
of mainframe file accessbehavior,
and Jen-sen and Reed’s(1993)
study
of file archive accesses.More
recently,
Miller and Katz(1991)
captured
de-tailed traces ofapplication
file accesses from a suite ofCray
applications, identifying compulsory, checkpoint,
and
staging
I/O.Pasquale
andPolyzos
(1993, 1994)
fol-lowed with two additional studies of vector
workloads,
concluding
that most I/O hadregular
behavior.In the
parallel
domain,
Kotz andcolleagues
(Kotz
andNieuwejaar,
1994;
Purakayastha
etal., 1995)
usedlibrary
instrumentation to
study
I/Opatterns
on the InteliPSC/860 and the
Thinking
Machines CM-5.They
ob-served thatparallel
I/Opatterns
were morecomplex
thanexpected,
with smallrequests
quite
common.Complementary
studies ofphysical
I/Opatterns
have focused onmodeling
and simulation ofsingle
disks(Ruemmler
andWilkes,
1994)
andanalysis
of disk work-loads in UNIXsystems
(Ruemmler
andWilkes, 1993;
Baker,
1991).
This work showed that withouthigher
level file systemoptimizations,
the benefits from even the best diskscheduling algorithms
were limited(Seltzer,
Chen,
andOusterhout,
1990).
Our work differs from these earlier studies
by
examin-ing
the correlations betweenparallel
application
I/Ore-quests,
PFSpolicies,
andphysical
diskrequest
streams. This correlation is aprerequisite
tounderstanding
howPFSs mediate and transduce
logical
andphysical
request
streams and canprovide
a basis forintelligent design
ofmassively
PFSs.&dquo;Because PFSs mediate
application
I/O stimuli andphysical
I/O responses,developing
appropriate designs
for
scalableparallel
110systems
requires
a detailedcharacterization
of
the 110 behavior atmultiple
system
levels.&dquo;366
3
Experimental Methodology
Application
requests
are thelogical
stimuli to an UOsystem; their
sizes,
temporal spacing,
andspatial
patterns
(e.g.,
sequential
orrandom)
constrainpossible
library
andfile
system
optimizations (e.g., by prefetching
orcach-ing).
After mediationby
aPFS,
thephysical
patterns
ofI/O manifest at the
storage
devices are the ultimatesystem
response.To understand the
implications
ofapplication
requestpatterns
for PFSs and theefficacy
ofparallel
diskconfigu-rations,
we haveaugmented
the Pabloperformance
analy-sis environment’s
support
forapplication
I/Otracing
(Crandall
etal., 1996)
with SCSI device driver instrumen-tation on the IntelParagon
XP/Ssystem. Below,
wedescribe the
experimental
platform
and our measurement toolkit.3.1 EXPERIMENTAL PLATFORM
The distributed memory
Paragon
XP/S architecturecon-sists of a group of
compute
and UOnodes,
all connectedby
a two-dimensional mesh. These nodes execute adis-tributed version of OSF/1
AD,
withapplication
IIOre-quests
on thecompute
nodes sent to file servers on the I/O nodes. In turn, the I/O nodessupport
Intel’s PFS. The PFSstripes
files across the I/O nodes in 64-KBunits,
with the initial 64-KB filesegment
randomly placed
on one of the I/Onodes;
subsequent
64-KBstripes
are distributedusing
a round-robinalgorithm.
Together,
OSF/1 and the PFS I/O node file serverssupport both buffered and unbuffered
modes,
selectable via a system call for each file. Whenbuffering
isenabled,
PFS and OSF/I use a read-ahead and write-behind
cach-ing algorithm
with LRUreplacement
and 64-KB units.Finally,
if the last two consecutive disk reads havecon-tiguous
logical
blocknumbers,
one morelogical
file blockis
prefetched
asynchronously.
By
default,
PFSbuffering
isdisabled,
and atechnique
called fast
path
I/O is used to avoid datacaching
andcopying.
In this case, I/O node buffer caches and client side memorymapped
filesupport
arebypassed,
and dataare transferred
directly
between disks and user buffers.All our
experiments
were conducted on the 512-nodeIntel
Paragon
XP/S at the Center for AdvancedComput-ing
Research at the California Institute ofTechnology
(Caltech)
and used OSF/I version R1.4.1. As amajor
testplatform
for the Scalable I/O Initiative(Pool, 1996),
thissystem
supports
multiple
I/Oconfigurations,
eachdiffer-ing
in the number of IIO nodes and both number andtype
of disks.In our
experiments,
we considered two disktypes
andthree different numbers of I/O
nodes,
each with either asingle
attached SCSI disk or asingle
RAID-3 disk array.Disk hardware parameters for each I/O node
configura-tion are
given
in Table 1. Thestripe
group is the number of disks on which the files arestriped
for each I/Ohard-ware
configuration,
and thestripe
size is the amount of data stored on each disk beforemoving
to the next disk.Although
the two disk types differ inlogical
disk blocksize,
the basic unit of storage on thedisk,
C~SFI1 treats thedifferent disks
identically;
italways
transfers data inmul-tiples
of asingle
sector(i.e.,
multiples
of 2KB)
inre-sponse to read or write
requests.
Varying
the number of I/O nodes allowed us to assessthe effects of IIO node
parallelism
on disk I/Opatterns
andapplication
I/O response times.Conversely, varying
thehardware characteristics of the disks allows us to under-stand the effects of disk
capabilities
on observed behavior.Although exploring
an evenlarger
set of hard-ware/softwareconfigurations
would bedesirable,
we were constrainedby
the fact that the Caltech IntelParagon
XP/S is in
production
use. In consequence, wholesalehardware
configuration
changes
(e.g., modifying
theplacement
and number ofdisks)
ormajor operating
sys-temchanges
were notpractical.
3.2 LOGICAL 110 INSTRUMENTATION
The Scalable IIO Initiative
(Pool, 1996)
is a broad-basedmultiagency
research groupworking
in concert withven-dors to
design
parallel
I/O APIs and file systems. Aspart
of the Scalable I/O Initiative’s I/O characterization
effort,
we have extended the Pablo
performance
environment(Reed
etal., 1993; Reed,
Elford,
Madhyastha,
Scullin,
etal., 1996)
tocapture
application
I/O behavior on avariety
of
single
processor andparallel
systems. The extended Pablo I/O toolkit wraps invocations of I/O routines with instrumentation calls that record theparameters
and dura-tion of each invocadura-tion.To minimize
potential
I/Operturbations
due toperfor-mance data
extraction,
the Pablo toolkitsupports
bothreal-time reduction of I/O
performance
data andcapture
of detailed event traces. These two
options
trade compu-tationperturbation
for I/Operturbation.
Extensive use of the Pablo toolkit forapplication
I/O characterization(Crandall
etal., 1996;
Smirni etal., 1996; Reed, Elford,
Madhyastha,
Scullin,
etal.,
1996)
has shown that the instrumentation overhead isnegligible
for mostapplica-tion codes.
3.3 PHYSICAL 110 INSTRUMENTATION
Device drivers define the interface between file
system
services and I/Odevices,
isolating
theidiosyncrasies
ofspecific
devices behind standard interfaces. Because allphysical
I/Orequests
transit the devicedrivers,
instru-menting
these device drivers allows one to capture andanalyze
thetemporal
andspatial
patterns
of all requestsgenerated by
a PFS.In most current
parallel
I/O systems,including
the IntelParagon
XP/S,
the disks are connected to the IIO nodes via standard SCSIcontrollers,
and SCSI device driversservice all
requests.
A SCSI disk appearsexternally
as alinear vector of addressable blocks. All
physical
charac-teristics
(i.e., cylinders,
tracks,
sectors, and badblocks)
are hidden
by
this virtual device interface.This
separation
oflogical
andphysical
viewssimpli-fies the device driver interface and allows the storage
device to
transparently optimize
requests. However,
ex-ternal
entities,
including
the devicedriver,
have little or noknowledge
of the datalayout
on thephysical
media;
the status of the on-board disk cache or
scheduling
algo-rithm ;
or theseek,
rotationallatency,
or transfer compo-nents of arequest
service time.Although
there areexperimental techniques
fordeter-mining
these features(Wilkes
etal.,
1995),
forsimplic-ity’s
sake we have restricted ouranalysis
to behavior observable at the SCSI device drivers. As a furthercom-promise
between detail andoverhead,
we haveopted
togenerate
activity histograms
that summarize read andwrite
request sizes,
device driverdelays,
device servicetimes, request
runlengths,
driver and device queuelengths,
and interarrival times.To generate these
histograms,
we have modified theSCSI disk driver read/write routines
(Forin, Golub,
andBershad,
1991)
to time stamp eachrequest
onarrival,
transmission to or
receipt
from thedevice,
anddeparture.
Using
these time stamps, we thencompute
the time eachrequest spent
queued
for service at the devicedriver,
the timespent
on thedevice,
and the total response time(i.e.,
the sum of
queuing
and servicedelay).
This and other dataare
kept
in a kernel data structure associated with each SCSI device.Figure
1 illustrates thehigh-level
structure of there-sulting
SCSI device driver instrumentation. On the Para-gonXP/S,
processors in the servicepartition provide
general operating
system services,
and the externalinter-face to the users. Parallel
applications
are executed on theprocessors in the
compute
partition.
I/O nodes differ fromTable 1
SCSI Disk
Configurations (Intel Paragon XP/S)
Table 2
Benchmark
Logical/Physical
1/0Comparison (Intel Paragon XPIS)
NOTE: Request size = 80 KB,
interrequest
time = 1000 ms, file type = private,requests/processor
= 130, number of processors = 64,access pattern = sequential.
other
compute
nodesby having
an SCSI interface and anSCSI disk.
’
During application
programexecution,
an external user programexecuting
on a service node canconfigure,
reset, and retrieve the
physical
IIO data via an extended set of ioctl () calls. Whensynchronized
withapplica-tion
instrumentation,
thisperiodic histogram
extractionprovides
the data needed to correlatelogical
andphysical
request patterns.
4
Physical
1/0
BenchmarksAs a basis for
understanding
the morecomplex
I/Opat-terns found in
parallel applications
(e.g.,
thequantum
chemistry
code described in Section5),
we first measuredthe
logical
andphysical
I/O behavior of a suite ofbench-marks. Via these
configurable
benchmarks,
one canspec-ify
request types
andsizes,
interrequest
latencies,
paral-lelism,
filesharing,
and PFSbuffering.
Table 2 summarizes the
logical
andphysical
I/O attri-butes of two such benchmarks where every processorsequentially
reads or writes 80-KB units to or from aprivate
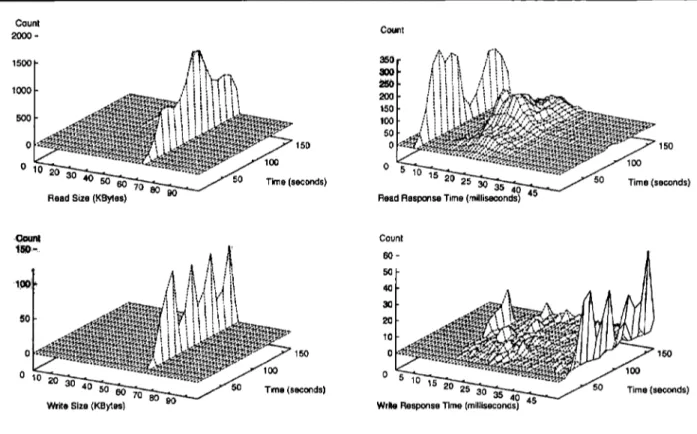
file.’ In turn,Figures
2 and 3 illustrate thetemporal
patterns
ofphysical
I/O for file read benchmark. Thehistograms
inFigures
2 and 3 arecaptured
andplotted
with 10-s
intervals,
whileFigures
4through
6 areplotted
369
Fig.
2 Read benchmarkphysical
)/0histograms
(64Seagate
disks withoutbuffering)
Several
striking
attributes areimmediately
apparentfrom the table and
figures.
First,
both the number ofphysical operations
and the total data volume differmark-edly
from thatrequested
at theapplication
level. For the writebenchmark,
PFS notonly
mustupdate
the file metadata as file blocks arewritten,
it must also write the file system metadata to reflect the creation of new files.When a processor creates a new
file,
otherexperiments
(not
displayed
here due to spacelimitations)
have shown that PFS must write two 64-KB blocks of metadata oneach disk across which the file will be
striped
Hence,
thephysical
data volume of Table 2 rises with the number of disks(e.g.,
when 64 processors create a file that isstriped
across 64disks,
over 512 MB of metadata must be written before anyapplication
data arestored).
Although
this metadata overhead ispartially
an artifactof the interactions between PFS and
OSF/1,
ithighlights
the often hidden costs ofscaling
workstation file systemsto hundreds or thousands of disks. The UNIX inode scheme was
originally
developed
toefficiently
support
&dquo;... both the number
of physical operations
and the total data volumediffer markedly from
thatrequested
at theapplication
level.&dquo;370
Fig. 3 Read benchmark physical IIO histograms (64 Seagate disks with buffering)
small files and
dynamic growth.
In contrast, files associ-ated with scientificapplications
are both very small andvery
large.
As others have alsonoted,
thissuggests
that for thelatter,
extent-based allocation schemes couldin-crease
physical contiguity
onstorage
devices and reducemetadata
manipulation
costs.Table 2 and
Figures
2 and 3 also show that thefile-buffering
policy
hasprofound
effects onphysical
request
sizes and response times for both reads and writes. With the default PFS
policy
(no
buffering), satisfying
sequen-tial 80-KBapplication
read or writerequests
requires
reading
from orwriting
data to two diskstripes. Although
buffering
and write-behind ameliorate thisoverhead,
they
incur additional memory costs-a more flexible file sys-tem would match the size andplacement
of the diskstripes
to therequest
size and accesspattern.
Turning
to the readbenchmark,
bothFigures
2 and 3 illustrate the effects of SCSI commandqueuing
and tracksatisfied from the track
buffers,
whereas others see the fullseek, rotation,
and transfer latencies.Figure
2 shows that allmultiples
of 16 KB are retrieved tosatisfy
unbuffered readrequests.
Again,
this reflects the mismatch betweenrequest
size andstriping
factor. Asuccession of 80-KB
requests
requires
16-, 32-,
and 48-KBportions
of the 64-KBstripes.
With similar bench-marksusing
16-KBrequest sizes,
we observe that theapplication
andphysical
request
counts and volumes wereidentical for unbuffered I/O.
With
buffering
enabled,
PFS and OSF/1sequentially
prefetch
data in 64-KB units for filereads,
yielding
thesingle physical
request
size ofFigure
3. This reduces the number of actualphysical
reads but increases the total I/Ovolume,
as Table 2 illustrates.However,
Figure
3 shows that even with a readinterrequest
interval of 1 s, theprefetching algorithm
is unable to retrieve all data beforethey
arerequested.
In turn, this results in the response timespike
at thetop
ofFigure
3.Third,
as Table 2 andFigures
2 and 3show,
the readbenchmark
generates
a nontrivial number ofphysical
writes. For
reads,
these writes accrue from metadatapro-cessing
to record last access times for file blocks.Every
30 s, all I/O nodes write this data to their disks.
By
their nature, these filesynchronizations
arebursty,
resulting
inlarge
disk response times.Moreover,
comparison
ofFig-ures 2 and 3 shows that the interaction between
prefetch-ing
and filesynchronization adversely
affects both.Although
read and write benchmarkshighlight
manypossible
interactions between accesspatterns,
filesystem
policies,
and hardwareconfigurations,
their resource de-mands often aresimpler
and moreregular
than those inrealistic
applications.
Hence,
we turn now to ananalysis
of a
large,
I/O intensiveparallel application.
5
Quantum
Chemistry
CodeAs noted
earlier,
one of theprimary
goals
of the ScalableIIO Initiative is
analyzing
the I/Opatterns present
in alarge
suite of scientific andengineering
codes. These spana broad range of
disciplines
and have been thesubject
of severalapplication
characterization studies(Crandall
etal.,
1996;
Smimi etal., 1996; Reed,
Elford,
Madhyastha,
Scullin,
etal.,
1996).
As an initial basis for
integrated
analysis
ofapplication
and
physical
I/Oanalysis,
we selected one code(MESSKIT)
from the Scalable I/O Initiative suite. This code has been thesubject
of earlierapplication
analysis
(Crandall
etal., 1996)
and isrepresentative
of the IIOpatterns
observed inparallel
scientificapplications.
Assuch,
itprovides
a baseline forcomparison
oflogical
andphysical
I/Opatterns.
MESSKIT is a Fortran
implementation
of theHartree-Fock self-consistent field method
(High
PerformanceComputational Chemistry Group,
1995)
thatcomputes
the electron
density
around a moleculeby
considering
each electron in the molecule in the collective field of the others. The
implementation
uses basis sets derived from the atoms and the relativegeometry
of the atomic centers. Atomicintegrals
are then calculated over these basisfunctions and are used to
approximate
moleculardensity.
A Fock matrix is derivedusing
molecular densities and the atomicintegrals.
Finally,
a self-consistent fieldmethod is used until the molecular
density
converges to within anacceptable
threshold. Because a Fock matrix ofsize N generates
O(N2)
one-electron andO(1V4)
two-electronintegrals,
the total I/O demand for realisticproblems
isbeyond
what can befeasibly supported
with currentpar-allel I/O
systems.
The MESSKIT code consists of three distinct
pro-grams that
operate
as alogical
pipeline,
with each stageaccepting input
from theprevious
one.~ psetup: The processors read the initial
files,
transformthe data in ways needed
by
the laterphases,
and write the result to disk.~ pargos: Each processor
locally
calculates and writes to diskintegrals
that involve either one or two electrons.~
pscf-.
Finally,
each processorrepeatedly
reads its pri-vateintegral
files to retrieve the necessaryquadrature
data and solves the self-consistent field
equations.
The results areperiodically
collected and written to diskby
processor zero.Although
both the pargos andpscf phases
are 1/0inten-sive,
forbrevity’s
sake,
we consideronly
theinput
inten-sive
pscf phase
below.6
Logical
110
PatternsTable 3 shows the I/O behavior of MESSKIT’s
pscf phase,
as
captured
using
ourapplication
I/O characterizationsoftware The data were obtained
by executing
the code on 64 processors and different hardwareconfigurations,
all
using
a small 16-atom testproblem
and the Intel PFS M_UNIX file accessmode,
a direct extension of standardUNIX file system semantics.4 4
Table 3 shows that even for this small test
problem,
thepscf phase requires
over50,000
accesses tosecondary
372
Table 3
psct Logical
If 0Summary (64 processors)
Fig. 4
pscf logical VOhistograms
(64disks)
RAIl7-3 disk array, these accesses consume
nearly
40% of all executiontime,
although
this decreases tonearly
10% with alarger
number of faster disks.In addition to
input
costs, Table 3 also illustrates thehigh
cost of file open andclose;
each file open averagesroughly
0.3 s per processor. As described in Section4,
these costs arise from PFS metadatamanipulation.
Inprinciple,
one couldpreallocate
space for theoutput files,
a method used
by
many databasesystems
to reduce metadatamanipulation
overhead.However,
for scientificapplications
likeMESSKIT,
the size of theoutput
files isstrongly dependent
on theinput
data,
and limited excessstorage
space is available forpreallocation.
As a basis for
comparison
withphysical
IIOhisto-grams,
Figure
4 shows ahistogram
ofapplication
read sizes and durations for the 64-diskconfiguration.
Clearly,
thepscf read
activity
isbursty,
with sixcycles
visible in373
Table 4
pscf Logical/Physical
1/0Comparison (64 processors)
Figure
4. Most readrequest
sizes are near 80KB,
although
a few are near 200 KB. As a consequence ofrequest
burstiness,
theapplication
read durations arehighly
vari-able-PFS makes noattempt
to minimize readlatency by
aggressively prefetching during
compute
intensive intervals.7
Physical
1/0
PatternsUsing
the SCSI device driver instrumentation described in Section3,
we measured thephysical
I/O characteristicsfor the MESSKIT code
phases
on each of our three SCSIdisk
configurations.
Table 4 summarizes these measure-ments for thepsef phase.
When PFS
buffering
isdisabled,
thephysical
read datavolume
roughly equals
thelogical
datavolume,
although
the number ofphysical
requests
exceeds the number oflogical
requests
by
a factor of four. Withbuffering,
thedata volume for
physical
reads increasessubstantially,
but the total number ofphysical
requests declines,
reflecting
the fact thatprefetching
retrieves a smaller number oflarger
64-KBstripes.
As with the benchmarks of Section4,
the
majority
of the write traffic is attributable to metadataupdates.
As a
complement
to thelogical
accesshistograms
ofFigure
4,
Figure
5 illustrates thetemporal
distribution ofphysical
request
sizes and durations for thepscf
phase
with PFS filebuffering
disabled. Thelogical
andphysical
access
patterns
arequite
similar,
although
the 80-KBMore
striking
is the effect ofchanging
hardware attri-butes on the distribution ofphysical
request
responsetimes. The SCSI standard
supports
multiple outstanding
requests
through
a mechanism called commandqueuing.
Using
thismechanism,
a disk controller can resequencerequests
based on internal state to minimizerequest
re-sponse times. The older RAID-3 disk arrays of Table 1 do
not
support
commandqueuing,
but the newerSeagate
disksdo.
In
Figure
5,
with 64Seagate
disks,
the I/O system hasa sufficient
parallelism
to avoidlong queuing delays
at each disk.This,
together
with commandqueuing
and on-boardrequest
resequencing,
allows the disks tosatisfy
mostrequests
from the disk trackbuffers;
these are the response times below 5 ms inFigure
5. As the number of disks declines to16,
alarger
fraction of therequests
require
disk arm movement or encounterqueuing
delays.
Finally,
the12,
slower RAID-3 disks are saturatedduring
application
request
bursts and lack commandqueuing
toresequence
requests.
In consequence, mostphysical
re-quests
seelarge queuing delays.
7.1 QUEUING AND BLOCK RUNS
Although Figure
5 shows both the distribution ofphysical
request
sizes and thepernicious
effects of insufficient hardwareparallelism,
it reveals little about thelocality
ofphysical
requests
or the sizes of disk queues.Using
ourSCSI driver
instrumentation,
we alsocaptured
SCSI block runlengths (i.e.,
the number of consecutive blocksac-cessed on each
disk)
and the distribution of queue sizes.An
analysis
of these data shows that theproduct
of the block runlength
and block sizegenerally
equals
the sizeof the
physical
requests.
This means that there is little or nolocality
across successivephysical
readrequests,
eventhough
thehigh-level
fileoperations
are almost allse-quential
reads in the MESS KIT code.PFS file
striping
distributes all files across all available disks in the filesystem.
Whenmultiple
processes contendfor access on a
single
disk,
successive accesses to that disk have littlelocality. Simply
put,
the disks seenonsequential
requests,
necessitating
disk arm movements andincreas-ing
access times.Turning
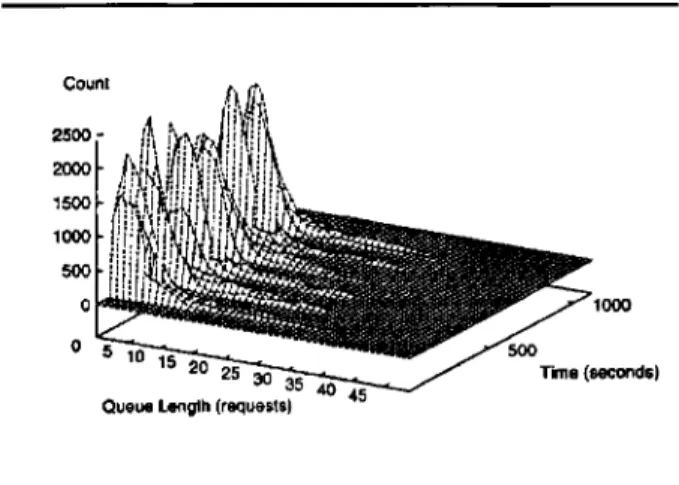
to device queuelengths, Figure
6 illustrates thetemporal
distribution of queue sizes for the 12RAID,
3 disk arrays. As
expected
from thehigh
response timesof
Figure
5,
these disks areoperating
insaturation,
withqueue
lengths exceeding
40requests
during periods
ofFig.
6pscf
driver queue (12 RAIDs)&dquo;When
multiples
processescontend for
access on asingle
disk,
successive accesses to that disk have littlelocality.
Simply
put,
the disks seenonsequential
requests,
necessitating
disk arm movements andincreasing
access times.&dquo;Fig. 7 pscf disk request distributions (64 Seagate disks)
high activity.
Even the 16- and 64-diskconfigurations
seemaximum queue
lengths
of 10 and20,
respectively.
7.2 DISK LOAD DISTRIBUTIONSAs noted
earlier,
Intel’s PFSstripes
file data in 64-KBunits,
beginning
with arandomly
selected I/O node. Forlarge sequential
file accesses like those inMESSKIT,
onewould
expect
this dataplacement
to distribute the number ofphysical
requests
nearly equally
across the UO nodesand disks.
Surprisingly,
this is not the case for thepscf
phase.
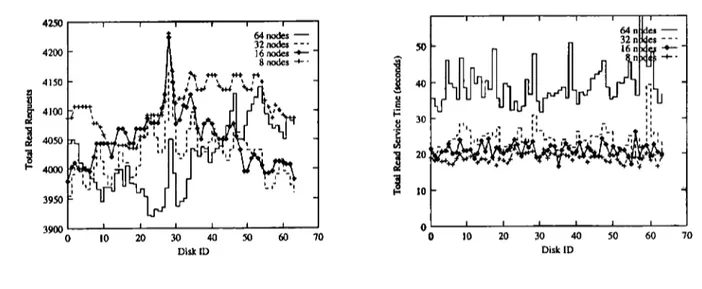
Figure
7 shows both the number ofrequests
and the total read service time for each disk in the 64-diskcon-figuration
as a function ofapplication
parallelism.
Whenthe number of
application
processors is nolarger
than thenumber of
disks,
read time islargely
independent
ofapplication parallelism
levels.However,
when the number ofcontending
processorsequals
or exceeds the number ofdisks,
the total service time increasessubstantially.
Counterintuitively,
smaller numbersof processors
gen-erate
larger
numbers ofrequests,
eventhough
the totalapplication
IIO volume inpscf
isindependent
of the number of processors.This,
together
with the lack ofphysical
locality
described in Section7.1, suggests
that there are substantialopportunities
forperformance
377
8 Discussion and
Implications
Based on our
comparison
ofapplication
I/O stimuli withphysical
I/Osystem
responses on the IntelParagon
XP/S,
several
implications
for bothperformance
measurementtoolkits and
next-generation
PFSs are clear.First,
SCSI device driver instrumentation and metrichistograms
strike theright
balance between the limited detail pro-videdby simple
counts and the excessive overhead fromtracing
physical
I/O within device drivers.In our
experience, histogramming
is efficient andpro-vides a wealth of
time-varying
detail on requestsizes,
device driver service
times, request
runlengths,
driver anddevice queue
lengths,
and interarrival times. Whencom-plemented by
user-level measurement ofapplication
IIOpatterns,
one cananalyze
the interactions ofapplication
requests,
PFSpolicies,
and diskparallelism.
Second,
maintaining
metadata is amajor
overhead for filesystems
thatnaively
retain UNIX file systemseman-tics. Current
teraflop
systems
arebeing configured
withthousands of
disks,
andproposed petaflop
systems would havenearly
100,000
disks.Straightforward extrapolation
ofPFS-style
metadatastorage
for suchsystems
would entailwriting gigabytes
of metadatajust
to create a file.Alternative
representations
(e.g.,
extent-basedstorage)
are needed that are more amenable to file
striping
whileretaining
fault tolerance.Third,
both our benchmarks and the MESSKITchem-istry
code illustrated the limitations of asingle
diskstripe
size and distribution
policy.
Whenapplication
requests
are not a naturalmultiple
of thestripe
size,
either becausethey
are much smaller or muchlarger,
the number and volumeof
physical
If0 can differmarkedly
from thatspecified by
the
application.
Thismismatch,
together
with the demon-strableoverheads, suggests
thatnext-generation
file sys-tems mustsupport
flexiblestorage
formats that candy-namically
select astripe
size and a distribution ofstripes
across disks.
As a
complement
to more flexible datadistributions,
file
system
policies
mustaggressively exploit application
accesspatterns.
Intel PFS and OSF/1 includesimple
read-ahead and write-behindpolicies
with LRU cachereplace-ment. For the MESSKIT
application,
thesepolicies
frag-mentapplication
requests, generate unnecessary diskac-tivity,
and fail toexploit bursty
behavior toaggressively
prefetch
dataduring
idleperiods.
Forexample,
we ob-served that the combination of PFSpolicies
and data distributions across disks eliminated almost all accesslocality
present in theapplication
pattern.
Automatic ac-cesspattern
classification(Madhyastha
andReed,
1996),
&dquo;SCSI device driver instrumentation and metric
histograms
strike theright
balance between the limiteddetait provided by simple
counts and the excessiveoveritead from
tracing physical
110 within device drivers.&dquo;&dquo;Automatic access
pattern
classification,
coupled
with
performance-directed adaptive control for
policy
selection,
coulddynamically
tailorpolicies
to accesspatterns.&dquo;
coupled
withperformance-directed
adaptive
control forpolicy
selection(Reed, Elford,
Madhyastha,
Smirni,
etal., 1996),
coulddynamically
tailorpolicies
to accesspatterns.
Fourth,
despite
thetemptation
to sacrifice I/O systemsfor additional processors or
primary
memory,high
perfor-mance
parallel
systems can realize theirpotential
only
when balanced. For the MESSKIT
application,
we sawthat a 4:
1 processor-to-disk
ratio was insufficient to maxi-mizeperformance.
Although
Amdahl’ssuggestion
that anMIPS of
computing
must be balancedby
amegabyte
ofmemory and a
megabyte
per second of I/O may not hold formassively parallel
systems,
thepremise
ofsystem
balance remains true. Ourexperiments
suggest
that the number of disks inparallel
I/Osystems
must be within asmall constant factor of the number of processors for
many scientific
applications.5
5Finally,
characterization studies areby
their natureinductive,
covering only
a smallsample
of thepossibili-ties and
attempting
to extract moregeneral
patterns.
Al-though
the benchmarks and MESSKITchemistry
appli-cation we studied on the IntelParagon
XP/S are but a fewsamples
from alarge
space ofpossible
I/Opatterns,
earlierapplication
characterization studies(Crandall
etal.,1996;
Smimi and
Reed, 1996, 1997; Reed, Elford,
Madhyastha,
Scullin,
etal., 1996;
Purakayastha
etal.,
1995) suggest
that our selections arerepresentative
of currentpractice.
Although
a wider range ofexperiments
isdesirable,
thelevel of instrumentation and
experiments
we conductedrequired
access to theoperating
system
code andsingle-user time to load
experimental operating
system kernels. This restricted ourability
to conductcomparative
experi-ments onmultiple platforms.
Acomplete
exploration
willrequire analysis
of additionalapplications,
hardwareplat-forms,
and PFSs.9 Conclusions and Futures
We have examined the interactions of
application
I/Orequests,
PFSpolicies,
and disk hardwareconfigurations
using
bothapplication
IIO measurements and SCSI device driver instrumentation. Thisanalysis
suggests
that thephysical
I/Opatterns
inducedby application
requests arestrongly
affectedby data-striping
mechanisms,
file sys-tempolicies,
and disk hardware attributes.Simply
put,
nosingle
filepolicy
or data distribution isoptimal
for allapplication
accesspatterns.
Based on this
analysis,
we areexploring
three379
classification based on trained neural networks and hid-den Markov models
(Madhyastha
andReed,
1996),
flex-iblepolicy
selectionusing fuzzy
logic
techniques
(Reed,
Elford,
Madhyastha,
Smirni,
etal.,
1996),
andadaptive
storage formats based on redundant
representations.
ACKNOWLEDGMENTS
We thank
Evgenia
Smirni,
Christopher
Elford,
TaraMad-hyastha,
and RuthAydt
for theirinsights
onparallel
Il0and instrumentation. We also thank Rick Kendall of the Molecular Science Software
Group
at the MolecularSci-ence Research
Center,
Pacific Northwest NationalLabo-ratory,
for the MESSKIT code. All datapresented
herewere obtained from code executions at the Caltech Center for Advanced
Computing
Research. This work wassup-ported
inpart
by
the Defense Advanced ResearchProjects
Agency
under DARPA Contracts DABT63-94-C0049(Scalable
I/OInitiative),
DAVT63-91-C-0029,
andDABT63-93-C0040,
by
the National Science Foundation under Grant NSF ASC92-12369,
by a joint
GrandChal-lenge
grant
withCaltech,
andby
the National Aeronautics andSpace
Administration under NASA Contract NAG-1-613.BIOGRAPHIES
Huseyin
Simitci is a doctoral candidate in computer science at theUniversity
of Illinois atUrbana-Champaign.
His research interests includeparallel
file systems,high performance
com-puting,
andintelligent
software. He obtained an M.S. and a B.S. from BilkentUniversity,
Ankara,Turkey,
in 1994 and 1992,respectively.
He is a member of the Pablo ResearchGroup.
Daniel A. Reed is a
professor
and head of theDepartment
ofComputer
Science at theUniversity
of Illinois atUrbana-Champaign.
In addition, he holdsa joint appointment
as a senior research scientist with the National Center forSupercomputing
Applications.
He received a B.S. in computer science from theUniversity
of Missouri at Rolla in 1978 and an M.S. and Ph.D., also in computer science, from PurdueUniversity
in 1980 and1983,
respectively.
He was arecipient
of the 1987 NationalScience Foundation Presidential
Young Investigator
Award.NOTES
1. As a basis for comparison, this combination of request size and
access pattern was chosen to match the application access pattern in Section 5.
2. Traces showed that in most cases there are two block writes per
stripe file, but occasionally the number of blocks is one or three; thus, the small variations in the metafile volume occur.
3. In Table 3, the I/O time column is the sum of all time spent performing I/O across all processors.
4. The PFS M_ASYNC mode, which does not preserve file access
atomicity when files are concurrently opened by multiple processes, is a
potentially lower overhead altemative to the M_UNIX mode. However, in the MESSKIT code, each file is accessed by a single processor.
5. Clearly, for some application domains this is not the case.
REFERENCES
Baker, M. G. 1991. Measurements of a distributed file system.
Proceedings of
the ThirteenthSymposium
onOperating
System Principles
25. Association forComputing
Machin-ery,pp. 198-212.
Crandall, P.,
Aydt,
R. A., Chien, A. A., and Reed, D. A. 1996.I/O characterization of scalable
parallel applications.
InPro-ceedings of Supercomputing
1995, SanDiego.
Forin, A., Golub, D., and Bershad, B. 1991. An I/O system for
Mach 3.0. In
Proceedings of the
USENIX MachSymposium,
USENIX, pp. 163-176.Gibson, G. A., Vitter, J. S., and Wilkes, J. 1996.
Strategic
directions incomputing
research:Working
group on storage I/O issues inlarge-scale computing.
ACMComputing
Sur-veys 28(4): 779-793.High
PerformanceComputational Chemistry Group.
1995. NWChem, acomputational chemistry package
forparallel
computers, version 1.1. Available at Pacific Northwest Na-tionalLaboratory,
Richland, WA, 99352, U.S.A..Jensen, D. W., and Reed, D. A. 1993. File archive
activity
in asupercomputing
environment. InProceedings of
the 1993 ACM InternationalConference
onSupercomputing, July.
Kotz, D., and
Nieuwejaar,
N. 1994.Dynamic
file-access char-acteristics of aproduction parallel
scientific workload. InProceedings of Supercomputing
’94, Los Alamitos,Novem-ber, pp. 640-649.
Lawrie, D. H., Randal, J. M., and Barton, R. R. 1982.
Experi-ments with automatic file
migration.
IEEEComputer, July,
pp. 45-55.
Madhyastha,
T., and Reed, D. A. 1996.Intelligent, adaptive
filesystem
policy
selection. InProceedings of
Frontiers ’96, October, 172-179.Miller, E. L., and Katz, R. H. 1991. I/O behavior of supercom-puter
applications.
InProceedings of Supercomputing
’91,November, pp. 567-576.
Pasquale,
B. K., andPolyzos,
G. A. 1993, Staticanalysis
of I/Ocharacteristics of scientific
applications
in aproduction
workload. InProceedings of Supercomputing
’93, Portland, November, pp. 388-397.Pasquale,
B. K., andPolyzos,
G. C. 1994.Dynamic
I/Ocharac-terization of I/O intensive scientific
applications.
InProceed-ings of Supercomputing
’94,Washington,
DC, November,pp. 660-669.
Pool, J. T. 1996. Scalable I/O Initiative. California Institute of
Technology.
Available athttp://www.ccsf.caltech.edulSIO/
Purakayastha,
A., Ellis, C. S., Kotz, D.,Nieuwejaar,
N., and Best,M. 1995.
Characterizing parallel
file access patterns on alarge-scale
multiprocessor.
InProceedings of the
Ninth International ParallelProcessing Symposium, April,
pp. 165-172.Reed, D. A.,
Aydt,
R. A., Noe, R. J., Roth, P. C., Shields, K. A., Schwartz, B. W., and Tavera, L. F. 1993. Scalableperfor-mance
analysis:
The Pabloperformance analysis
environ-ment. In
Proceedings of
the Scalable Parallel LibrariesConference,
editedby
A.Skjellum.
Los Alamitos, CA: IEEEComputer Society
Press, 1993, pp. 104-113.Reed, D. A., Elford, C. L.,
Madhyastha,
T., Scullin, W. H.,Aydt,
R. A., and Smimi, E. 1996. I/O,
performance analysis,
andperformance
data immersion. InProceedings of MASCOTS
’96, San Jose,February,
pp. 1-12.Reed, D. A., Elford, C. L.,
Madhyastha,
T., Smirni, E., and Lamm, S. L. 1996. The next frontier: Interactive and closedloop
performance steering.
InProceedings of the
1996Inter-national
Conference
on ParallelProcessing
Workshop,
Bloomington, August,
pp. 20-31.Ruemmler, C., and Wilkes, J. 1993. UNIX disk access patterns. In
Proceedings of
the Winter 1993 USENIXConference,
USENIX, pp. 405-420.
Ruemmler, C., and Wilkes, J.1994. An introduction to disk drive
modeling. Computer
27(3):17-28.Seltzer, M., Chen, P., and Ousterhout, J. 1990. Disk
scheduling
revisited. In
Proceedings of the
Winter 1990 USENIXCon-ference, January,
USENIX, pp. 313-324.Smimi, E.,
Aydt,
R. A., Chien, A. A., and Reed, D. A. 1996. I/Orequirements
of scientificapplications:
Anevolutionary
view.High Performance
DistributedComputing,
pp. 49-59. Smirni, E.,Aydt,
R. A., Chien, A. A., and Reed, D. A. 1996. I/Orequirements
of scientificapplications:
Anevolutionary
view. InProceedings of the Fifth
IEEE InternationalSympo-sium on
High-Performance
DistributedComputing, August,
pp. 49-59.
Smirni, E., and Reed, D. A. 1997. Workload characterization of I/O intensive
parallel applications.
InProceedings of the
9th InternationalConference
onModelling Techniques
andTools for Computer Performance
Evaluation, June.Smith, A. J. 1981.
Analysis of long
term file reference patternsfor
application
to filemigration algorithms.
IEEE Transac-tions onSoftware Engineering
SE-7 4:403-417.Stritter, T. R. 1977. File
migration.
Ph.D. thesis,Department
ofComputer
Science, StanfordUniversity.
Wilkes, J.,